2021 re:Invent 全球大会 | 请收藏数据和基础架构方面的最新探索宝典!

在12月2日的亚马逊云科技 re:Invent 全球大会上,亚马逊机器学习副总裁 Swami Sivasubramanian 为大家带了来题为《如何通过数据与人工智能进行创新》的主题演讲。

Swami 指出,“数据是推动洞察的潜在力量,有助于更好地开展业务。”他列举了飞利浦医疗、纳斯达克等多种大数据的例子,”从大数据走向海量非结构化数据,事实上80%的数据是非结构化的。”

亚马逊云科技提供了完整的端到端的数据存储、计算、分析、人工智能创新的工具与土壤。Swami 概述了亚马逊云科技现有的工具和服务,“我们为所有工作负载和所有类型的数据的整个端到端数据、分析和 ML 提供最全面的服务。”

业竞争日趋激烈,打造数据驱动型企业提高业务敏捷性实现快速决策与创新,已成为众多企业的基本诉求。“数据”已经成为企业最有价值的资产,从成本优化到产品研发,再到商业模式创新,数据都扮演了重要角色。利用广泛而深入的云服务,并凭借在数据领域的产品创新与前瞻眼光,亚马逊云科技将助力企业实现“数据驱动创新”。
在此,Swami 提出了现代化的端到端数据战略。


Swami 指出,形成现代端到端数据战略有三个要素:
数据架构现代化
不同的场景需要使用专门构建的工具,专门的工具需要专业的现代化托管平台,在这方面,亚马逊拥有“无与伦比的成熟度和经验。
统一分析数据
技术快速发展助力企业打破数据孤岛,通过云上专门工具实现数据有机整合与统一,尽享灵活扩展与极致性能,将所有数据连接到一个安全且管理良好的连贯系统中。
基于数据进行业务创新
帮助数据进行创新的内核是“从客户角度出发”,企业植根于自身业务的创新诉求是创新的原动力,而人工智能等技术为创新提供了手段与方法。
MODERNIZE-数据架构现代化篇

Swami 回答了如何帮助诊断数据性能问题,对于此亚马逊云科技希望能够提供警报以修复数据性能问题,帮助大规模识别性能和运营问题。
为此,新的 Amazon DevOps GuruforRDS 将在几分钟内自动检测、诊断和解决难以发现的数据库相关性能问题。同时,12月2日重磅发布了 Amazon RDS Custom 支持 SQL Server。通过托管式服务节省时间的优势,Amazon RDS Custom for SQL sever 帮助实现运维自动化,版本维护与补丁升级,将宝贵的资源专注于更重要的业务。

今天的另外一个重磅发布是新的 Amazon Dynamodb feature:Standard-Infrequent Access t1able class,它可以将不频繁访问的表数据进行分类,帮助您将 DynamoDB 的储存成本降低60%。

Swami 表示,亚马逊云科技提供了广泛的专用数据库组合,并讲述了 Netflix、德甲联赛等客户使用情况。很明显,转移到托管数据库系统可以在时间、金钱和精力上提供难以置信的节省。
他补充说,已经有超过500000个数据库迁移到亚马逊云科技,但制定迁移计划可能是一项挑战。因此,亚马逊正在推出 Amazon Database Migration Service Fleet Advisor 可帮助您选择最佳可用的计算实例和配置,以部署机器学习模型,从而获得最佳的推理性能和成本。“这可以在数小时内完成过去需要数周的工作,也将使您更容易实现数据现代化。

UNIFY-统一分析数据篇
Swami 指出,“分解堆积如山的数据对于挖掘您的业务需求至关重要。”许多公司都通过在亚马逊云科技上运行的数据湖来实现这一点,够收集、存储和分析来自一系列筒仓的数据。
在 Amazon S3 上构建数据湖提供了无与伦比的耐用性、可用性和可扩展性,以及强大的安全性和分析工具。他补充说,使用最新发布的亚马逊云科技数据湖构建工具,可以快速构建适合您的数据湖,Amazon Athena 提供了一种有用的方法来分析所有数据,以获得您需要的见解。
这里涉及到三个问题需要解决:如何在在 Amazon Lake Formation 上快速移动与数据治理?如何使用 Amazon Athena 进行数据湖快速查询?如何使用专门构建数据分析工具进行高效、快速、成本效益的分析?

