cs231n学习笔记(一)
文章目录
-
- 图像分类
-
-
- Nearest Neighbor分类器
- k-Nearest Neighbor(KNN)分类器
- 超参数的选择
- KNN分类器的劣势
-
- 线性分类
-
-
- 线性评分函数
- 线性分类器
- 损失函数
-
- 反向传播中的梯度计算
-
-
- 简单表达式和理解梯度
- 使用链式法则计算复合表达式
- 模块化:Sigmoid例子
- 反向传播实践:分段计算
- 回传流中的模式
-
- 神经网络
-
-
- 单个神经元建模
- 作为线性分类器的单个神经元
- 常用激活函数
- 神经网络结构
- 设置数据和模型
- 梯度检查
- 学习之前合理性检查
- 检查学习过程
- 参数更新
- 超参数调优
- 评价
- 总结
-
图像分类
-
图像分类中的任务是预测给定图像的单个标签(或标签上的分布,如置信度)。图像是从 0 到 255 的 3 维整数数组,大小为宽 x 高 x 3。3 代表三个颜色通道红、绿、蓝。
-
挑战:由视角改变、尺寸改变、变形遮挡、光照条件、背景干扰、类内不同而引起图像的像素发生变化,干扰图像分类。
一个好的图像分类器不会因为这些改变而改变结果,同时对类内变化保持敏感性。
-
数据驱动方法
在得到一组数据后,如果想要得到某种效果和对数据做某些操作,让模型去贴合数据,从而改变该模型,以达到效果。
模型驱动方法
从模型侧发出进行的数据分析,让数据去贴合某个模型,拿出一组数据来,对比更适合哪个模型。
区别
模型驱动和数据驱动的区别在于对数据的操作,如果操作并不改变模型本身,就是模型驱动,如果操作改变了模型,让模型去贴合数据,就是数据驱动的研究方法。
-
图像分类流程
- 输入:输入由一组N 个图像组成,每个图像都标有K 个不同类别中的一个。此数据称为训练集。
- 学习:此步骤称为训练分类器或学习模型。
- 评估:通过要求分类器预测一组它以前从未见过的新图像的标签来评估分类器的质量。然后将这些图像的真实标签与分类器预测的标签进行比较。
Nearest Neighbor分类器
-
最近邻算法
在训练机器的过程中,我们什么也不做,我们只是单纯记录所有的训练数据,在图片预测的步骤,我们会拿一些新的图片去在训练数据中寻找与新图片最相似的,然后基于此,来给出一个标签。
-
L1距离
给定两幅图片,将他们表示为两个向量 I 1 I_{1} I1和 I 2 I_{2} I2
d 1 ( I 1 , I 2 = ∑ p ∣ I 1 p − I 2 p ∣ ) d_{1}(I_{1},I_{2}=\displaystyle\sum_{p}|I_{1}^{p}-I_{2}^{p}|) d1(I1,I2=p∑∣I1p−I2p∣)
-
代码实现
import numpy as np class NearestNeighbor(object): def __init__(self): pass def train(self, X, y): """ X is N x D where each row is an example. Y is 1-dimension of size N """ # the nearest neighbor classifier simply remembers all the training data self.Xtr = X self.ytr = y def predict(self, X): """ X is N x D where each row is an example we wish to predict label for """ num_test = X.shape[0] # make sure that the output type matches the input type Ypred = np.zeros(num_test, dtype = self.ytr.dtype) # loop over all test rows for i in range(num_test): # find the nearest training image to the i'th test image # using the L1 distance (sum of absolute value differences) distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) min_index = np.argmin(distances) # get the index with smallest distance Ypred[i] = self.ytr[min_index] # predict the label of the nearest example return Ypred from cs231n.data_utils import load_CIFAR10 Xtr, Ytr, Xte, Yte = load_CIFAR10('data\CIFAR10') # a magic function we provide # flatten out all images to be one-dimensional Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072 Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072 nn = NearestNeighbor() # create a Nearest Neighbor classifier class nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels Yte_predict = nn.predict(Xte_rows) # predict labels on the test images # and now print the classification accuracy, which is the average number # of examples that are correctly predicted (i.e. label matches) print ('accuracy: %f' % (np.mean(Yte_predict == Yte)))
-
-
L2距离
给定两幅图片,将他们表示为两个向量 I 1 I_{1} I1和 I 2 I_{2} I2
d 2 ( I 1 , I 2 ) = ∑ p ( I 1 p − I 2 p ) 2 d_{2}(I_{1},I_{2})=\sqrt{\displaystyle\sum_{p}(I_{1}^{p}-I_{2}^{p})^{2}} d2(I1,I2)=p∑(I1p−I2p)2
-
代码实现
只需替换一行代码
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1)
-
-
L2距离与L1距离比较
相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。
