文本生成图像工作简述2--常用数据集分析与汇总
文本到图像的 AI 模型仅根据简单的文字输入就可以生成图像。用户可以输入他们喜欢的任何文字提示——比如,“一只可爱的柯基犬住在一个用寿司做的房子里”——然后,人工智能就像施了魔法一样,会产生相应的图像。
文本生成图像(text-to-image)可以根据给定文本生成符合描述的真实图像,其是多模态机器学习的任务之一,具有巨大的应用潜力,如视觉推理、图像编辑、视频游戏、动画制作和计算机辅助设计。
本篇将简述文本生成图像的数据集,汇总介绍数据集的内容、特点、细节和下载方式等。
一、Caltech-UCSD Bird(CUB-200-2011)
1.1、介绍
CUB-200-2011数据集是CUB-200-2011是CUB-200的扩展版本,这是一个具有挑战性的200种鸟类数据集。扩展版本大致将每个类别的图像数量增加了一倍,并添加了新的零件定位注释。所有图像都使用边界框、零件位置和属性标签进行注释。图像和注释由Mechanical Turk的多个用户过滤。
鸟类物种分类是一个难题,它突破了人类和计算机视觉能力的极限。尽管鸟类拥有相同的基本部分,但不同的鸟类在形状和外观上可能会有很大的差异,而且,由于照明和背景的变化以及姿势的极端变化(例如,飞鸟、游泳鸟和栖息在树枝上的鸟类),鸟图像的类内差异也很大。

1.2、细节
1️⃣数据量:数据集包含200种鸟类的11788张图像,其中训练数据集有5994张图像,测试集有5794张图像。
2️⃣种类:每个物种都与维基百科相关,并按照科学分类(目、科、属、种)进行组织。物种名称列表是使用在线野外指南获得的,使用Flickr图像搜索获取图像,然后通过向多个Mechanical Turk用户展示每个图像进行过滤。
3️⃣数据信息:每张图像均提供了图像类标记信息,每个图像都带有边界框(bounding box)、关键part位置信息,以及属性信息。每张图片的注释:15 个关键部位信息、312 个二进制属性、1 个边界框。
1.3、下载
1️⃣论文链接:The Caltech-UCSD Birds-200-2011 Dataset
2️⃣官方网站:http://www.vision.caltech.edu/datasets/cub_200_2011/
3️⃣图像下载:谷歌云盘链接
4️⃣文本下载:谷歌云盘链接
数据集包括:bounding_boxes.txt;classes.txt;image_class_labels.txt; images.txt; train_test_split.txt.
其中:
bounding_boxes.txt为图像中鸟类的边界框信息;
classes.txt为鸟类的类别信息,共有200类;
image_class_labels.txt为图像标签和所属类别标签信息;
images.txt为图像的标签和图像路径信息;
train_test_split.txt为训练集和测试集划分。

二、Oxford-102 Flower
2.1、介绍
Oxford-102 Flower是是牛津工程大学于2008年发布的用于图像分类的花卉数据集,选择的花通常在英国本土,详细信息和每个类别的图像数量可以在网站的类别统计页面上找到,如下:
分类花卉对自行车、汽车和猫等类别来说是一个额外的挑战,因为花内类别之间有很大的相似性,比如一朵花与另一朵花的区别有时是颜色,例如蓝色的钟形与向日葵,有时是形状,例如水仙花与蒲公英,有时是花瓣上的图案,例如三色堇与虎耳草等。
2.2、细节
1️⃣数据量:8189张图像组成的数据集,这些图像被划分为103个花卉类别,都是英国常见的花卉。数据集分为训练集、验证集和测试集,训练集和验证集各包含10个图像,测试集由剩余的6129张图像组成(每类至少20张)。
2️⃣种类:每个类包含40到250个图像,百香花的图像数量最多,桔梗、墨西哥紫菀、青藤、月兰、坎特伯雷钟和报春花的图像最少,即每类40个,图像被重新缩放,使最小尺寸为500像素。
2.3、下载
1️⃣论文链接:Automated flower classification over a large number of classes
2️⃣官方网站:https://www.robots.ox.ac.uk/~vgg/data/flowers/102/index.html
3️⃣图像下载:谷歌云盘链接
4️⃣文本下载:谷歌云盘链接

