推荐算法(一)电影推荐系统
目录
一、推荐系统基本概念
1. 基于内容的推荐系统
2. 基于矩阵分解的协同过滤
3. 基于item的协同过滤
4. 基于用户的协同过滤
5. 冷启动问题 cold start
6. 混合算法
7. 推荐系统性能评估
线下评估
线上评估
二、使用TF构建电影推荐系统
1. 数据收集
2. 数据准备
3. 构建模型
4. 模型训练
5. 模型评估
6. 构建完整的电影推荐系统
一、推荐系统基本概念
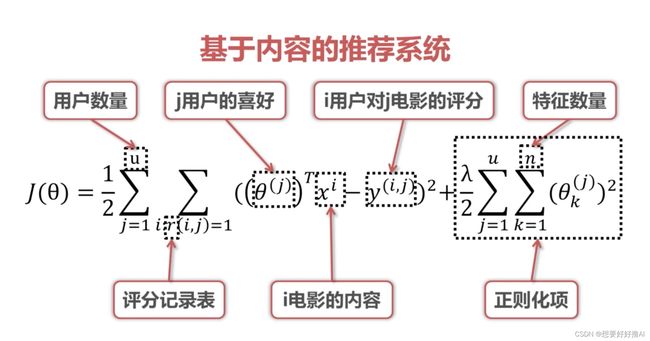
1. 基于内容的推荐系统
给定电影部分评分表和电影内容矩阵X,求解用户喜好矩阵theta:
- 评分记录表:i用户对j电影是否评分了
- j用户喜好 * i电影内容 = 预测j用户对i电影的评分
- 正则化项:通过调整lambda防止theta构成的模型对原始数据集产生过拟合
优点:
- 不存在商品冷启动
- 明确告诉用户推荐的商品包含哪些属性
缺点:
- 需要透彻的内容分析
- 很少给用户带来惊喜
- 存在用户冷启动
2. 基于矩阵分解的协同过滤
给定电影部分评分表和用户喜好矩阵theta,求解电影内容矩阵X,再将theta和X相乘,得到完整的电影评分表:

同时求解X和theta,将以上两个公式合并为:

给定电影内容矩阵X,用户喜好矩阵theta,如何给用户A推荐电影?
- 看用户A看过哪些电影,然后找到电影内容矩阵X找到与之相似的电影,然后推荐给用户A
- 使用用户喜好矩阵theta找到与用户A相似的其他用户,将其他用户看过的电影推荐给用户A
如何计算两部电影之间的相似度?
- 每个电影或每个用户可以用向量表示,将每个向量想象成高维空间的一个点,两点之间距离来度量两个实例之间的相似性
优点:
- 能够根据用户的历史信息推断商品质量
- 不需要对商品有任何专业领域知识
缺点:
- 冷启动问题
- gray sheep 如果没有其他相似用户,就无法推荐
- 复杂度会随着商品数量和用户数量的增加而增加
- 同义词的影响
- shilling attack 刷分
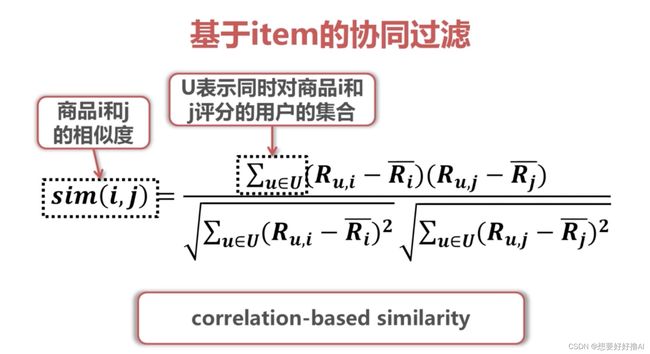
3. 基于item的协同过滤
先计算商品之间的相似度:
再预测用户对商品的评分,将其进行排序,选择评分高的商品推荐给用户:

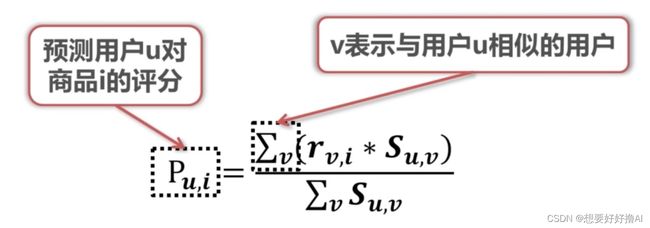
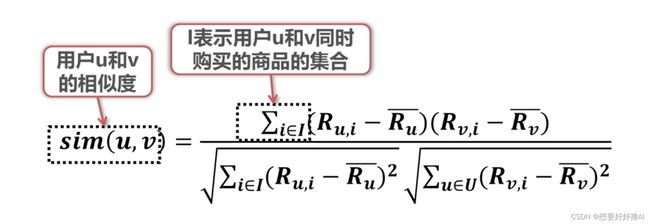
4. 基于用户的协同过滤
先找到与用户A相似的其他用户,看其他用户购买过什么商品:
再预测用户对商品的评分,将其进行排序,选择评分高的商品推荐给用户:
5. 冷启动问题 cold start
针对新用户:
- 对该用户进行随机推荐,但推荐的东西有可能是反感的
- 不推荐,用户有行为后再推荐
针对新商品:
- 在网页中增加一栏代表新电影,当新电影收看人数达到100人,并且被评分,就将该电影的评分信息加入评分表中,然后参与到推荐系统的计算中,最后就可推荐该电影
重要的是解决的问题的方案,然后去实践,测试,优化!
6. 混合算法
组合多种推荐算法:
- mixed:使用多个推荐系统同时推荐,将结果推荐给用户
- feature combination:将多个推荐系统使用的特征组合起来给另一个推荐系统
- cascade:一个推荐系统产生结果后用另一个系统进行筛选,将筛选结果推荐给用户
- switching:根据当前状态在不同的推荐系统之间进行切换
7. 推荐系统性能评估
线下评估
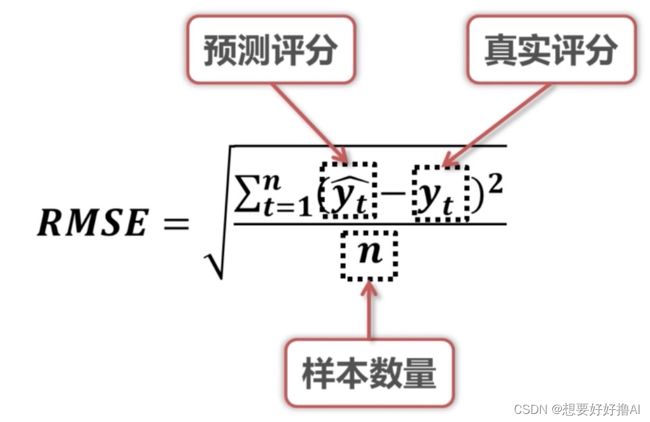
RMSE 均方根误差:
MAE 绝对值误差:

Recall 召回率:
- 针对评分不多的商品
- recall = 6/10 = 0.6
- recall值越大,推荐系统包含越多用户所需,目标是推荐的商品尽可能是用户所需
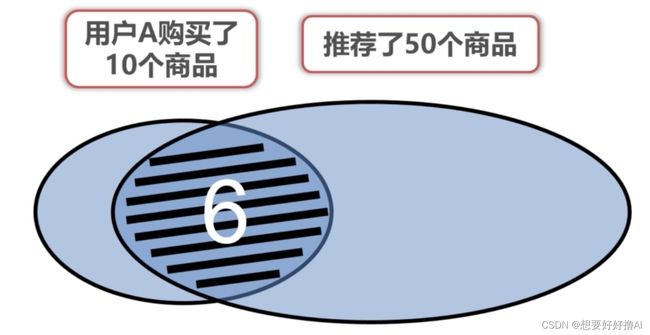
Precision:
- 6/50 = 0.12
- 与recall结合,当两者分值都很大,系统好
F1 score:

- F分值越大越好
- 如果推荐系统预测用户A会买商品i,实际也如此,是tp,如果实际没有,是fp
- 如果推荐系统预测用户A不会买商品i,实际也如此,是tn,如果实际买了,是fn


