目标检测——夏侯南溪模型搭建篇(legacy)
4 定义模型整体结构
4.2 定义网络结构
模块需要包含的信息:
- 当前模块输出张量的shape;
step 3:获得GPU的设备信息,
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)这里使用if语句的好处是可以使代码更具有通用性(即也会适合使用CPU进行训练的设备)
step 4:将模型参数迁移至指定的GPU设备!!!(在使用GPU训练时十分重要)
注意:由于我们是在GPU上运行,所以还需要对Net类进行数据格式的迁移,
net.to(device)注意:除了模型内部参数及其包含的其它变量需要进行数据转换时,inputs和outputs也要进行数据格式的转换,因为它们不属于模型的一部分,不会在上面的代码中自动进行数据转换,需要我们手动地进行转换;
step 4:开启cuDNN
至于为什么需要开启cuDNN可以参考这篇文章《pytorch torch.backends.cudnn设置作用》,
文章说到:
总的来说,大部分情况下,设置这个 flag 可以让内置的 cuDNN 的 auto-tuner 自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。
一般来讲,应该遵循以下准则:
- 如果网络的输入数据维度或类型上变化不大,设置 torch.backends.cudnn.benchmark = true 可以增加运行效率;
- 如果网络的输入数据在每次 iteration 都变化的话,会导致 cnDNN 每次都会去寻找一遍最优配置,这样反而会降低运行效率。
4.2.2 前向运算函数
def forward(self, input):
# code of forward functionstep 3:获取模型的参数,
params = [p for p in model.parameters() if p.requires_grad]这里只取出了需要更新的参数,而被冻结了的参数则不需要进行更新;
step 2:设置网络的优化器,
optimizer = torch.optim.SGD(net.parameters(), lr=LR)
# 其中net_SGD.parameters()向优化器传入了网络的参数信息step 3:网络前向运算的的自洽性测试,可以参考我们的博文《目标检测——主干网络backbone的测试方法》;
5 训练模型
step 4:使用CUDA进行训练,即需要将模型迁移至CUDA设备;
首先,获得GPU的设备信息,
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)然后进行模型的数据类型的转换,
# move model to the right device
model.to(device)step 4:开启cuDNN加速;
torch.backends.cudnn.benchmark = True
# 不需要对cudnn.deterministic进行设置,这个参数是用来固定cuDNN的随机种子的step 4:计算loss;
step 5:反向传播梯度;
step 6:模型保存,我们使用.pth格式来保存模型(虽然.pth/.pt/.pkl这几种格式都是可以的),(因为一般来说,扩展名长的格式是后面出来的格式,后出来的格式一般也更加先进一些)
6 模型推理
step 1:尝试使用pillow-simd替换pillow
使用PIL库读取图片,
因为我感觉torch对PIL库的支持要更好一些,
(这是我从一个报错的提示信息中看到的,
File "E:\Path\Python\Anaconda3\envs\env_general\lib\site-packages\torchvision\transforms\functional.py", line 54, in to_tensor
raise TypeError('pic should be PIL Image or ndarray. Got {}'.format(type(pic)))
TypeError: pic should be PIL Image or ndarray. Got
所以我们还是选择PIL库进行图片读取;
备注:
使用OpenCV读取图片要注意对图像张量的维度进行变换,参考我的博文《目标检测——使用OpenCV读取图片要注意进行维度变换》
输入变量的类型转换:
注意,输入变量的类型要与模型的类型一致,否则就会报错,
例如:
报错“RuntimeError: Expected object of scalar type Long but got scalar type Float for argument #2 'weight' in call to _thnn_conv2d_forward”,
解决方法可以参考我的博文《使用PyTorch前向运算时出现“RuntimeError: Expected object of scalar type Long but got scalar type Float for ……”》
step 2:初始化检测器,记得将网络设置为eval模式,
net.eval()因为这样网络在进行forward运算时,会依照参数进行固定输出,而不会进行BN和Dropout的归一化操作;
step 3:关闭梯度计算,(以加快推理速度),
南溪觉得最优雅的实现方式是这样的,
@torch.no_grad()
def infer(model, data):
model.eval()
# Rest of infer code备注:
也可以使用torch.set_grad_enabled()函数来实现,
torch.set_grad_enabled(False)也可以使用 with torch.no_grad():语句,如图所示,

注意:net.eval()和关闭梯度的操作必须同时使用,网络的eval模式不包含关闭梯度运算的操作;
开始看到这样的操作时,我感觉是挺奇怪的,为什么PyTorch不把with torch.no_grad()的操作合并到net.eval()里面去呢?
我开始觉得是没有这样的需求的,
后来我想了一下,的确是有一定的应用场景的,也就是在进行在线学习的时候,
我们将在线推理的数据同时用来训练,因为net.eval()只会关闭BN和Dropout层的更新,
而这对在线学习是不会影响的:
对于Dropout层,推理的时候肯定是要停止更新的,否则模型会有问题;
对于BN层,因为在线学习的时候,每次只有一个样本,所以进行批归一化也没有很大的必要了;
step 3:初始化检测器;
step 4:设置设备,我们使用GPU进行推理;
device = torch.device("cpu" if args.cpu else "cuda")
step 4:开启cuDNN加速;
torch.backends.cudnn.benchmark = true
(这个设置我在“训练模型”的过程中也写了的,因为我们需要把“训练模型”和“模型推理”考虑成两个相对独立的过程,所以这里我们又写了一遍)
step 5:按照batch进行推理;
南溪觉得按照batch进行推理有几个好处,首先是如果GPU资源较好的话,可以将 batch size设置得尽量大一点,这样子推理的速度也会快一些;
还有就是DataLoader在取数据的时候,如果最后几个数据不足以凑足一个batch的话,torch会只取最后几个数据,我感觉还是挺智能的,可以看看下面的实例图,(这是我在做 Digit Recognizer时测试的一个效果图),
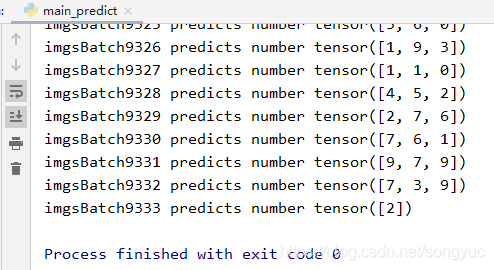
(这里 Digit Recognizer的test集共有28000个数据,28000%3 = 1,所以这里DataLoader的数据获取操作是正确的)
7 模型评测
8 数据结构设计
可以参考南溪的博文《目标检测——夏侯南溪目标检测模型之数据结构》
9 输出信息的显示
对于输出信息的显示,我们采用str.format()函数来实现;
具体内容可以参考南溪的博文《目标检测——夏侯南溪目标检测模型之输出信息显示》
8 模型蒸馏
10 模型搭建备忘
10.1 编写一个 Jupyter Notebook文件专门进行包的安装
我们可以编写一个 Jupyter Notebook文件专门进行相关第三方包的安装,
可以使用!或者os的命令;