【深度干货】强化学习应用简述

来源:海豚数据科学实验室
强化学习 (reinforcement learning) 经过了几十年的研发,在一直稳定发展,最近取得了很多傲人的成果,后面会有越来越好的进展。强化学习广泛应用于科学、工程、艺术等领域。
下面简单列举一些强化学习的成功案例,然后对强化学习做简介,介绍两个例子:最短路径和围棋,讨论如何应用强化学习,讨论一些仍然存在的问题和建议,介绍《机器学习》强化学习应用专刊和强化学习应用研讨会,介绍强化学习资料,回顾强化学习简史,最后,简单讨论强化学习的前景。
01
成功案例
我们已经见证了强化学习的一些突破,比如深度Q网络 (Deep Q-Network, DQN)应用于雅达利(Atari)游戏、AlphaGo (也包括AlphaGo Zero和AlphaZero)、以及DeepStack/Libratus等。它们每一个都代表了一大类问题,也都会有大量的应用。DQN应用于雅达利游戏代表着单玩家游戏,或更一般性的单智能体 (agent) 控制问题。DQN点燃了这一波研发人员对深度强化学习的热情。AlphaGo代表着双人完美信息零和游戏。AlphaGo在围棋这样超级难的问题上取得了举世瞩目的成绩,是人工智能的一个里程碑。AlphaGo让普罗大众认识到人工智能,尤其是强化学习的实力和魅力。DeepStack/Libratus代表着双人不完美信息零和游戏,是一类很难的问题,也取得了人工智能里程碑级别的成绩。
谷歌Deepmind AlphaStar打败了星际争霸人类高手。Deepmind在一款多人抢旗游戏(Catch the Flag)中达到了人类玩家水平。OpenAI Five打败了人类刀塔(Dota)高手。OpenAI训练了类人机器人手Dactyl, 用于灵活地操纵实物。谷歌人工智能把强化学习用到数据中心制冷这样一个实用系统。DeepMimic模拟人形机器人,掌握高难度的运动技能。强化学习也应用于化学分子逆合成和新药设计。等等。
强化学习也已经被用到产品和服务中。谷歌云的自动机器学习 (AutoML) 提供了自动优化神经元网络结构设计这样的服务。脸书开源了Horizon产品和服务,实现通知传达、视频流比特率优化等功能。谷歌研发了基于强化学习的YouTube视频推荐算法。亚马逊与英特尔合作,发布了一款强化学习实体测试平台AWS DeepRacer. 滴滴出行则把强化学习应用于派单等业务。阿里、京东、快手等把强化学习应用于推荐系统。
02
强化学习简介
1. 强化学习与相关学科的关系
强化学习一般看成是机器学习的一种。机器学习从数据中学习做预测或决策。一般把机器学习分为监督学习、无监督学习、和强化学习。监督学习中的数据有标注;无监督学习的数据没有标注。分类和回归是两类监督学习问题,其输出分别是类别和数字。强化学习中有评估反馈,却没有标注数据。评估反馈不能像监督学习中的标注那样指明一个决策正确与否。与监督学习相比,强化学习还有成绩分配、稳定性、探索与利用等方面的挑战。深度学习,也就是通过深度神经元网络进行学习,可以作为或用于上面几种机器学习方法。深度学习是机器学习的一部分,而机器学习又是人工智能的一部分。深度强化学习则是深度学习与强化学习的结合。下图左侧框图为机器学习的分类,引自维基百科;右侧框图是人工智能的分类,引自流行的Russell & Norvig 人工智能教材。
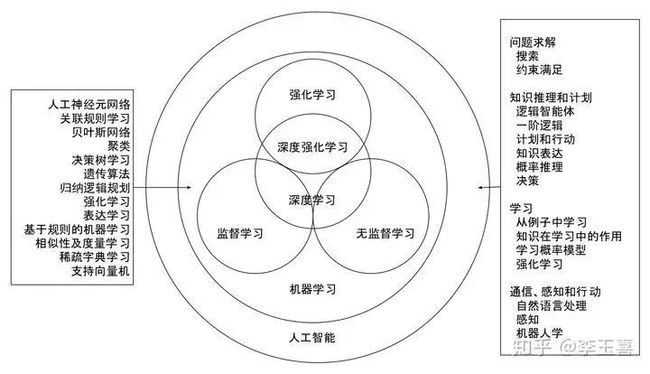 事实上这些领域都在不断发展。深度学习可以与其它机器学习、人工智能算法一道完成某项任务。深度学习和强化学习正在努力解决一些传统的人工智能问题,比如逻辑、推理、知识表达等。就像流行的Russell & Norvig 人工智能教材所述,可以认为强化学习包括所有的人工智能:在环境中的智能体必须学习如何在里边成功的表现;以及,强化学习可以看成整个人工智能问题的微生物。另外,应该说明,监督学习、无监督学习、强化学习两两之间有一定交叉。