线上评估
- 并不是线下评估越好,线上也好
- 而是利润越高越好
CTR:click through rate 用户点击率
- 推荐系统重复推荐类似商品10次,用户点击3次,CTR = 0.3,越高代表用户感兴趣
CR:conversion rate 转化率
- 用户点击后,是否看完这部电影或听完这首歌或购买了商品,就是CR,越高代表用户体验好
ROI:不同的投资带来的回报
- 越大,代表推荐系统性能越好
- 将回报定义为:利润量增加,阅读量增加
- 将代价定义为:计算资源成本
QA:成立QA小组,根据个人经验评判推荐系统

二、使用TF构建电影推荐系统
1. 数据收集
https://grouplens.org/datasets.movielens/
2. 数据准备
import pandas as pd
import numpy as np
import tensorflow as tf
# 加载文件和查看文件
ratings_df = pd.read_csv('ml-latest-small/ratings.csv')
ratings_df.tail()
movies_df = pd.read_csv('ml-latest-small/movies.csv')
movies_df.tail()
# 添加行号信息:因为movies表中的movieID远大于行号,如果使用movieID的最大值来构建评分表,那么评分表是一个非常大的稀疏矩阵,浪费内存,所以使用行号标志电影
movies_df['movieRow'] = movies_df.index
movies_df.tail()
'''
创建两个矩阵
1. 创建电影评分矩阵rating:用于记录每个用户对每个电影的评分
2. 创建用户是否评分矩阵record:如果评分是1,否则为0
'''
# 首先筛选movies_df中的特征
movies_df = movies_df[['movieRow', 'movieId', 'title']]
# 保存该处理后的数据
movies_df.to_csv('moviesProcessed.csv', index=False, header=True, encoding='utf-8')
movies_df.tail()
# 将ratings_df中的movieId替换为行号
ratings_df = pd.merge(ratings_df, movies_df, on='movieId')
ratings_df.head()
# 筛选需要用到的特征
ratings_df = movies_df[['movieRow', 'userId', 'rating']]
ratings_df.to_csv('ratingsProcessed.csv', index=False, header=True, encoding='utf-8')
ratings_df.head()
# 1. 创建电影评分矩阵rating:用于记录每个用户对每个电影的评分
# 获取用户最大编号:作为rating矩阵中的列
userNo = ratings_df['userId'].max()+1
# 获取电影最大编号:作为rating矩阵中的行
movieNo = ratings_df['movieRow'].max()+1
# 创建rating矩阵
# 全部初始化为0
rating = np.zeros((movieNo, userNo))
# 创建电影评分表:添入rating矩阵
flag = 0 # 记录处理进度
ratings_df_length = np.shape(ratings_df)[0] # ratings_df的样本个数
# 将ratings_df中的数据填写到rating中
for index, row in ratings_df.iterrows():
rating[int(row['movieRow']), int(row['userId'])] = row['rating'] # 将row中的评分rating,填入rating中的电影编号和用户编号
flag += 1 # 处理完一行
print('processed %d, %d left' % (flag, ratings_df_length-flag)) #
# 2. 创建用户是否评分矩阵record:如果已经评分是1,否则为0
# 在电影评分表中,为0代表未评分
record = rating > 0
# 因为record中是布尔值组成的矩阵,将其转化为0和1
record = np.array(record, dtype=int)
3. 构建模型
# 对评分取值范围进行缩放
# 定义函数:接受两个参数:电影评分表,评分记录表
def normalizeRating (rating, record):
m, n = rating.shape # m电影数,n用户数
# 每个电影每个用户的评分平均值
rating_mean = np.zeros((m, 1)) # 所有电影平均评分初始化为0
rating_norm = np.zeros((m, n)) # 保存处理之后的数据
for i in range(m): # 将原始评分减去平均评分,将结果和平均评分返回
idx = record[i, :] != 0 # 已评分的电影对应的用户下标
rating_mean[i] = np.mean(rating[i, idx]) # 记录这些评分的平均值,第i部电影
rating_norm[i, idx] -= rating_mean[i] # 原始评分减去评分的平均值
return rating_norm, rating_mean