Swami 表示,公司当前正在全面研究 Amazon Redshift,以及多年来它为客户带来的各种创新。

今天 Amazon QuickSight 的更新也大会上发布,新的Amazon QuickSight Q 工具允许客户快速、轻松地获得答案,使所有用户无需培训即可访问 BI。
NFL(职业橄榄球大联盟)使用 Amazon QuickSight Q 与媒体、KOL 和粉丝以一种引人入胜且有趣的方式分享统计数据例子,说明了这项新功能的强大功能。

随后,Swami 通过 Demo 演示了关于昨天发布的 Amazon Redshift serverless 和 Amazon QuickSight Q 如何让游戏开发商等公司获得实时反馈和数据,从而毫不拖延地扩大服务规模。
INNOVATE-基于数据进行业务创新
接下来, Swami 与大家深入探讨了结构化数据与非结构化数据。
“数据是机器学习的燃料,”他表示,“即使有正确的策略,准备数据也可能是构建 ML 技术最令人愤怒也最令人沮丧的部分。”
从数据准备角度来看,Amazon SageMaker Ground Truth 在这方面大有帮助,为 NFL 等客户提供预构建的工作流程、模板和多种劳动力选择。但这还不够,公司现在正在推出 Amazon SageMaker Ground Truth Plus,它让用户无需编写任何代码即可快速交付高质量的训练数据集。

从模型构建与算法编写环节来看,Amazon SageMaker Studio Notebook 允许用户访问广泛的数据源,并在一个笔记本中执行数据工程、分析和 ML 工作流。

训练与调优,模型部署与管理都涉及到了基础设施层面的创新。

不过,这并不是 Amazon SageMaker 的全部,因为该平台将获得三项新功能发布,将使您在组织中扩展机器学习变得更加容易:
1
Training Compiler 模型训练编译器,让您将模型培训速度提高50%;
2
Inference Recommender 模型推理推荐程序,可将部署时间从数周减少到数小时
3
Serverless Inference 无服务器推理,通过按使用付费的定价降低拥有成本。
端到端解决方案对于解决业务问题至关重要,因此亚马逊在一系列此类工具上进行了重大投资。
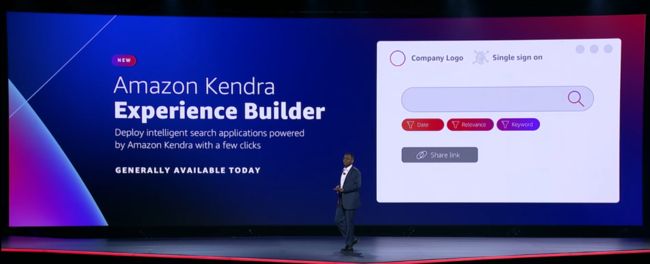
Swami 认为,对于企业而言解决端到端人工智能解决方案,优化、定制和个性化都是不可或缺的推动因素。他指出,为了优化搜索体验新的 Amazon Kendra Experience Builder 工具,只需点击几下即可部署智能搜索应用程序。这使得 IT 部门更容易建立网站搜索。
而聊天机器人是另一个有用的例子,Swami 在谈到联系中心时指出,如何把坏的聊天机器人和好的聊天机器人区分开来?人工智能与对话设计是一项至关重要的新技术,但这项技术仍处于初级阶段。幸运的是,亚马逊正在推出 Amazon Lex Automated Chatbot Builder,这是一项新功能,可将机器人设计从数周减少到数小时,通过先进的自然语言理解简化设计。

亚马逊参与撰写的人工智能领域重量级书籍《 Dive into Deep Learning》(中文名:《动手学深度学习》)已经在300多个高校、50个国家与地区面世,成为了清华大学、伯克利大学、斯坦福大学、剑桥大学等顶级学府的教材。

在Swami 演讲的最后,他告诉大家:“蓬勃发展的公司与艰难求生的公司之间的关键区别,在于他将创建一个数据驱动的组织视为当务之急。”
同样,亚马逊云科技效用计算和应用程序高级副总裁 Peter DeSantis 带来了我们在存储、计算架构和可持续发展方面的最新尝试。