k-Nearest Neighbor(KNN)分类器
-
算法思路
与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。
-
当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。
-
更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。或者说,用这种方法来检索相邻数据时,会对噪音产生更大的鲁棒性,即噪音产生不确定的评价值对评价结果影响很小。
上面例子使用了训练集中包含的2维平面的点来表示,点的颜色代表不同的类别或不同的类标签,这里有五个类别。不同颜色区域代表分类器的决策边界。这里我们用同样的数据集,使用K=1的最近邻分类器,以及K=3、K=5。K=1时(即最近邻分类器),是根据相邻的点来切割空间并进行着色;K=3时,绿色点簇中的黄色噪点不再会导致周围的区域被划分为黄色,由于使用多数投票,中间的整个绿色区域,都将被分类为绿色;k=5时,蓝色和红色区域间的这些决策边界变得更加平滑,它针对测试数据的泛化能力更好。
超参数的选择
-
k-NN分类器需要设定k值、选择不同的距离函数等等,这些选择称为超参数。
-
常见的做法是将数据分为三组:训练集(大部分数据),验证集(从训练集中取出一小部分数据用来调优),测试集。我们在训练集上用不同超参来训练算法,在验证集上进行评估,然后选择一组在验证集上表现最好的超参数。当完成了这些步骤以后,再把这组超参数在测试集上跑一跑。这个数据才是告诉你,你的算法在未见的新数据上表现如何。必须分割验证集和测试集,所以当我们做研究报告时,往往只是在最后一刻才会接触到测试集。
- 在机器学习中,我们关心的不是要尽可能拟合训练集,而是要让我们的分类器以及方法,在训练集以外的未知数据上表现得更好。
- 不要用测试集去调整参数,容易使得你的模型过拟合。机器学习系统的目的,是让我们了解算法表现究竟如何,所以,测试集的目的是给我们一种预估方法,即在没遇到的数据上算法表现将会如何。测试数据集只使用一次,即在训练完成后评价最终的模型时使用。
-
设定超参数的另一个策略是交叉验证。
-
如将训练集平均分成5份,其中4份用来训练,1份用来验证。然后循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。
针对每个k值,得到5个准确率结果,取其平均值,然后对不同k值的平均表现画线连接。本例中,当k=7的时算法表现最好(对应图中的准确率峰值)。如果将训练集分成更多份数,直线一般会更加平滑(噪音更少)。
-
-
实际应用
-
交叉验证会耗费较多的计算资源,在小数据集中更常用一些,在深度学习中不那么常用。当训练大型模型时,训练本身非常消耗计算能力,因此这个方法实际上不常用。交叉验证一般都是分成3、5和10份。
-
一般直接把训练集按照50%-90%的比例分成训练集和验证集。
给出训练集和测试集后,训练集一般会被均分。这里是分成5份。前面4份用来训练,黄色那份用作验证集调优。如果采取交叉验证,那就各份轮流作为验证集。最后模型训练完毕,超参数都定好了,让模型跑一次(而且只跑一次)测试集,以此测试结果评价算法。
-
KNN分类器的劣势
- 算法的训练不需要花时间,因为其训练过程只是将训练集数据存储起来。然而测试要花费大量时间计算,因为每个测试图像需要和所有存储的训练图像进行比较。在实际应用中,我们关注测试效率远远高于训练效率。
- 像欧几里得距离或者L1距离这样的衡量标准用在比较图像上不太合适,这种向量化的距离函数,不太适合表示图像之间视觉的相似度。
- 它并不能体现图像之间的语义差别,更多的是图像的背景,色彩的差异。
- “维度灾难”。 K-近邻分类器,它有点像是用训练数据 把样本空间分成几块,这意味着,如果我们希望分类器有好的效果,我们需要训练数据能密集地分布在空间中,否则最近邻点的实际距离可能很远,也即和待测样本的相似性没有那么高。而问题在于,想要密集地分布在空间中,我们需要指数倍地训练数据,然而我们根本不可能拿到那么多的图片去密布这样的高维空间里的像素。
线性分类
主要有两部分组成:一个是评分函数(score function),它是原始图像数据到类别分值的映射。另一个是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
线性评分函数
-
该函数将图像的像素值映射为各个分类类别的得分,得分高低代表图像属于该类别的可能性高低。
举例:在CIFAR-10中,我们有一个N=50000的训练集,每个图像有D=32x32x3=3072个像素,而K=10,这是因为图片被分为10个不同的类别(狗,猫,汽车等)。我们现在定义评分函数为: f : R D → R K f:R^{D}\to R^{K} f:RD→RK,该函数是原始图像像素到分类分值的映射。
-
一个线性映射: f ( x i , W , b ) = W x i + b f(x_{i},W,b)=Wx_{i}+b f(xi,W,b)=Wxi+b。假设每个图像数据都被拉长为一个长度为D的列向量,大小为[D x 1]。其中大小为[K x D]的矩阵W和大小为[K x 1]列向量b为该函数的参数(parameters)。参数W被称为权重(weights)。b被称为偏差向量(bias vector),这是因为它影响输出数值,但是并不和原始数据[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QD9sbT2T-1628240274868)(https://www.zhihu.com/equation?tex=x_i)]产生关联。
-
输入数据 ( x i , y i ) (x_{i},y_{i}) (xi,yi)是给定且不可改变的,但参数W和b是可控制改变的。我们的目标就是通过设置这些参数,使得计算出来的分类分值情况和训练集中图像数据的真实类别标签相符。
-
该方法的一个优势是训练数据是用来学习到参数W和b的,一旦训练完成,训练数据就可以丢弃,留下学习到的参数即可。这是因为一个测试图像可以简单地输入函数,并基于计算出的分类分值来进行分类。
-
线性分类器
-
将图像看做高维度的点
图像被伸展成为了一个高维度的列向量,可以把图像看做这个高维度空间中的一个点(即每张图像是3072维空间中的一个点)。整个数据集就是一个点的集合,每个点都带有1个分类标签。
图像空间的示意图。其中每个图像是一个点,有3个分类器。以红色的汽车分类器为例,红线表示空间中汽车分类分数为0的点的集合,红色的箭头表示分值上升的方向。所有红线右边的点的分数值均为正,且线性升高。红线左边的点分值为负,且线性降低。
-
将线性分类器看做模板匹配
关于权重W的另一个解释是它的每一行对应着一个分类的模板(有时候也叫作原型)。一张图像对应不同分类的得分,是通过使用内积(也叫点积)来比较图像和模板,然后找到和哪个模板最相似。
-
偏差和权重的合并技巧
