【Python 初学者】从零开始构建自己的神经网络
此图为使用神经网络预测猫狗案例。
原创:CSDN/知乎:川川菜鸟
文章目录
-
- 什么是神经网络?
- 训练神经网络
- 前向传播
- 损失函数
- 反向传播
- 完整应用
- 提问
- 结束语
什么是神经网络?
大多数神经网络的介绍性文本在描述它们时都会提出大脑类比。在不深入研究大脑类比的情况下,我发现将神经网络简单地描述为将给定输入映射到所需输出的数学函数会更容易。
神经网络由以下组件组成
- 输入层x
- 任意数量的隐藏层
- 一个输出层,ŷ
- 每层W 和 b之间的一组权重和偏差
- 每个隐藏层的激活函数选择 σ。在本教程中,我们将使用 Sigmoid 激活函数。
下图显示了 2 层神经网络的架构(请注意,在计算神经网络中的层数时,输入层通常被排除在外)
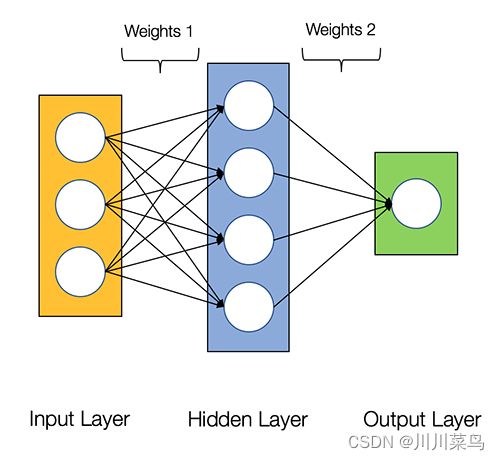
在 Python 中创建神经网络类很容易
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(y.shape)
训练神经网络
一个简单的 2 层神经网络的输出ŷ是:
![]()
可能会注意到,在上面的等式中,权重W和偏差b是影响输出ŷ 的唯一变量。自然地,权重和偏差的正确值决定了预测的强度。从输入数据微调权重和偏差的过程称为训练神经网络。
训练过程的每次迭代包括以下步骤:
- 计算预测输出ŷ,称为前馈
- 更新权重和偏差,称为反向传播
下面的时序图说明了这个过程

前向传播
正如我们在上面的时序图中看到的,前馈只是简单的微积分,对于一个基本的 2 层神经网络,神经网络的输出是:
![]()
让我们在我们的 python 代码中添加一个前馈函数来做到这一点。请注意,为简单起见,我们假设偏差为 0。
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
# 前向反馈
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
然而,我们仍然需要一种方法来评估我们预测的“优度”,损失函数使我们能够做到这一点。
损失函数
有许多可用的损失函数,我们问题的性质应该决定我们选择的损失函数。在本教程中,我们将使用一个简单的平方和误差作为我们的损失函数。

