ICML 2022 | 清华提出FGST:首个视频去模糊的Transformer
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:披星戴月的奔波 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/563455469
本文介绍我们 ICML 2022 关于 Video Deblurring的工作:《Flow-Guided Sparse Transformer for Video Deblurring》。我们的文章于2022年1月份上传至Arxiv,是第一个用于视频去模糊任务的Transformer模型。

文章:https://arxiv.org/abs/2201.01893
代码:https://github.com/linjing7/VR-Baseline
单位:清华、华为诺亚、ETH
1. 简介
视频去模糊是底层视觉和图形学领域一个重要的任务,用于从模糊视频序列中恢复出清晰的视频,在手持相机、目标跟踪、自动驾驶等任务上具有广泛的应用。近年来,由于手持相机的普及,其拍摄过程中由于相机抖动、目标高速运动导致的运动模糊问题越来越引起人们的重视。
 图2 视频去模糊效果
图2 视频去模糊效果
为了去除运动模糊,研究者付出了很多的努力,主要可以分为以下两类:
(1) 传统方法:主要基于人工设计的先验和假设,这极大的限制模型的表示能力。此外,为了估计运动模糊,需要求解一个复杂的能量函数,一旦运动模糊核估计不准确,将带来大量的伪影。
(2) 基于卷积神经网络的方法:随着深度学习的发展,基于卷积神经网络的方法在视频去模糊领域取得了令人振奋的发展。然而,对于视频去模糊任务来说,捕获长距离的依赖关系以及自相似性时非常重要的,这使得模型能够从相似且清晰的区域获得信息补充,来对模糊区域进行重建。而这些能力显然是卷积神经网络所欠缺的。
我们注意到,Transformer模型的自注意力机制,正好可以用于捕获空间的长距离依赖关系以及自相似性。因此,我们首次尝试使用Transformer模型到视频去模糊这一任务。然而,直接使用原始的Transformer模型,会存在以下的问题:
(1) 如果直接使用global Transformer,那么计算复杂度与时空维度成二次方的关系,这容易带来不可承担的计算量。此外,global transformer由于参考所有key tokens,这将增大收敛难度,也可能带来过度平滑问题。
(2) 如果直接使用window-based local Transformer,那么可以减少计算量,但这又存在感受野过小的问题。在运动模糊情景中,视频帧间往往会存在较大的相对运动,而空间感受野过小将导致模型无法参考到相邻帧上一些相似、清晰的key tokens,从而限制了模型的表示能力。
我们将这一问题总结为:目前的Transformer在计算自注意力机制时,缺少运动信息的指引。而我们注意到,运动信息往往可以通过光流进行估计。因此,我们提出用光流来引导注意力机制的计算,在计算注意力机制的时候,每一个query token只参考光流指定的key tokens,而不是参考所有的tokens。此外,为了增大Transformer模型的时域感受野,受启发于循环神经网络,我们提出了循环嵌入机制。我们的主要贡献点可以概括为如下:
我们提出了FGST,第一次将Transformer模型用于视频去模糊任务。
我们提出了一种新的光流引导的注意力机制,称为FGS-MSA,及其改进版本,FGSW-MSA
我们设计了一种新的嵌入机制,称为Recurrent Embedding,用于传递帧间信息,建立长距离的时域依赖关系。
FGST在两个常见的视频去模糊数据集(DVD和GOPRO)上超过了SOTA方法,并且在真实数据集上有着更好的视觉效果。
2. 方法
2.1 网络的整体结构

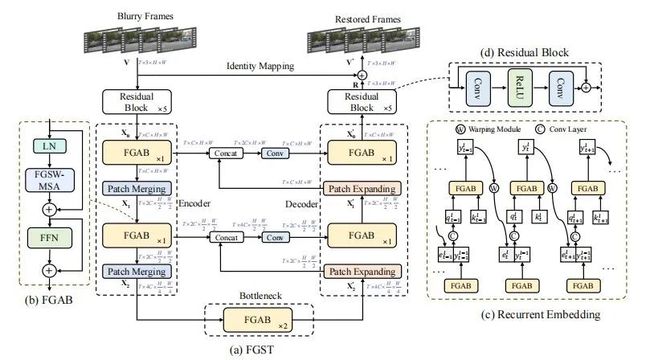
2.2 光流引导注意力
前面我们已经分析,原始的全局Transformer由于会参考所有的key elements,因此容易导致计算量过大以及难以收敛的问题;而基于窗口的局部Transformer则由于感受野过小,当帧间存在较大的相对运动时,容易错过相邻帧上一些相似的key tokens,而无法获得有效的信息补充。为了解决以上问题,我们提出光流引导的注意力机制FGS-MSA。如图4 (a) 所示,我们首先通过光流网络估计出帧间相对运动矢量,再根据帧间相对运动矢量,从相邻帧索引对应的key elements:
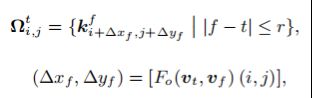
接着,对于每一个query elements,在计算注意力时,只参考这些高度相关的key elements即可:

 图4 光流引导注意力及光流引导窗口注意力
图4 光流引导注意力及光流引导窗口注意力
在FGS-MSA中,每一个query element在参考相邻帧时,只索引一个光流指定的key elements,当光流估计不准确时,效果将显著降低。为了提高鲁棒性,如图4 (b) 所示, 我们提出光流引导的窗口注意力机制。我们首先对query feature map切成窗口:

对于每一个query element,不仅参考本身对应的key elements,也参考位于同一窗口内部的其他queries对应的key elements:

在这种情况下,即使某个query element对应的光流矢量不准确,也能参考到窗口内部其他queries对应的内容相关的key elements,提高了模型的鲁棒性。
2.3 循环嵌入机制
在计算注意力时,为了节省计算量,我们只参考相邻帧,因此,虽然空间维度有了较大的感受野,但时间维度上的感受野较小,这限制了模型的表示能力。为了扩大时域感受野,受启发于循环神经网络,我们提出了循环嵌入机制 (Recurrent Embedding). 如图3 (c) 所示, 我们将RE嵌入到FGST的每一层中,通过将上一帧的输出连接到当前帧的输入,融合成query,再输入FGAB,从而实现序列化地将信息从第一帧传递到最后一帧,扩大了FGST的时域感受野:

3. 实验
3.1 定量实验对比
在DVD数据集的定量对比结果如下表所示:

在GOPRO数据集上的定量对比结果如下表所示:

可以看出,我们的FGST显著超过了之前的方法。
3.2 定性对比实验
在DVD数据集上的定性对比结果如下图所示:

在GOPRO数据集上的定性对比结果如下图所示:

在真实数据集上与其他方法的定性对比结果如下:

可以看出,我们的方法有着更好的视觉效果,特别是在有着剧烈运动的区域。
4. 总结
FGST是将Transformer模型用于视频去模糊领域的首个工作,通过光流对注意力机制进行引导,克服了全局Transformer和局部Transformer的缺陷,实现线性复杂度和全局空间感受野。此外,受启发于RNN,提出了循环嵌入机制,扩大了Transformer模型的时域感受野。
由于该工作是在实习期间做的,受限于公司规定,原始的预训练模型无法开源,但我们已经提供了训练代码,并且也重新训练了部分预训练模型,已经开源,在后续算力充裕时,我们将会训练更多的预训练模型,将开源做的更好,促进视频去模糊领域的发展。
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看