f ( x i , W , b ) = W x i + b f(x_{i},W,b)=Wx_{i}+b f(xi,W,b)=Wxi+b简化为 f ( x i , W ) = W x i f(x_{i},W)=Wx_{i} f(xi,W)=Wxi
左边是先做矩阵乘法然后做加法,右边是将所有输入向量的维度增加1个含常量1的维度,并且在权重矩阵中增加一个偏差列,最后做一个矩阵乘法即可。左右是等价的。通过右边这样做,我们就只需要学习一个权重矩阵,而不用去学习两个分别装着权重和偏差的矩阵。
-
图像数据预处理
零均值的中心化:所有图像都是使用的原始像素值(从0到255)。在图像分类的例子中,图像上的每个像素可以看做一个特征。在实践中,对每个特征减去平均值来中心化数据,样图像的像素值就大约分布在[-127, 127]之间。。下一个常见步骤是,让所有数值分布的区间变为[-1, 1]。
损失函数
损失函数(Loss Function)(有时也叫代价函数Cost Function或目标函数Objective)来衡量对结果的不满意程度。直观地讲,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
-
多类支持向量机损失 Multiclass Support Vector Machine Loss
SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值 Δ \varDelta Δ
-
支持向量
样本中距离超平面最近的一些点,这些点叫做支持向量。
-
假设第 i i i个数据中包含图像 x i x_{i} xi的像素和代表正确类别的标签 y i y_{i} yi。评分函数输入像素数据,然后通过公式 f ( x i , W ) f(x_{i},W) f(xi,W)来计算不同分类类别的分值 s s s。则针对第 j j j个类别的得分就是第 j j j个元素: s j = f ( x i , W ) j s_{j}=f(x_{i},W)_{j} sj=f(xi,W)j,针对第 i i i个数据的多类SVM的损失函数定义为:
L i = ∑ j ≠ y j m a x ( 0 , s j − s y i + Δ ) L_{i}=\displaystyle\sum_{j \not = y_{j}}max(0,s_{j}-s_{y_{i}}+\varDelta) Li=j=yj∑max(0,sj−syi+Δ)
对于线性评分函数 f ( x i , W ) = W x i f(x_{i},W)=Wx_{i} f(xi,W)=Wxi,损失函数改写为
L i = ∑ j ≠ y j m a x ( 0 , w j T x i − w y j T x i + Δ ) L_{i}=\displaystyle\sum_{j \not = y_{j}}max(0,w^{T}_{j}x_{i}-w^{T}_{y_{j}}x_{i}+\varDelta) Li=j=yj∑max(0,wjTxi−wyjTxi+Δ)
其中 w j w_{j} wj是权重[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RTqVvlfS-1628240274870)(https://www.zhihu.com/equation?tex=W)]的第j行,被变形为列向量。
【 m a x ( 0 , − ) max(0,-) max(0,−)函数常被称为折叶损失(hinge loss)。】
多类SVM想要正确类别的分类分数比其他不正确分类类别的分数要高,而且至少高出 Δ \varDelta Δ的边界值。如果其他分类分数进入了红色的区域,甚至更高,那么就开始计算损失。如果没有这些情况,损失值为0。我们的目标是找到一些权重,它们既能够让训练集中的数据样例满足这些限制,也能让总的损失值尽可能地低。
-
-
正则化
当能正确分类每个数据的权重集W不唯一时,我们希望能向某些特定的权重W添加一些偏好,对其他权重则不添加,以此来消除模糊性。方法是向损失函数增加一个正则化惩罚(regularization penalty)。最常用的正则化惩罚是L2范式,L2范式通过对所有参数进行逐元素的平方惩罚来抑制大数值的权重。
L = 1 N ∑ i ∑ j ≠ y j [ m a x ( 0 , f ( x i ; W ) j − f ( x i ; W ) y i + Δ ) ] + λ ∑ k ∑ l W k , l 2 L=\frac{1}{N}\displaystyle\sum_{i}\displaystyle\sum_{j \not = y_{j}}[max(0,f(x_{i};W)_{j}-f(x_{i};W)_{y_{i}}+\varDelta)]+\lambda \displaystyle\sum_{k}\displaystyle\sum_{l}W^{2}_{k,l} L=N1i∑j=yj∑[max(0,f(xi;W)j−f(xi;W)yi+Δ)]+λk∑l∑Wk,l2
完整的多类SVM损失函数由两个部分组成:数据损失(data loss),即所有样例的的平均损失 L i L_{i} Li,以及正则化损失(regularization loss)。其中,N是训练集的数据量。现在正则化惩罚添加到了损失函数里面,并用超参数 λ \lambda λ来计算其权重。该超参数无法简单确定,需要通过交叉验证来获取。
- 好处:SVM们就有了**最大边界(max margin)**这一良好性质。对大数值权重进行惩罚,可以提升其泛化能力,并避免过拟合
- 正则化函数不是数据的函数,仅基于权重。
- 和权重不同,偏差没有这样的效果,因为它们并不控制输入维度上的影响强度。因此通常只对权重W正则化,而不正则化偏差b。
- 因为正则化惩罚的存在,不可能在所有的例子中得到0的损失值,这是因为只有当W=0的特殊情况下,才能得到损失值为0。
-
SVM和Softmax的比较
SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。
- Softmax分类器为每个分类提供了“可能性”。SVM的计算是无标定的,而且难以针对所有分类的评分值给出直观解释。Softmax分类器则不同,它允许我们计算出对于所有分类标签的可能性。
- 在实际使用中,SVM和Softmax经常是相似的。
- 相对于Softmax分类器,SVM更加“局部目标化(local objective)”,这既可以看做是一个特性,也可以看做是一个劣势。SVM对于数字个体的细节是不关心的:如果分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没设么不同,只要满足超过边界值等于1,那么损失值就等于0。
- 对于softmax分类器,情况则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。softmax分类器中正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。
反向传播中的梯度计算
简单表达式和理解梯度
-