存储
Peter 首先回顾了存储领域从磁盘存储到云上 Nitro 架构存储服务的创新历程。他表示,如今亚马逊云科技的存储规模也是前所未有的,作为亚马逊云科技最早发布的服务, Amazon S3 现在已经拥有了超过了数万亿个对象。
通过 Amazon S3 服务,用户可以实现存储和检索内容以及数据备份,而随着使用的增长,Amazon S3 也提供了更多的存储类别来实现更优化的存储性能,如为了更便宜地备份数据引入了 Amazon S3 Glacier 和 Amazon S3 Glacier Deep Archive 来实现较低的存储成本等等。

处理存储海量数据的同时,安全性、可控性和可持续性也不容忽视。目前亚马逊云科技已经建立起全世界最大的自动推理团队,用于测试存储的安全性、可控性和可持续性。
值得指出的是,在云上同时运转的成千上万的计算离不开 Nitro 的支持。每个 Amazon EC2 都有一个 Nitro 控制器,用来启动云计算并确保安全。
Peter 也分享了这样的方法的几个好处 :
1
可以用 Nitro 控制器来满足每一个顾客的工作负载需要;
2
通过 Nitro Enclave 能提供更安全的能力;
3
Nitro 能把任何一个服务器变成 Amazon EC2 实例。
通过亚马逊云科技的网络存储和 Nitro 控制器,可以有效提升系统的多样性,以改进储表现并实现能够支持任何的硬件改进等等。我们发布的 Nitro SSD 固态硬盘,现在已经提供给超过近百万的客户,这使得任何亚马逊云科技服务可以保证提供同样的速度,并降低60%的平均输入输出延迟。
计算

随后,Peter也为我们介绍了关于昨天发布的 Amazon Graviton3 的更多消息,并分享了相较于 Amazon Graviton2,Amazon Graviton3 性能实现飞跃的奥秘:
想让处理器更快,第一个方法是提升处理器频率。更高的频率意思是指处理器可以运转的更快,但这也意味着芯片会要使用更多的电量,而更高的电力意味着高成本,更多的热量,较低的效率。
那在这一背景下 Amazon Graviton3 该如何抉择?亚马逊云科技的选择是提升单个核心的性能,从而提升每一个循环当中所做的工作负载数量。这样绝大多数工作负载都可以在 Amazon Graviton3 上获得提升25%的性能提升。
第二方案是增加更多的核,但是往往更多的核数在实际负载中的性能较低。当我们做测试的时候发现,内存带宽将极大的影响计算机型,所以在 Amazon Gravtion3 里面我们并不是使用更多的核,而是改进内存带宽。
Amazon Graviton2 有内存带宽是针对每个 CPU 内核的,而 Amazon Graviton3 会有60%更多的一些内存带宽;Amazon Graviton3 也将驱动全球首个支持 DDR5 内存实例 - Amazon EC2 C7g

由 Amazon Trainium 芯片支持的 Trn1 实例方面,Peter 表示业界对于机器学习巨大兴趣在不断的产生。今天超过几十万的顾客正在使用亚马逊云科技的机器学习服务来实现自己的人工智能工具的训练和部署,而 Amazon Trainium 芯片支持的 Trn1 实例充分考虑到机器学习的工作负载,可以充分帮助各个规模的公式利用机器学习驱动业务,提升顾客体验,改进产品。
基础设施的可持续发展
Peter 表示,亚马逊一直致力于降低能源消耗,我们承诺在2024年降低零碳排放。提升效率以帮助我们的客户和我们自己成就更多可能,比如亚马逊云科技设计了能源效能较高的芯片可以提升60%的能源表现。
亚马逊已经决定到2030年实现100%采用可再生的能源的目标,但如今我们希望把将进程缩短到2025年。
目前亚马逊云科技在全球已经启动了超过12000个可再生能源的项目项目,如今亚马逊是世界上最大的公司可再生能源的购买者。通过这些可再生的项目,在亚马逊每年可以减少1300万吨的碳排放。
此外,亚马逊也宣布了在欧洲的项目,是最大海上风厂项目之一,今年也发布了储存太阳能的项目,通过这些长期的可持续性投资,使得亚马逊在未来的十年内具备实现碳中和,并更具备可持续性。
听说,点完下面4个按钮
就不会碰到bug了!