也就是说,平方和误差只是每个预测值与实际值之间的差值之和。差异被平方,以便我们测量差异的绝对值。
我们在训练中的目标是找到最小化损失函数的最佳权重和偏差集。
反向传播
现在我们已经测量了预测的误差(损失),我们需要找到一种方法将误差传播回去,并更新我们的权重和偏差。
为了知道调整权重和偏差的适当数量,我们需要知道损失函数相对于权重和偏差的导数。 回想一下微积分,函数的导数就是函数的斜率。
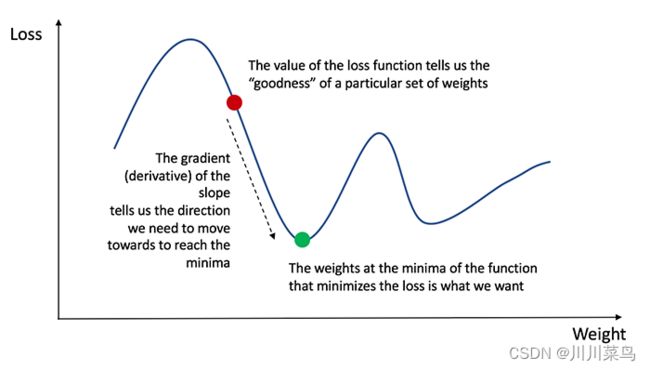
如果我们有导数,我们可以简单地通过增加/减少它来更新权重和偏差(参见上图)。这被称为梯度下降。
但是,我们不能直接计算损失函数对权重和偏差的导数,因为损失函数的方程不包含权重和偏差。因此,我们需要链式法则来帮助我们计算它。(计算损失函数相对于权重的导数的链式法则。请注意,为简单起见,我们仅显示了假定 1 层神经网络的偏导数。)
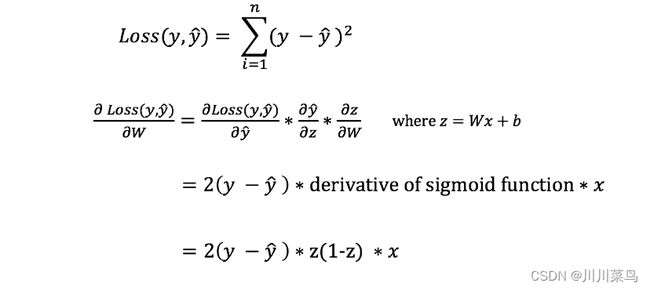
可以看出损失函数相对于权重的导数(斜率),这样我们就可以相应地调整权重。现在我们已经有了,让我们将反向传播函数添加到我们的 python 代码中。
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
def backprop(self):
# application of the chain rule to find derivative of the loss function with respect to weights2 and weights1
d_weights2 = np.dot(self.layer1.T, (2*(self.y - self.output) * sigmoid_derivative(self.output)))
d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y - self.output) * sigmoid_derivative(self.output), self.weights2.T) * sigmoid_derivative(self.layer1)))
# 用损失函数的导数(斜率)更新权重
self.weights1 += d_weights1
self.weights2 += d_weights2
完整应用
完整代码:
# coding=gbk
"""
作者:川川
@时间 : 2022/11/23 15:36
"""
import numpy as np
import matplotlib.pyplot as plt
# 激活函数
def sigmoid(x):
return 1.0 / (1 + np.exp(-x))
#
def sigmoid_derivative(x):
return x * (1.0 - x)
# 计算损失函数
def compute_loss(y_hat, y):
return ((y_hat - y)**2).sum()
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
# 它为每个输入创建 4 个介于 0 和 1 之间的随机数
self.weights1 = np.random.rand(self.input.shape[1], 4)
self.weights2 = np.random.rand(4, 1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
def backprop(self):
# application of the chain rule to find derivative of the loss function with respect to weights2 and weights1
d_weights2 = np.dot(self.layer1.T, (2 * (self.y - self.output) * sigmoid_derivative(self.output)))
d_weights1 = np.dot(self.input.T, (np.dot(2 * (self.y - self.output) * sigmoid_derivative(self.output),
self.weights2.T) * sigmoid_derivative(self.layer1)))
# update the weights with the derivative (slope) of the loss function
self.weights1 += d_weights1
self.weights2 += d_weights2
if __name__ == "__main__":
X = np.array([[0, 0, 1],
[0, 1, 1],
[1, 0, 1],
[1, 1, 1]])
y = np.array([[0], [1], [1], [0]])
nn = NeuralNetwork(X, y)
loss_values = [] # 记录loss列表
for i in range(1500):
nn.feedforward()
nn.backprop()
loss = compute_loss(nn.output, y) # 计算loss
loss_values.append(loss)
print(nn.output) # 输出
print(f" final loss : {loss}") # 最终loss
plt.plot(loss_values) # 可视化loss变化
plt.show()
现在我们已经有了用于执行前馈和反向传播的完整 python 代码,让我们将我们的神经网络应用到一个示例中,看看它的效果如何。(对应上面代码)

让我们对神经网络进行 1500 次迭代训练,看看会发生什么。查看下面的每次迭代损失图,我们可以清楚地看到损失单调递减到最小值。这与我们之前讨论的梯度下降算法是一致的。
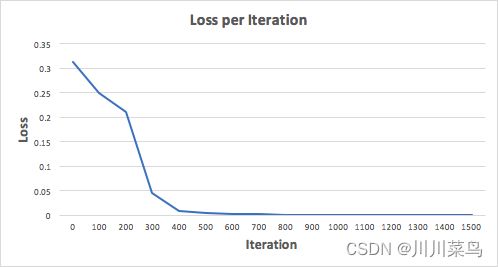
让我们看看 1500 次迭代后神经网络的最终预测(输出)
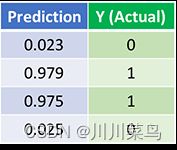
我们的前馈和反向传播算法成功地训练了神经网络,并且预测收敛于真实值。请注意,预测值与实际值之间存在细微差异。这是可取的,因为它可以防止过度拟合并允许神经网络更好地泛化到看不见的数据。
提问
- 除了 Sigmoid 函数,我们还可以使用什么激活函数?
- 如何训练神经网络时使用学习率?
- 如何使用卷积进行图像分类任务?
结束语
从头开始编写自己的神经网络学到了很多东西。 尽管 TensorFlow 和 Keras 等深度学习库可以在不完全了解神经网络内部工作原理的情况下轻松构建深度网络,但我发现更深入地了解神经网络是很有用的。