一个二元乘法函数 f ( x , y ) = x y f(x,y)=xy f(x,y)=xy,对于两个输入变量分别求偏导:
d f d x = y \frac{df}{dx}=y dxdf=y d f d y = x \frac{df}{dy}=x dydf=x
-
导数的意义:函数变量在某个点周围的极小区域内变化,而导数就是变量变化导致的函数在该方向上的变化率。
-
函数关于每个变量的导数指明了整个表达式对于该变量的敏感程度。
使用链式法则计算复合表达式
-
如 f ( x , y , z ) = ( x + y ) z f(x,y,z)=(x+y)z f(x,y,z)=(x+y)z,反向传播方法为:将公式分为两部分: q = x + y q=x+y q=x+y和 f = q z f=qz f=qz。由链式法则得出 ∂ f ∂ x = ∂ f ∂ q ∂ q ∂ x = z \frac{\partial f}{\partial x}=\frac{\partial f}{\partial q}\frac{\partial q}{\partial x}=z ∂x∂f=∂q∂f∂x∂q=z
-
前向传播从输入计算到输出(绿色),反向传播从尾部开始,根据链式法则递归地向前计算梯度(显示为红色),一直到网络的输入端。可以认为,梯度是从计算链路中回流。
模块化:Sigmoid例子
-
sigmoid函数 σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1,对其输入求导:
d σ ( x ) d x = d σ ( x ) d ( 1 + e − x ) d ( 1 + e − x ) d e − x d e − x d x = e − x ( 1 + e − x ) 2 = ( 1 + e − x − 1 1 + e − x ) ( 1 1 + e − x ) = ( 1 − σ ( x ) ) σ ( x ) \frac{d \sigma(x)}{dx}=\frac{d\sigma(x)}{d(1+e^{-x})}\frac{d(1+e^{-x})}{de^{-x}}\frac{de^{-x}}{dx}=\frac{e^{-x}}{(1+e^{-x})^{2}}=(\frac{1+e^{-x}-1}{1+e^{-x}})(\frac{1}{1+e^{-x}})=(1-\sigma (x))\sigma (x) dxdσ(x)=d(1+e−x)dσ(x)de−xd(1+e−x)dxde−x=(1+e−x)2e−x=(1+e−x1+e−x−1)(1+e−x1)=(1−σ(x))σ(x)
-
一个含输入x和权重w的2维的神经元,该神经元使用了sigmoid激活函数表达式: f ( w , x ) = 1 1 + e − ( w 0 x 0 + w 1 x 1 + w 2 ) f(w,x)=\frac{1}{1+e^{-(w_{0}x_{0}+w_{1}x_{1}+w_{2})}} f(w,x)=1+e−(w0x0+w1x1+w2)1,分别对其权重求导:
d f ( w , x ) d w 0 = d f ( w , x ) d ( w 0 x 0 + w 1 x 1 + w 2 ) d ( w 0 x 0 + w 1 x 1 + w 2 ) d w 0 = x 0 ( 1 − f ( w , x ) ) f ( w , x ) \frac{df(w,x)}{dw_{0}}=\frac{df(w,x)}{d(w_{0}x_{0}+w_{1}x_{1}+w_{2})}\frac{d(w_{0}x_{0}+w_{1}x_{1}+w_{2})}{dw_{0}}=x_{0}(1-f(w,x))f(w,x) dw0df(w,x)=d(w0x0+w1x1+w2)df(w,x)dw0d(w0x0+w1x1+w2)=x0(1−f(w,x))f(w,x)
d f ( w , x ) d w 1 = d f ( w , x ) d ( w 0 x 0 + w 1 x 1 + w 2 ) d ( w 0 x 0 + w 1 x 1 + w 2 ) d w 1 = x 1 ( 1 − f ( w , x ) ) f ( w , x ) \frac{df(w,x)}{dw_{1}}=\frac{df(w,x)}{d(w_{0}x_{0}+w_{1}x_{1}+w_{2})}\frac{d(w_{0}x_{0}+w_{1}x_{1}+w_{2})}{dw_{1}}=x_{1}(1-f(w,x))f(w,x) dw1df(w,x)=d(w0x0+w1x1+w2)df(w,x)dw1d(w0x0+w1x1+w2)=x1(1−f(w,x))f(w,x)
d f ( w , x ) d w 2 = d f ( w , x ) d ( w 0 x 0 + w 1 x 1 + w 2 ) d ( w 0 x 0 + w 1 x 1 + w 2 ) d w 2 = ( 1 − f ( w , x ) ) f ( w , x ) \frac{df(w,x)}{dw_{2}}=\frac{df(w,x)}{d(w_{0}x_{0}+w_{1}x_{1}+w_{2})}\frac{d(w_{0}x_{0}+w_{1}x_{1}+w_{2})}{dw_{2}}=(1-f(w,x))f(w,x) dw2df(w,x)=d(w0x0+w1x1+w2)df(w,x)dw2d(w0x0+w1x1+w2)=(1−f(w,x))f(w,x)
反向传播实践:分段计算
-
假设有一函数 f ( x , y ) = x + σ ( y ) σ ( x ) + ( x + y ) 2 f(x,y)=\frac{x+\sigma(y)}{\sigma(x)+(x+y)^2} f(x,y)=σ(x)+(x+y)2x+σ(y),对 x x x和 y y y进行梯度计算。
-
令 a = x + σ ( y ) a=x+\sigma(y) a=x+σ(y), b = σ ( x ) + ( x + y ) 2 b=\sigma(x)+(x+y)^2 b=σ(x)+(x+y)2,则 f ( x , y ) = a b f(x,y)=\frac{a}{b} f(x,y)=ba
-
d f ( x , y ) d x = d f ( x , y ) d a d a d x + d f ( x , y ) d b d b d x = 1 b + ( − a b 2 ) [ ( 1 − σ ( x ) ) σ ( x ) + 2 ( x + y ) ] = σ ( x ) + ( x + y ) 2 − ( x + σ ( y ) ) [ ( 1 − σ ( x ) ) σ ( x ) + 2 ( x + y ) ] ( σ ( x ) + ( x + y ) 2 ) 2 \frac{df(x,y)}{dx}=\frac{df(x,y)}{da}\frac{da}{dx}+\frac{df(x,y)}{db}\frac{db}{dx}=\frac{1}{b}+(-\frac{a}{b^{2}})[(1-\sigma(x))\sigma(x)+2(x+y)]=\frac{\sigma(x)+(x+y)^2-(x+\sigma(y))[(1-\sigma(x))\sigma(x)+2(x+y)]}{(\sigma(x)+(x+y)^2)^{2}} dxdf(x,y)=dadf(x,y)dxda+dbdf(x,y)dxdb=b1+(−b2a)[(1−σ(x))σ(x)+2(x+y)]=(σ(x)+(x+y)2)2σ(x)+(x+y)2−(x+σ(y))[(1−σ(x))σ(x)+2(x+y)]
