基于大数据分析的葡萄酒品质鉴别系统设计与实现
温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :)
1. 项目背景
葡萄酒品鉴既是一门科学,也是一门艺术。品鉴葡萄酒,首先当然要能鉴别酸、甜、苦、咸、鲜五种基本味道,它们和酒精等是否均衡协调。决定葡萄酒品质的这些特性最终决定与其内部的化学成份,由于传统的通过品酒师鉴别酒的品质复杂,且人为干扰因素很大,我们尝试通过大数据分析方式鉴别葡萄酒的好坏而开发此系统。数据集是采集于葡萄牙北部“Vinho Verde”葡萄酒的数据。由于隐私和物流问题,只有理化变量特征是可以进行使用的(例如,数据集中没有关于葡萄品种、葡萄酒品牌、葡萄酒销售价格等的数据)。
2. 功能组成
基于大数据分析的葡萄酒品质鉴别系统的功能主要包括:
3. 工具包导入和数据读取
项目技术栈:pandas数据分析 + 数据可视化 + 特征工程 + 机器学习 + 决策树算法 + 随机森林算法。导入所需的依赖包:
import warnings
warnings.filterwarnings('ignore')
import os
import gc
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
from IPython.display import display
np.random.seed(7)
plt.style.use('seaborn')
from tqdm import tqdm
import json
import time
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
利用pandas完成数据的读取和预处理:
red = pd.read_csv('data/winequality-red.csv', sep=';')
white = pd.read_csv('data/winequality-white.csv', sep=';')
red['type'] = 'red'
white['type'] = 'white'
wine_df = pd.concat([red, white])4. 数据探索式分析
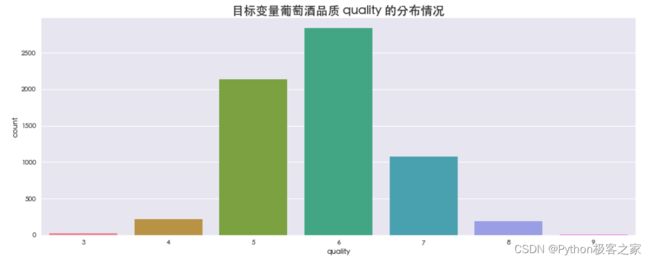
4.1 目标变量葡萄酒品质 quality 的分布情况
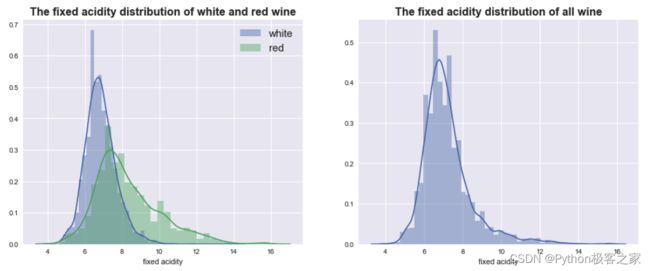
4.2 非挥发性酸 fixed acidity 分布情况
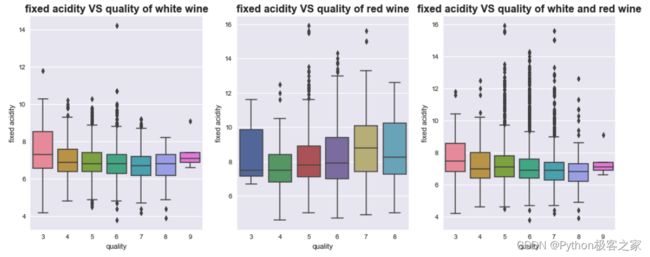
不同质量的葡萄酒的 fixed acidity 分布箱型图:
 4.3 挥发性酸 volatile acidity 分布情况
4.3 挥发性酸 volatile acidity 分布情况
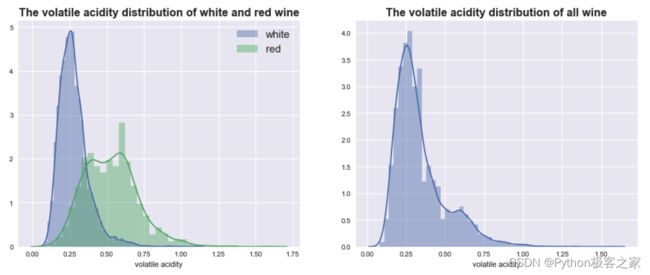
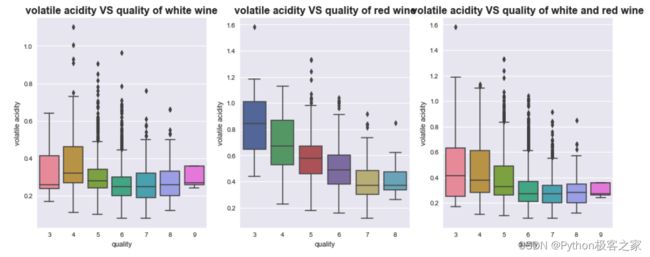
不同质量的葡萄酒的挥发性酸 volatile acidity 分布箱型图:
 4.4 柠檬酸 citric acid 分布情况
4.4 柠檬酸 citric acid 分布情况
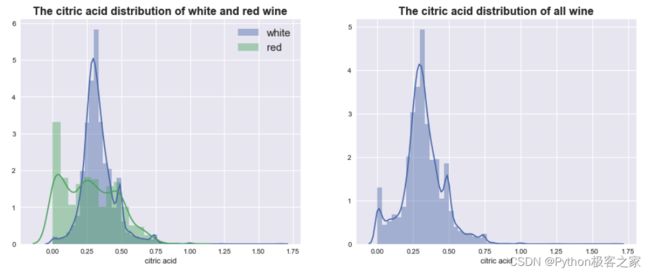
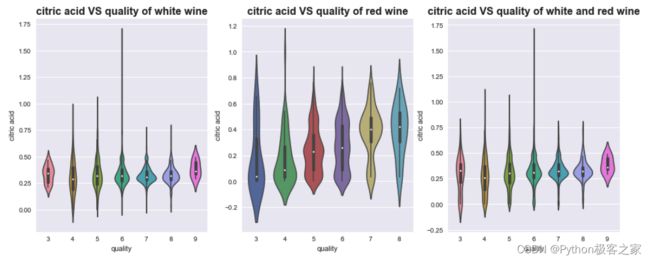
不同质量的葡萄酒的柠檬酸 citric acid 的分布小提琴图:
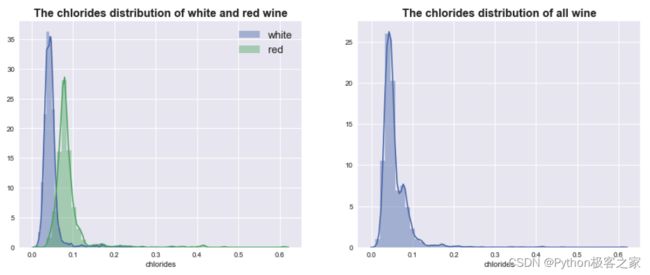
 4.5 氯化物 chlorides 的分布情况
4.5 氯化物 chlorides 的分布情况
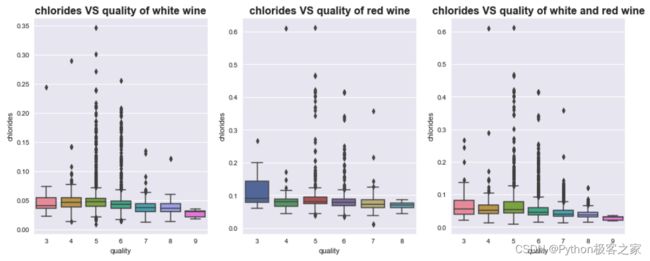
不同质量的葡萄酒的氯化物 chlorides 的分布箱型图:
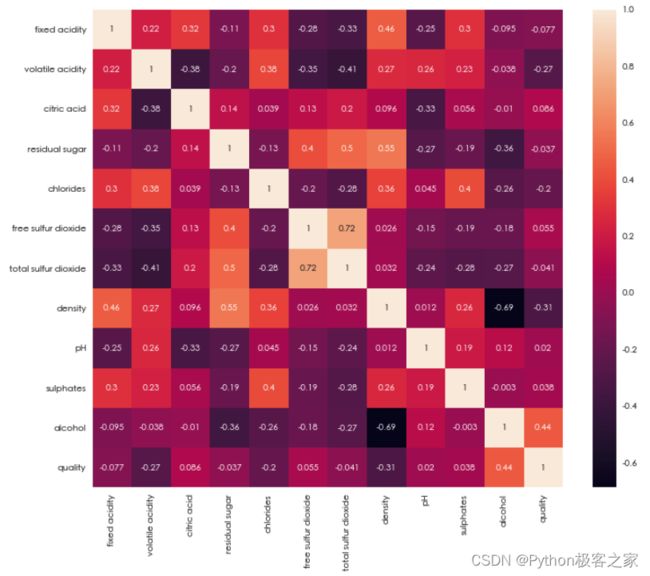
4.6 特征间的相关性分析
5. 基于递归决策树的葡萄酒品质鉴别模型
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是CART回归树模型。
dtrain = xgb.DMatrix(X_train, y_train)
dtest = xgb.DMatrix(X_test, y_test)
watchlist = [(dtrain, 'train'), (dtest, 'test')]
param = {
'eta': 0.2,
'max_depth': 12,
'subsample': 0.5,
'objective': 'multi:softmax',
'nthread': -1,
'silent': 1,
'booster': 'gbtree',
'num_class': 7
}
xgb_model = xgb.train(
param,
dtrain,
evals=watchlist,
verbose_eval=5,
early_stopping_rounds=10,
num_boost_round=1000
)[0] train-merror:0.322046 test-merror:0.447692
Multiple eval metrics have been passed: 'test-merror' will be used for early stopping.
