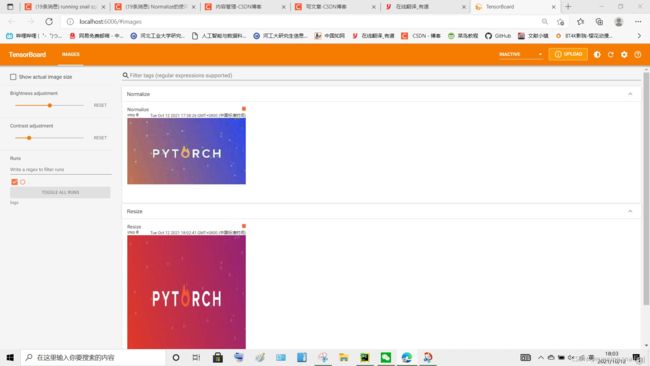
Resize的使用————Transforms
哔哩大学的PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
的P12讲讲述了transforms中Resize的使用。
开局小技巧:
Resize
class Resize(torch.nn.Module):
"""Resize the input image to the given size.
将输入图像调整为给定的大小。
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions
.. warning::
The output image might be different depending on its type: when downsampling, the interpolation of PIL images
and tensors is slightly different, because PIL applies antialiasing. This may lead to significant differences
in the performance of a network. Therefore, it is preferable to train and serve a model with the same input
types.
Args:
size (sequence or int): Desired output size. If size is a sequence like
(h, w), output size will be matched to this. If size is an int,
smaller edge of the image will be matched to this number.
i.e, if height > width, then image will be rescaled to
(size * height / width, size).
.. note::
In torchscript mode size as single int is not supported, use a sequence of length 1: ``[size, ]``.
interpolation (InterpolationMode): Desired interpolation enum defined by
:class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.BILINEAR``.
If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` and
``InterpolationMode.BICUBIC`` are supported.
For backward compatibility integer values (e.g. ``PIL.Image.NEAREST``) are still acceptable.
max_size (int, optional): The maximum allowed for the longer edge of
the resized image: if the longer edge of the image is greater
than ``max_size`` after being resized according to ``size``, then
the image is resized again so that the longer edge is equal to
``max_size``. As a result, ``size`` might be overruled, i.e the
smaller edge may be shorter than ``size``. This is only supported
if ``size`` is an int (or a sequence of length 1 in torchscript
mode).
antialias (bool, optional): antialias flag. If ``img`` is PIL Image, the flag is ignored and anti-alias
is always used. If ``img`` is Tensor, the flag is False by default and can be set True for
``InterpolationMode.BILINEAR`` only mode.
.. warning::
There is no autodiff support for ``antialias=True`` option with input ``img`` as Tensor.
"""
def __init__(self, size, interpolation=InterpolationMode.BILINEAR, max_size=None, antialias=None):
super().__init__()
if not isinstance(size, (int, Sequence)):
raise TypeError("Size should be int or sequence. Got {}".format(type(size)))
if isinstance(size, Sequence) and len(size) not in (1, 2):
raise ValueError("If size is a sequence, it should have 1 or 2 values")
self.size = size
self.max_size = max_size
# Backward compatibility with integer value
if isinstance(interpolation, int):
warnings.warn(
"Argument interpolation should be of type InterpolationMode instead of int. "
"Please, use InterpolationMode enum."
)
interpolation = _interpolation_modes_from_int(interpolation)
self.interpolation = interpolation
self.antialias = antialias
def forward(self, img):
"""
Args:
img (PIL Image or Tensor): Image to be scaled.
Returns:
PIL Image or Tensor: Rescaled image.
"""
return F.resize(img, self.size, self.interpolation, self.max_size, self.antialias)
def __repr__(self):
interpolate_str = self.interpolation.value
return self.__class__.__name__ + '(size={0}, interpolation={1}, max_size={2}, antialias={3})'.format(
self.size, interpolate_str, self.max_size, self.antialias)
Resize的代码为入下的#Resize部分:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter#从tensorboard引入SummaryWriter
from torchvision import transforms
# 之前说过tensorboard必须为tensor的数据类型
# tensor实际上就是一个多维数组,能够创造更高维度的矩阵、向量,
# 具体参考知乎 https://zhuanlan.zhihu.com/p/48982978
# class ToTensor用法:
# """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor. This transform does not support torchscript.
# 输入必须为PIL Image,或者numpy.ndarray,转化为tensor类型。
writer = SummaryWriter("logs")#首先把tensorboard做一个简单的配置
img = Image.open("images/pytorch.png")
print(img)
#用transforms中的一个totensor数据类型,起名叫trans_totensor,创建这样一个对象
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img) #调用的一个方法,把上边的img变成了一个tensor类型
#,之后img可以放到tensorboard中
writer.add_image("ToTensor", img_tensor)#在括号里按住ctrl+P后,tag就叫ToTensor,img就是img_tensor
writer.close()#一个关闭
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
#需要输入均值和标准差,因为我们的图片不是rgb三层的,提供三声道标准差
img_norm = trans_norm(img_tensor)
#上边做好的image的tensor数据类型
#output[channel] = (input[channel] - mean[channel]) / std[channel]
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
writer.close()
#Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
#img PIL -> resize ->img_resize PIL
img_resize = trans_resize (img)
# img_resize PIL -> totensor -> img_resize 数据类型
img_resize = trans_totensor(img_resize)
writer.add_image("Resize" , img_resize, 0)
print(img_resize)
writer.close()
结果为一个变窄长的图片(第二张):