三、MS-COCO
3.1、介绍
MSCOCO数据集全称是Microsoft Common Objects in Context。其是微软开发维护的大型图像数据集,任务包括识别(recognition),分割(segementation),及检测(detection)。
COCO是一个具有非常高的行业地位且规模非常庞大的数据集,用于目标检测、分割、图像描述等等场景。特点包括:
- Object segmentation:对象级分割
- Recognition in context:上下文识别
- Superpixel stuff segmentation:超像素分割
- 330K images (>200K labeled):330万张图像(超过20万张已标注图像)
- 1.5 million object instances:150万个对象实例
- 80 object categories:80个目标类别
- 91 stuff categories:91个物体类别
- 5 captions per image:每张图片有5段描述
- 250,000 people with keypoints:250万个人体关键点标注
该数据集解决了场景理解中的三个核心研究问题:检测对象的非图标视图(或非规范视角)、对象之间的上下文推理和对象的精确二维定位。

3.2、细节
1️⃣数据量:MS COCO数据集共包含123287幅图像,包含80k张用于训练的图像和40k张用于测试的图像。其中每个图像包含5个句子注释。COCO的官方培训部分用于培训,COCO的正式验证部分用于测试。在训练的小批量选择期间,为其中一个字幕选择随机图像视图(例如裁剪、翻转)。
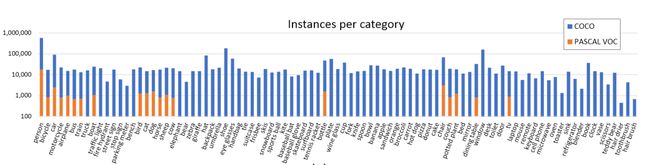
2️⃣种类:MS-COCO总共包含 91个类别,每个类别的图片数量如下:
3.3、下载
1️⃣论文链接:Microsoft COCO: Common Objects in Context
2️⃣官方网站:https://cocodataset.org/#overview
3️⃣图像下载:谷歌云盘链接
4️⃣文本下载:谷歌云盘链接
其中,
Train images:训练集,训练过程中使用到的图像
Val images:验证集,验证过程中使用到的图像
Test images:测试集,测试过程中使用到的图像(如果使用test数据集,那么可以把验证集合训练集一起用于训练),后续例子中没有下载使用
Train/Val annotations:训练集和验证集的标注文件,json格式
下载后,压缩到同一个文件夹中,以COCO2017为例,形成如下结构:
COCO_2017
├── val2017 # 验证集所在文件夹,包含5000张图像
├── train2017 # 训练集所在文件夹,包含118287张图像
├── annotations # 标注文件所在文件夹,包含如下文件
├── instances_train2017.json # 目标检测、分割任务的训练集标注文件
├── instances_val2017.json # 目标检测、分割任务的验证集标注文件文件
├── person_keypoints_train2017.json # 人体关键点检测的训练集标注文件
├── person_keypoints_val2017.json # 人体关键点检测的验证集标注文件
├── captions_train2017.json # 图像描述的训练集标注文件
├── captions_val2017.json # 图像描述的验证集标注文件
四、Multi-Modal-CelebA-HQ
4.1、介绍
Multi-Modal-CelebA-HQ是一个大规模人脸图像数据集。
Multi-Modal-CelebA-HQ可用于训练和评估文本到图像生成、文本引导图像处理、草图到图像生成、图像说明和 VQA 的算法。这个数据集是在TediGAN中提出并使用的。
文本描述是使用基于给定属性的概率上下文无关语法 (PCFG) 生成的,按照流行的CUB数据集和COCO数据集的格式为每个图像创建十个独特的单句描述以获得更多训练数据。
4.2、细节
1️⃣数据量:Multi-modal-CelebA-HQ数据集由CELEBA-HQ数据集和其相对应的文本描述组成,具有30,000个高分辨率人脸图像,每个图像都对应10个描述性文本,除此之外还包含语义分割图、草图和透明背景的图像。该数据集分为24,000张训练集和6000张测试集。
2️⃣数据信息:数据集与通用的文本生成非人脸数据集CUB和COCO数据集具有相同的数据格式。

4.3、下载
1️⃣论文链接:TediGAN: Text-Guided Diverse Face Image Generation and Manipulation
2️⃣官方网站:https://github.com/IIGROUP/MM-CelebA-HQ-Dataset
3️⃣图像下载:谷歌云盘链接
4️⃣文本下载:谷歌云盘链接

最后
上一篇:文本生成图像工作简述1–概念介绍和技术梳理
以上下载若有错误或失效,请及时反馈,另外,我们已经建立了T2I研学社群,如果你对Dreamfields和DreamFusion还有其他疑问或者对文本生成图像很感兴趣,可以私信我加入社群。
加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言