d f ( x , y ) d y = d f ( x , y ) d a d a d y + d f ( x , y ) d b d b d y = ( 1 − σ ( y ) ) σ ( y ) b + ( − a b 2 ) [ 2 ( x + y ) ] = [ σ ( x ) + ( x + y ) 2 ] ( 1 − σ ( y ) ) σ ( y ) − ( x + σ ( y ) ) 2 ( x + y ) ( σ ( x ) + ( x + y ) 2 ) 2 \frac{df(x,y)}{dy}=\frac{df(x,y)}{da}\frac{da}{dy}+\frac{df(x,y)}{db}\frac{db}{dy}=\frac{(1-\sigma(y))\sigma(y)}{b}+(-\frac{a}{b^{2}})[2(x+y)]=\frac{[\sigma(x)+(x+y)^2](1-\sigma(y))\sigma(y)-(x+\sigma(y))2(x+y)}{(\sigma(x)+(x+y)^2)^{2}} dydf(x,y)=dadf(x,y)dyda+dbdf(x,y)dydb=b(1−σ(y))σ(y)+(−b2a)[2(x+y)]=(σ(x)+(x+y)2)2[σ(x)+(x+y)2](1−σ(y))σ(y)−(x+σ(y))2(x+y)
-
-
对前向传播变量进行缓存,在不同分支的梯度要相加
回传流中的模式
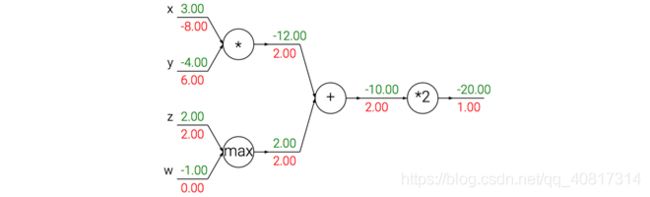
一个展示反向传播的例子。加法操作将梯度相等地分发给它的输入。取最大操作将梯度路由给更大的输入。乘法门拿取输入激活数据,对它们进行交换,然后乘以梯度。
- 加法门单元把输出的梯度相等地分发给它所有的输入,这一行为与输入值在前向传播时的值无关。
- 取最大值门单元对梯度做路由。和加法门不同,取最大值门将梯度转给在前向传播中值最大的那个输入,其余的是0。上例中,取最大值门将梯度2.00转给了z变量,因为z的值比w高,于是w的梯度保持为0。
- 乘法门单元的局部梯度就是输入值,但是是相互交换之后的,然后根据链式法则乘以输出值的梯度。上例中,x的梯度是 − 4.00 × 2.00 = − 8.00 -4.00\times2.00=-8.00 −4.00×2.00=−8.00。
神经网络
单个神经元建模
-
一个神经元前向传播的代码实现
class Neuron(object): # ... def forward(inputs): """ 假设输入和权重是1-D的numpy数组,偏差是一个数字 """ cell_body_sum = np.sum(inputs * self.weights) + self.bias firing_rate = 1.0 / (1.0 + math.exp(-cell_body_sum)) # sigmoid激活函数 return firing_rate每个神经元都对它的输入和权重进行点积,然后加上偏差,最后使用非线性函数(或称为激活函数)。
作为线性分类器的单个神经元
-
二分类Softmax分类器
举例:可以把 σ ( ∑ i w i x i + b ) \sigma(\sum_{i}w_{i}x_{i}+b) σ(∑iwixi+b)看做其中一个分类的概率 P ( y i = 1 ∣ x i , w ) P(y_{i}=1|x_{i},w) P(yi=1∣xi,w),其他分类的概率为 P ( y i = 0 ∣ x i , w ) = 1 − P ( y i = 1 ∣ x i , w ) P(y_{i}=0|x_{i},w)=1-P(y_{i}=1|x_{i},w) P(yi=0∣xi,w)=1−P(yi=1∣xi,w)。可以得到交叉熵损失,然后将它最优化为二分类的Softmax分类器(也就是逻辑回归)。因为sigmoid函数输出限定在0-1之间,所以分类器做出预测的基准是神经元的输出是否大于0.5。
-
二分类SVM分类器
可以在神经元的输出外增加一个最大边界折叶损失(max-margin hinge loss)函数,将其训练成一个二分类的支持向量机。
-
在SVM/Softmax中,正则化损失从生物学角度可以看做逐渐遗忘,因为它的效果是让所有突触权重 w w w在参数更新过程中逐渐向着0变化。
常用激活函数
-
Sigmoid
σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1
- 优点:对于神经元的激活频率有良好的解释:从完全不激活(0)到在求和后的最大频率处的完全饱和(saturated)的激活(1)
- 缺点:
- Sigmoid函数饱和使梯度消失。当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。
- Sigmoid函数的输出不是零中心的。这一情况将影响梯度下降,导致梯度下降权重更新时出现z字型的下降,收敛速度很慢。
-
Tanh
t a n h ( x ) = 2 σ ( 2 x ) − 1 tanh(x)=2\sigma(2x)-1 tanh(x)=2σ(2x)−1
它将实数值压缩到[-1,1]之间。和sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。
左边是Sigmoid非线性函数,将实数压缩到[0,1]之间。右边是tanh函数,将实数压缩到[-1,1]。
-
ReLU
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
- 优点:相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用
- 缺点:在训练的时候,ReLU单元比较脆弱并且可能“死掉”(这个神经元的输入永远都小于0,所以就不会被激活,也不会产生梯度更新)。
- 解决方法:通过设置非常小的学习率可以降低Relu神经元出现“死亡”的概率。
-
Leaky ReLU
Leaky ReLU是为解决“ReLU死亡”问题的尝试。ReLU中当x<0时,函数值为0。而Leaky ReLU则是给出一个很小的负数梯度值,比如0.01。
-
Maxout
f ( x ) = m a x ( w 1 T x + b 1 , w 2 T x + b 2 ) f(x)=max(w^{T}_{1}x+b_{1},w^{T}_{2}x+b_{2}) f(x)=max(w1Tx+b1,w2Tx+b2)