事实上这些领域都在不断发展。深度学习可以与其它机器学习、人工智能算法一道完成某项任务。深度学习和强化学习正在努力解决一些传统的人工智能问题,比如逻辑、推理、知识表达等。就像流行的Russell & Norvig 人工智能教材所述,可以认为强化学习包括所有的人工智能:在环境中的智能体必须学习如何在里边成功的表现;以及,强化学习可以看成整个人工智能问题的微生物。另外,应该说明,监督学习、无监督学习、强化学习两两之间有一定交叉。
如下图所示,强化学习与计算机科学、工程、数学、经济学、心理学、神经科学、机器学习、最优控制、运筹学、博弈论、条件反射、奖赏系统等都有内在的联系。此图为David Silver强化学习英文版课件的中文翻译。
强化学习/人工智能、运筹学、最优控制这些学科都以应用数学、优化、统计为基础,同时为科学工程各方面的应用提供工具。运筹学、最优控制一般需要模型;比如混合整数规划、随机规划等数学表达式就是模型的体现。模型一般不准确、测不准;参数估计一般有误差。强化学习可以不用模型,直接通过数据进行训练,从而做出接近最优或最优的决策。数据可以来自完美模型、精准仿真器、或大数据。强化学习可以处理很复杂的问题。AlphaGo给了一个有力证明。策略迭代提供了一条不断提升性能的途径。强化学习/人工智能、运筹学、最优控制相互促进,各取所长。强化学习得益于动物学习、神经科学、心理学的奖赏系统、条件反射等。同时,强化学习可以解释多巴胺等神经科学中的机制。图中没有展示,但心理学、神经科学为强化学习/人工智能与社会科学、艺术等架设了联系的桥梁。

2. 强化学习简介
如下图所示,强化学习智能体 (agent) 与环境 (environment) 交互,针对序列决策问题,通过试错 (trial-and-error) 的方式学习最优策略。强化学习一般定义为马尔科夫决策过程(Markov Decision Process, MDP). 在每一个时间步骤,智能体接受到一个状态 (state),根据策略 (policy) 选择一个动作 (action),获得奖赏 (reward),然后根据环境的动态模型转移到下一个状态。这里面,策略表达智能体的行为,就是状态到动作的映射。强化学习中,经验 (experience) 是指 (状态,动作,奖赏,下一个状态) 这样一系列的数据。在片段式 (episodic) 的环境中,上述过程一直持续直到遇到终止状态,然后重新开始。在连续性 (continuing) 的环境中,则没有终止状态。用一个折扣因子(discount factor)来表达将来的奖赏对现在的影响。模型 (model) 指状态转移模型和奖赏函数。强化学习的适用范围非常广泛:状态和动作空间可以是离散的或连续的,强化学习问题可以是确定性的、随机性的、动态的、或者像一些游戏那样对抗性的。

状态值函数或动作值函数分别用来度量每个状态或每对状态-动作的价值。是对回报的预测,而回报是长期折扣累积奖赏的期望。动作值函数一般也称为Q函数。最优值函数是所有策略所能得到的最好的值函数;而相应的策略则为最优策略。最优值函数包含了全局优化信息;一般可以比较容易地从最优状态值函数或最优动作值函数得到最优策略。强化学习的目标是得到最优的长期回报或找到最优策略。
3. 例子:最短路径
下面举一个强化学习应用于最短路径问题的例子。最短路径问题就是要找起始节点到终止节点之间的最短路径,也就是要最小化它们之间的距离,或者最小化它们之间路径上所有的边的距离的和。最短路径问题如下定义成强化学习问题。当前节点为状态。在每个节点,动作是指顺着相连的边到达邻居节点。转移模型指从某个节点选择通过一条边后到达相应的邻居节点,当前状态或节点也随之改变。奖赏则是刚通过的边的距离的负数。到达终止节点则该片段结束。折扣因子可以设为1,这样就不用区分眼前的边的距离和将来的边的距离。我们可以把折扣因子设成1,因为问题是片段式的。目标是找到一条从起始节点到终止节点的最短路径,最大化整条路径上距离的负数的和,也就最小化了整条路径的距离。在某个节点,最优策略选择最好的邻居节点,转移过去,最后完成最短路径;而对于每个状态或节点,最优值函数则是从那个节点到终止节点的最短路径的距离的负数。