rating_norm, rating_mean = normalizeRatings(rating, record) # 结果提示有全0数据,需处理
rating_norm = np.nan_to_num(rating_norm) # 将nan数据转换为0
rating_mean = np.nan_to_num(rating_mean) # 将nan数据转换为0
num_features = 10 # 假设有10种类型的电影
# 初始化电影内容矩阵X,产生的每个参数都是随机数且正态分布
X_parameters = tf.Variable(tf.random_normal([movieNo, num_features], stddev=0.35))
# 初始化用户喜好矩阵theta,产生的每个参数都是随机数且正态分布
Theta_parameters = tf.Variable(tf.random_normal([userNo, num_features], stddev=0.35))
# 定义代价函数loss:tf.reduce_sum求和,tf.matmul相乘,transpose_b=True转置b项,
loss = 1/2 * tf.reduce_sum(((tf.matmul(X_parameters, Theta_parameters, transpose_b=True) - rating_norm) * record) ** 2) + 1/2 * (tf.reduce_sum(X_parameters ** 2) + tf.reduce_sum(Theta_parameters ** 2)) # 后面部分是正则化项,lambda为1,可以调整lambda来观察模型性能变化
# 创建adam优化器和优化目标
optimizer = tf.train.AdamOptimizer(le-4) # 学习速率10^-4
train = optimizer.minimize(loss) # 目标:最小化代价函数4. 模型训练
# 查看代价值随着迭代次数增加的变化情况
# 使用tensorboard将整个训练可视化
# tensorboard中tf.summary模块用于将tensorflow的数据导出,从而可视化
# 由于需要可视化的loss值是标量,所以要用summary中的scalar
tf.summary.scalar('loss', loss)
# 将所有summary信息汇总
summaryMerged = tf.summary.merge_all()
# 保存信息的路径
filename = './movie_tensorboard'
# FileWriter用于把信息保存到文件中
writer = tf.summary.FileWriter(filename)
# 创建tensorflow会话
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
# 训练模型,训练次数5000
for i in range(5000):
_, movie_summary = sess.run([train, summaryMerged]) # 记录每次迭代的loss的变化,每次train训练的结果保存到_中
writer.add_summary(movie_summary, i) # 训练后保存数据,代价值随着迭代次数i的变化情况
'''
查看代价值随着迭代次数的变化情况:
1. 打开cmd操作界面
2. 切换cd到保存数据的路径中
3. 运行:tensorboard --logdir=./
4. 浏览器中输入:127.0.0.1:6006
5. 可以看到代价值随着迭代次数的增加而减小
'''5. 模型评估
# 测试不同的num_features的值,通过比较误差,判断哪个num_features的值最合适
# 使用前面得到的参数,填满电影评分表
# 获取当前X和theta
Current_X_parameters, Current_Theta_parameters = sess.run([X_parameters, Theta_parameters])
# 将电影内容矩阵和用户喜好矩阵相乘,再加上每一行的均值,得到一个完整的电影评分表
# dot用于矩阵之间的乘法操作
predicts = np.dot(Current_X_parameters, Current_Theta_parameters.T) + rating_mean
# 计算预测值与真实值之间的算数平方根作为预测误差
errors = np.sqrt(np.sum((predicts - rating)**2))
errors6. 构建完整的电影推荐系统
# 获取用户ID,并保存
user_id = input('您要向哪位用户进行推荐?请输入用户编号:')
# 获取对该用户电影评分的列表
# 预测出的用户对电影的评分,并从大到小排序
sortedResult = predicts[:, int(user_id)].argsort()[::-1]
# 向该用户推荐评分最高的20部电影
idx = 0 # 保存已经推荐了多少部电影
print('为该用户推荐的评分最高的20部电影是'.center(80, '='))
# 开始推荐
for i in sortedResult:
print('评分:%.2f, 电影名:%s' % (predicts[i, int(user_id)], movies_df.iloc[i]['title']))
idx += 1 # 已经推荐的电影
if idx == 20: break