Maxout是对ReLU和leaky ReLU的一般化归纳,ReLU和Leaky ReLU都是这个公式的特殊情况(比如ReLU就是当 w 1 , b 1 = 0 w_{1},b_{1}=0 w1,b1=0的时候)。
- 优点:拥有ReLU单元的所有优点(线性操作和不饱和),而没有它的缺点(死亡的ReLU单元)。
- 缺点:和ReLU对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
-
【ReLu函数为最佳推荐】
神经网络结构
-
层组织
-
神经元之间以无环图的形式进行连接,一些神经元的输出是另一些神经元的输入。在网络中是不允许循环的,因为这样会导致前向传播的无限循环。通常神经网络模型中神经元是分层的,而不是像生物神经元一样聚合成大小不一的团状。
-
左边是一个2层神经网络,隐层由4个神经元(也可称为单元(unit))组成,输出层由2个神经元组成,输入层是3个神经元。右边是一个3层神经网络,两个含4个神经元的隐层。注意:层与层之间的神经元是全连接的,但是层内的神经元不连接。
-
分层的结构能够让神经网络高效地进行矩阵乘法和激活函数运算。
-
-
设置层的数量和尺寸
-
当增加层的数量和尺寸时,网络的容量上升了。即神经元们可以合作表达许多复杂函数,所以表达函数的空间增加。
-
然而有更多神经元的神经网络可能造成对数据的过拟合。**过拟合(Overfitting)**是网络对数据中的噪声有很强的拟合能力,而没有重视数据间的潜在基本关系。
-
防止神经网络的过拟合有很多方法(L2正则化,dropout和输入噪音等)。在实践中,使用这些方法来控制过拟合比减少网络神经元数目要好得多。
-
不要减少网络神经元数目的主要原因在于小网络更难使用梯度下降等局部方法来进行训练。虽然小型网络的损失函数的局部极小值更少,也比较容易收敛到这些局部极小值,但是这些最小值一般都很差,损失值很高。相反,大网络拥有更多的局部极小值,但就实际损失值来看,这些局部极小值表现更好,损失更小。
-
不同正则化强度的效果:随着正则化强度增加,它的决策边界变得更加平滑。
-
-
【不应该因为害怕出现过拟合而使用小网络。相反,应该进尽可能使用大网络,然后使用正则化技巧来控制过拟合。】
-
设置数据和模型
-
数据预处理
- 均值减法(Mean subtraction是预处理最常用的形式。它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据云的中心都迁移到原点。
- 归一化(Normalization是指将数据的所有维度都归一化,使其数值范围都近似相等。
- 第一种是先对数据做零中心化(zero-centered)处理,然后每个维度都除以其标准差。实现代码为X /= np.std(X, axis=0)
- 第二种方法是对每个维度都做归一化,使得每个维度的最大和最小值是1和-1。
- PCA和白化(Whitening)是另一种预处理形式。在这种处理中,先对数据进行零中心化处理,然后计算协方差矩阵,它展示了数据中的相关性结构。
-
权重初始化
-
错误:全零初始化。
因为如果网络中的每个神经元都计算出同样的输出,然后它们就会在反向传播中计算出同样的梯度,从而进行同样的参数更新。换句话说,如果权重被初始化为同样的值,神经元之间就失去了不对称性的源头。
-
小随机数初始化。
方法是将权重初始化为很小的数值,以此来打破对称性。其思路是:如果神经元刚开始的时候是随机且不相等的,那么它们将计算出不同的更新,并将自身变成整个网络的不同部分。
-
存在问题:随着输入数据量的增长,随机初始化的神经元的输出数据的分布中的方差也在增大。
-
解决方法:使用1/sqrt(n)校准方差。将神经元的权重向量初始化为:w = np.random.randn(n) / sqrt(n)。其中n是输入数据的数量。这样就保证了网络中所有神经元起始时有近似同样的输出分布。
-
-
稀疏初始化(Sparse initialization)
将所有权重矩阵设为0,但是为了打破对称性,每个神经元都同下一层固定数目的神经元随机连接(其权重数值由一个小的高斯分布生成)。一个比较典型的连接数目是10个。
-
偏置(biases)的初始化
通常将偏置初始化为0,这是因为随机小数值权重矩阵已经打破了对称性。
-
【当前的推荐是使用ReLU激活函数,并且使用w = np.random.randn(n) * sqrt(2.0/n)(标准差为 2 / n \sqrt{2/n} 2/n的高斯分布, n n n为输入神经元数)来进行权重初始化】
-
-
批量归一化(Batch Normalization)
- 做法是让激活数据在训练开始前通过一个网络,网络处理数据使其服从标准高斯分布。该方法减轻了如何合理初始化神经网络这个问题。
- 通常在全连接层(或者是卷积层)与激活函数之间添加一个BatchNorm层。
- 批量归一化可以理解为在网络的每一层之前都做预处理,只是这种操作以另一种方式与网络集成在了一起。
-
正则化 Regularization
-
L2正则化
对于网络中的每个权重 w w w,向目标函数中增加一个 1 2 λ w 2 \frac{1}{2}\lambda w^{2} 21λw2,其中 λ \lambda λ是正则化强度。
- L2正则化可以理解为它对于大数值的权重向量进行严厉惩罚,倾向于更加分散的权重向量。
- 优点:使网络更倾向于使用所有输入特征,而不是严重依赖输入特征中某些小部分特征。
- 注意:在梯度下降和参数更新的时候,使用L2正则化意味着所有的权重都以w += -lambda * W向着0线性下降。
-
L1正则化
对于每个 w w w向目标函数增加一个 λ ∣ w ∣ \lambda|w| λ∣w∣。
- 性质:会让权重向量在最优化的过程中变得稀疏(即非常接近0)。即使用L1正则化的神经元最后使用的是它们最重要的输入数据的稀疏子集,同时对于噪音输入则几乎是不变的了。
- 如果不是特别关注某些明确的特征选择,一般说来L2正则化都会比L1正则化效果好。
-
Elastic net regularization
将L2正则化和L1正则化组合在一起: λ 1 ∣ w ∣ + λ 2 w 2 \lambda_{1}|w|+\lambda_{2}w^{2} λ1∣w∣+λ2w2
-
最大范式约束
参数更新方式不变,要求神经元中的权重向量 w → \overrightarrow{w} w必须满足 ∣ ∣ w → ∣ ∣ 2 < c ||\overrightarrow{w}||_{2}
∣∣w∣∣2<c ,一般 c c c值为3或4。- 优点:即使在学习率设置过高的时候,网络中也不会出现数值“爆炸”,这是因为它的参数更新始终是被限制着的。
-
随机失活(Dropout)
实现方法是让神经元以超参数 p p p的概率被激活或者被设置为0。
-
普通随机失活的缺点:必须在测试时对激活数据要按照 p p p进行数值范围调整。
-
解决方法:反向随机失活(inverted dropout)。它是在训练时就进行数值范围调整,从而让前向传播在测试时保持不变。无论决定是否使用随机失活,预测方法的代码可以保持不变。
代码实现:
""" 反向随机失活 在训练的时候drop和调整数值范围,测试时不做任何事. """ p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱 def train_step(X): # 3层neural network的前向传播 H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = (np.random.rand(*H1.shape) < p) / p # 第一个随机失活遮罩. 注意/p! H1 *= U1 # drop! H2 = np.maximum(0, np.dot(W2, H1) + b2) U2 = (np.random.rand(*H2.shape) < p) / p # 第二个随机失活遮罩. 注意/p! H2 *= U2 # drop! out = np.dot(W3, H2) + b3 # 反向传播:计算梯度... (略) # 进行参数更新... (略) def predict(X): # 前向传播时模型集成 H1 = np.maximum(0, np.dot(W1, X) + b1) # 不用数值范围调整了 H2 = np.maximum(0, np.dot(W2, H1) + b2) out = np.dot(W3, H2) + b3
-
-
-
损失函数
损失函数的一部分是正则化损失部分,另一部分是数据损失,它是一个有监督学习问题,用于衡量分类算法的预测结果(即分类评分)和真实标签结果之间的一致性。数据损失是对所有样本的数据损失求平均,即 L = 1 N ∑ i L i L=\frac{1}{N}\displaystyle\sum_{i}L_{i} L=N1i∑Li。其中, N N N是训练集数据的样本数。
- 分类问题:一个装满样本的数据集,每个样本都有一个唯一的正确标签(是固定分类标签之一)。
- SVM: L i = ∑ j ≠ y j m a x ( 0 , f j − f y j + 1 ) L_{i}=\displaystyle\sum_{j \not = y_{j}}max(0,f_{j}-f_{y_{j}}+1) Li=j=yj∑max(0,fj−fyj+1)
- Softmax分类器: L i = l o g ( e f y i ∑ j e f j ) L_{i}=log(\frac{e^{f_{y_{i}}}}{\sum_{j}e^{f_{j}}}) Li=log(∑jefjefyi)
- 回归问题:预测实数的值的问题。对于这种问题,通常是计算预测值和真实值之间的损失。然后用L2平方范式或L1范式度量差异。
- 注意
- L2损失比起较为稳定的Softmax损失,其最优化过程要困难很多。它需要网络对于每个输入(和增量)都要输出一个确切的正确值。而在Softmax中每个评分的准确值并不是那么重要:只有当它们量级适当的时候,才有意义。
- L2损失鲁棒性不好,因为异常值可以导致很大的梯度。在面对一个回归问题时,先考虑将输出变成二值化是否真的不够用,再考虑使用L2损失。
- 分类问题:一个装满样本的数据集,每个样本都有一个唯一的正确标签(是固定分类标签之一)。
梯度检查
-
使用中心化公式
d f ( x ) d x = f ( x + h ) − f ( x − h ) 2 h \frac{df(x)}{dx}=\frac{f(x+h)-f(x-h)}{2h} dxdf(x)=2hf(x+h)−f(x−h)
该公式在检查梯度的每个维度的时候,会要求计算两次损失函数(所以计算资源的耗费也是两倍),但是梯度的近似值会准确很多。
-
使用相对误差来比较
比较数值梯度 f n ′ f^{'}_{n} fn′和解析梯度 f a ′ f^{'}_{a} fa′使用相对误差:
∣ f a ′ − f n ′ ∣ m a x ( ∣ f a ′ ∣ , ∣ f n ′ ∣ ) \frac{|f^{'}_{a}-f^{'}_{n}|}{max(|f^{'}_{a}|,|f^{'}_{n}|)} max(∣fa′∣,∣fn′∣)∣fa′−fn′∣
- 相对误差>1e-2:通常就意味着梯度可能出错。
- 1e-2>相对误差>1e-4:不舒服。
- 1e-4>相对误差:对于有不可导点的目标函数是OK的,但如果目标函数中没有不可导点(使用tanh和softmax),那么相对误差值还是太高。
- 1e-7或者更小:好结果
【数值梯度:通过对自变量的微小变动,来计算其导数。有限元法、数值逼近、插值法等。数值解只能根据给定的数字求出对应的梯度。计算方便但是很慢。 d f ( x ) d x = lim h → 0 f ( x + h ) − f ( x ) h \frac{df(x)}{dx}=\lim\limits_{h \to 0}\frac{f(x+h)-f(x)}{h} dxdf(x)=h→0limhf(x+h)−f(x)
解析梯度:根据公式来计算的,也就是方程求解,对于任意自变量都能得到结果。通过公式运算、较快、准确但是可能出错】
-
使用双精度
-
保持浮点数的有效范围
-
目标函数的不可导点(kinks)
解决方法:使用少量数据点
-
谨慎设置步长。步长过小可能遇到数值精度问题。
-
不要让正则化吞没数据。
【先关掉正则化,对数据损失做单独检查,然后对正则化做单独检查。对于正则化的单独检查可以是修改代码,去掉其中数据损失的部分,也可以提高正则化强度,确认其效果在梯度检查中是无法忽略的,这样不正确的实现就会被观察到了。】
-
进行梯度检查时,记得关闭网络中任何不确定的效果的操作,比如随机失活,随机数据扩展等。解决方法是:在计算 f ( x + h ) f(x+h) f(x+h)和 f ( x − h ) f(x-h) f(x−h)前强制增加一个特定的随机种子,在计算解析梯度时也同样如此。
-
检查少量梯度。不要随机地从向量中取维度,一定要把这种情况考虑到,确保所有参数都收到了正确的梯度。
学习之前合理性检查
-
寻找特定情况的正确损失值
在使用小参数进行初始化时,确保得到的损失值与期望一致。最好先单独检查数据损失(让正则化强度为0)。
-
提高正则化强度时导致损失值变大。
-
对小数据子集过拟合
在整个数据集进行训练之前,尝试在一个很小的数据集上进行训练(比如20个数据),然后确保能到达0的损失值。进行这个实验的时候,最好让正则化强度为0,不然它会阻止得到0的损失。
检查学习过程
-
损失函数
-
过低的学习率导致算法的改善是线性的。高一些的学习率会看起来呈几何指数下降,更高的学习率会让损失值很快下降,但是接着就停在一个不好的损失值上(绿线)。因为最优化的“能量”太大,参数在混沌中随机震荡,不能最优化到一个很好的点上。
-
损失值的震荡程度和批尺寸(batch size)有关,当批尺寸为1,震荡会相对较大。当批尺寸就是整个数据集时震荡就会最小,因为每个梯度更新都是单调地优化损失函数(除非学习率设置得过高)。
-
-
权重更新比例
-
跟踪的量是权重中更新值的数量和全部值的数量之间的比例。
【这个比例应该在1e-3左右。如果更低,说明学习率可能太小,如果更高,说明学习率可能太高。】