Will train until test-merror hasn't improved in 10 rounds.
[5] train-merror:0.176843 test-merror:0.393846
[10] train-merror:0.125877 test-merror:0.375385
[15] train-merror:0.09492 test-merror:0.355385
[20] train-merror:0.064478 test-merror:0.346154
[25] train-merror:0.044638 test-merror:0.34
[30] train-merror:0.031127 test-merror:0.329231
[35] train-merror:0.0183 test-merror:0.324615
[40] train-merror:0.010604 test-merror:0.321538
[45] train-merror:0.006157 test-merror:0.316923
[50] train-merror:0.004276 test-merror:0.316923
[55] train-merror:0.002736 test-merror:0.312308
[60] train-merror:0.001539 test-merror:0.306154
[65] train-merror:0.001197 test-merror:0.306154
Stopping. Best iteration:
[59] train-merror:0.002052 test-merror:0.304615
完成模型的训练后,测试集预测准确率:
xgb_test_pred = xgb_model.predict(dtest)
error_rate = sum(xgb_test_pred != y_test) / len(y_test)
xgb_test_acc = 1 - error_rate
print('测试集分类准确率为 = {}'.format(xgb_test_acc))输出:测试集分类准确率为 = 0.6938461538461538
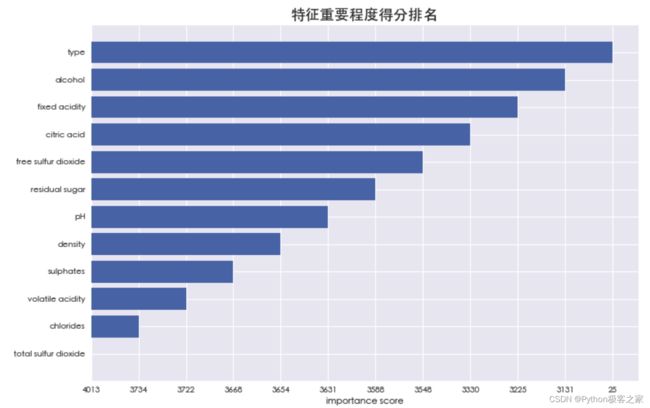
特征重要程度分布情况:
6. 基于随机森林的葡萄酒品质鉴别模型
随机森林,random forest,是集成学习中的一种典型的bagging算法。bagging算法可以和其他分类、回归算法结合,提高准确率、稳定性的同时,通过降低结果的方差,来避免过拟合的发生。随机森林,就简单来讲,森林指的是很多个决策树组合在一起,随机则是指随机从数据集中采样来训练模型中的每棵决策树。
随机选取不同的数据集是为了保证每个决策树看待问题的角度不同,以便输出相似但不相同的模型结果,再讲所有决策树结果整合在一起,作为输出结果,而这一训练方式,意味着很难过拟合,并且对噪音不敏感。
随机森林的步骤:
- 预设模型的超参数,比如几棵树,每棵树的深度有几层?
- 随机采样,训练每个决策树,从而保证每棵树看待问题的角度都不一样。样本数量n<<总体数量N,样本特征d<<总体特征D。
- 输入待测样本到每棵树中,再将每棵树的结果整合在一起:regression:均值,classification:众数。
rf_model = RandomForestClassifier(max_depth=16, n_estimators=50)
rf_model.fit(X_train, y_train)
rf_train_pred = rf_model.predict(X_train)
error_rate = sum(rf_train_pred != y_train) / len(y_train)
rf_train_acc = 1 - error_rate
print('训练集分类准确率为 = {}'.format(rf_train_acc))
rf_test_pred = rf_model.predict(X_test)
error_rate = sum(rf_test_pred != y_test) / len(y_test)
rf_test_acc = 1 - error_rate
print('测试集分类准确率为 = {}'.format(rf_test_acc))训练集分类准确率为 = 0.9936719685308706
测试集分类准确率为 = 0.7015384615384616
可以看出,对于测试集不同模型的准确率为:
- xgboost:0.6938461538461538
- random_forest: 0.7015384615384616
7. 结论
本项目针对葡萄牙北部“Vinho Verde”葡萄酒的数据集,利用pandas、Matplotlib、seaborn 等数据科学工具包对数据集进行可视化探索式分析,并构建递归决策树和随机森林算法,实现对葡萄酒质量的预测,尝试通过大数据分析方式分析影响葡萄酒品质理化因素。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 Wechat / QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例