下图是一个具体的例子。图中有节点、(有向)边、边的距离这些图的信息。我们要找从节点S到节点T的最短路径。强化学习算法并不了解图的全局信息。在节点S,如果我们选择了最近的邻居节点A,那么就没办法找到最短路径S → C → F → T 了。这个例子说明,如果一个算法只关注眼前利益,比如在节点S选择最近的邻居节点A,可能会导致无法找到最优结果。像TD学习和Q学习这样的强化学习方法,考虑了长期回报,都可以找到最优解。

有的读者可能会问:为什么不用Dijkstra算法?如果我们有节点、边、边的距离这样的图的全局信息,那么Dijkstra算法可以高效地找到最短路径。强化学习算法可以不用这些全局信息,而是用免模型的方式,根据TD学习和Q学习这样的算法在图中不断采集本地信息,更新值函数,最终找到最短路径。Dijkstra算法在知道图的全局信息时,是最短路径的高效算法;而强化学习可以不依托于这些全局信息,比Dijkstra算法的适用面更广,是一般性的优化方法框架。
另外,强化学习可以处理有随机元素的最短路径问题。而且,目前的一个研究热点是,用机器学习/强化学习去学习一类问题的求解方法;遇到新问题,直接用推断的方式得出答案。
4. 例子:围棋
在围棋中,状态指当前棋盘的状态,包括黑白棋子的位置,空的位置等。围棋的状态空间特别大,有250的150次方个不同的状态。而国际象棋的状态空间为35的80次方。为了处理一些复杂的情况,比如“大龙”,状态也应该包括历史信息。这样会明显增大状态空间。动作指目前可以放棋子的位置。每一步,每位玩家最多有19x19=361个可能的动作。转移模型表达了在当前玩家落子后棋盘状态的变化。围棋中转移模型是确定性的;或者说没有随机性。奖赏函数指在当前玩家落子后获得的奖赏。只有在确定胜负时,胜了得1分,输了-1分,其它情况都是0分。围棋AI的目标是设计最优对弈策略,或者说赢棋。围棋中有明确的游戏规则,这样,就有完美的转移模型和奖赏函数。因为状态空间特别大,而且状态的值函数非常难估计,围棋是AI领域一个长期的难题。所以,2016年谷歌Deepmind的AlphaGo打败国际顶级棋手李世乭成为世界头条新闻,展现了深度强化学习的强大威力。
5. 更多强化学习简介
如果有系统模型,我们可能可以使用动态规划(dynamic programming) 方法:用策略评估 (policy evaluation) 去计算一个策略的状态或动作值函数,用值迭代 (value iteration) 或策略迭代 (policy iteration) 来找到最优策略;而策略迭代通常使用策略评估和策略改进 (policy improvement)迭代计算。我们要解决的很多问题没有现成的系统模型;这样,强化学习就有其用武之地。强化学习可以不需要模型,即免模型 (model-free) 的方式,得到最优值函数和最优策略。免模型强化学习可以通过与环境交互的在线(online)方式学习,也可以通过离线(offline)方式从历史数据中学习。蒙特卡罗 (Monte Carlo) 方法用样本的均值做估计;每一个样本是完整的一条经验轨迹;它不需要系统的模型,但是它只适用于片段式的任务。
时序差分 (temporal difference, TD) 学习是强化学习中的一个核心概念。TD学习一般指阿尔伯塔大学(University of Alberta) Richard Sutton教授于1988年发现的用于值函数评估的学习方法。TD学习直接从经验中,通过自助法 (bootstrapping) 、以免模型、在线、完全增量(incremental)方式学习状态值函数。这里边,自助法是一种基于自身的估计去做估计的方法。TD学习是一种同策略 (on-policy) 方法,通过行为策略产生的样本来评估同样的策略。Q学习是一种时序差分控制方法,通过学习最优动作值函数来找到最优策略。Q学习是一种异策略 (off-policy) 方法,通过从某个行为策略产生的数据来学习,而这些数据一般不是通过目标策略产生。