-
代码实现
# 假设参数向量为W,其梯度向量为dW param_scale = np.linalg.norm(W.ravel()) update = -learning_rate*dW # 简单SGD更新 update_scale = np.linalg.norm(update.ravel()) W += update # 实际更新 print update_scale / param_scale # 要得到1e-3左右
-
-
可视化
左图中的特征充满了噪音,这暗示了网络可能出现了问题:网络没有收敛,学习率设置不恰当,正则化惩罚的权重过低。
右图的特征不错,平滑,干净而且种类繁多,说明训练过程进行良好。
参数更新
-
一阶(随机梯度下降)方法
-
普通更新
# 普通更新 x += - learning_rate * dx当在整个数据集上进行计算时,只要学习率足够低,总是能在损失函数上得到非负的进展。
-
动量更新
# 动量更新 v = mu * v - learning_rate * dx # 与速度融合 x += v # 与位置融合引入了一个初始化为0的变量v和一个动量超参数mu【刚开始将动量设为0.5而在后面的多个周期(epoch)中慢慢提升到0.99】
通过动量更新,参数向量会在任何有持续梯度的方向上增加速度。
-
Nesterov动量更新
x_ahead = x + mu * v # 计算dx_ahead(在x_ahead处的梯度,而不是在x处的梯度) v = mu * v - learning_rate * dx_ahead x += v
-
-
学习率退火
如果学习率很高,系统的动能就过大,参数向量就会无规律地跳动,不能够稳定到损失函数更深更窄的部分去。
-
随步数衰减:每进行几个周期就根据一些因素降低学习率。
【使用一个固定的学习率来进行训练的同时观察验证集错误率,每当验证集错误率停止下降,就乘以一个常数(比如0.5)来降低学习率。】
-
指数衰减: α = α 0 w − k t \alpha=\alpha _{0}w^{-kt} α=α0w−kt,其中 α 0 , k \alpha_{0},k α0,k为超参数, t t t是迭代次数(也可以使用周期作为单位)。
-
1 / t 1/t 1/t衰减: α = α 0 / ( 1 + k t ) \alpha=\alpha _{0}/(1+kt) α=α0/(1+kt),其中 α 0 , k \alpha_{0},k α0,k为超参数, t t t是迭代次数。
-
-
二阶方法
x ← x − [ H f ( x ) ] − 1 ▽ f ( x ) x\leftarrow x-[Hf(x)]^{-1}\triangledown f(x) x←x−[Hf(x)]−1▽f(x)
其中 [ H f ( x ) ] [Hf(x)] [Hf(x)]是Hessian矩阵,它是函数的二阶偏导数的平方矩阵。 ▽ f ( x ) \triangledown f(x) ▽f(x)是梯度向量。
- Hessian矩阵描述了损失函数的局部曲率,从而使得可以进行更高效的参数更新。因此,乘以Hessian转置矩阵可以让最优化过程在曲率小的时候大步前进,在曲率大的时候小步前进。
- 相较于一阶方法的优势:没有学习率这个超参数
- 缺点:计算(以及求逆)Hessian矩阵操作非常耗费时间和空间
-
逐参数适应学习率方法
-
Adagrad
# 假设有梯度和参数向量x cache += dx**2 x += - learning_rate * dx / (np.sqrt(cache) + eps)变量cache的尺寸和梯度矩阵的尺寸是一样的,还跟踪了每个参数的梯度的平方和。用于平滑的式子eps(一般设为1e-4到1e-8之间)是防止出现除以0的情况。
- 接收到高梯度值的权重更新的效果被减弱,而接收到低梯度值的权重的更新效果将会增强。
- 缺点:通常过于激进且过早停止学习。
-
RMSprop
cache = decay_rate * cache + (1 - decay_rate) * dx**2 x += - learning_rate * dx / (np.sqrt(cache) + eps)decay_rate是一个超参数,常用的值是[0.9,0.99,0.999]。
- RMSProp仍然是基于梯度的大小来对每个权重的学习率进行修改
- 优点:其更新不会让学习率单调变小。
-
Adam
m = beta1*m + (1-beta1)*dx v = beta2*v + (1-beta2)*(dx**2) x += - learning_rate * m / (np.sqrt(v) + eps)【推荐的参数值eps=1e-8, beta1=0.9, beta2=0.999。】
左边是一个损失函数的等高线图,右边展示了一个马鞍状的最优化地形,其中对于不同维度它的曲率不同(一个维度下降另一个维度上升)。
-
超参数调优
- 初始学习率
- 学习率的衰减方式(例如一个衰减常量)
- 正则化强度(L2惩罚,Dropout强度)
评价
-
模型集成
在训练的时候训练几个独立的模型,然后在测试的时候平均它们预测结果。集成的模型数量增加,算法的结果也单调提升(但提升效果越来越少)。模型之间的差异度越大,提升效果可能越好。
集成的方法:
- 同一个模型,不同的初始化。使用交叉验证来得到最好的超参数,然后用最好的参数来训练不同初始化条件的模型。这种方法的风险在于多样性只来自于不同的初始化条件。
- 在交叉验证中发现最好的模型。使用交叉验证来得到最好的超参数,然后取其中最好的几个(比如10个)模型来进行集成。这样就提高了集成的多样性,但风险在于可能会包含不够理想的模型。在实际操作中,这样操作起来比较简单,在交叉验证后就不需要额外的训练了。
- 一个模型设置多个记录点。如果训练非常耗时,那就在不同的训练时间对网络留下记录点(比如每个周期结束),然后用它们来进行模型集成。这样做多样性不足,优势是代价比较小。
- 在训练的时候跑参数的平均值。在训练过程中,如果损失值相较于前一次权重出现指数下降时,就在内存中对网络的权重进行一个备份。这样对前几次循环中的网络状态进行平均,得到的权重总是能得到更少的误差。
模型集成的一个劣势就是在测试数据的时候会花费更多时间。
总结
训练一个神经网络需要:
- 利用小批量数据对实现进行梯度检查,还要注意各种错误。
- 进行合理性检查,确认初始损失值是合理的,在小数据集上能得到100%的准确率。
- 在训练时,跟踪损失函数值,训练集和验证集准确率,如果愿意,还可以跟踪更新的参数量相对于总参数量的比例(一般在1e-3左右),然后如果是对于卷积神经网络,可以将第一层的权重可视化。
- 推荐的两个更新方法是SGD+Nesterov动量方法,或者Adam方法。
- 随着训练进行学习率衰减。比如,在固定多少个周期后让学习率减半,或者当验证集准确率下降的时候。
- 使用随机搜索(不要用网格搜索)来搜索最优的超参数。分阶段从粗(比较宽的超参数范围训练1-5个周期)到细(窄范围训练很多个周期)地来搜索。
- 进行模型集成来获得额外的性能提高。