TD学习和Q学习评估状态值函数或动作值函数,是基于值的 (value-based) 方法。而基于策略的 (policy-based) 方法则直接优化策略,比如策略梯度 (policy gradient) 方法。行动者-评价者 (actor-critic) 算法同时更新值函数和策略。
在表格式的情况,值函数和策略以表格的形式存储。如果状态空间与动作空间很大或者是连续的,那么就需要函数近似 (function approximation) 来实现泛化 (generalization) 能力。函数近似是机器学习中的一个概念;其目标是从部分样本泛化函数从而近似整个函数。线性函数近似是一种常用方法;一个原因是它有比较好的理论性质。在线性函数近似中,一个函数由一些基函数(basis function)的线性组合近似。线性组合的系数则需要由学习算法确定。
我们也可以用非线性函数近似,尤其是使用深度神经元网络,也就是最近流行的深度学习所用的网络结构。如果把深度学习和强化学习结合起来,用深度神经元网络来表达状态、值函数、策略、模型等,我们就得到了深度强化学习(deep reinforcement learning, deep RL)。这里深度神经元网络的参数需要由学习算法来确定。深度强化学习最近受到广泛关注,也取得了很多斐然的成绩。应该说,深度强化学习在很久以前就取得过好成绩;比如1992年应用于西洋双陆棋(Backgammon)的TD-Gammon工作。有一些比较有影响的深度强化学习算法,比如,上面提到的DQN算法,还有异步优势行动者-评价者算法(Asynchronous Advantage Actor-Critic, A3C), 深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG), 可信区域策略优化算法(Trust Region Policy Optimization, TRPO), 近端策略优化算法(Proximal Policy Optimization, PPO),和软行动者-评价者算法(soft actor-critic)等等。最后的注释参考文献部分简要介绍了这些算法。
强化学习的一个基本问题是探索-利用(exploration-exploitation)之间的矛盾。智能体一方面需要利用目前最好的策略,希望获得最好的回报;另一方面,目前最好的策略不一定是最优策略,需要探索其它可能性;智能体需要在探索-利用两者之间进行平衡折衷。一个简单的探索方案是 -贪婪方法:以1- 的概率选择最优的动作,否则随机选择。上置信界算法(Upper Confidence Bound , UCB)是另外一类探索方法,同时考虑动作值函数及其估计方差。UCB应用于搜索树中得到UCT算法,在AlphaGo中发挥了重要作用。
6. 强化学习词汇
在这里汇集了一些强化学习词汇,方便读者查询。
预测 (prediction),或策略评估 (policy evaluation),用来计算一个策略的状态或动作值函数。控制 (control) 用来找最优策略。规划 (planning) 则根据模型来找值函数或策略。
用行为策略 (behaviour policy) 来产生样本数据;同时希望评估目标策略 (target policy)。同策略 (on-policy) 中,产生样本的行为策略与需要评估的目标策略相同。比如,TD学习就用来评估当前的策略,或者说用同样的策略产生的样本来做策略评估。异策略 (off-policy) 中,产生样本的行为策略与需要评估的目标策略一般不相同。比如,Q学习的目标是学习最优策略的动作值函数,而用来学习的样本数据一般都不是依据最优策略产生的。
探索-利用 (exploration-exploitation) 之间的矛盾指,智能体需要利用目前最好的策略,希望达到最大化奖赏的目标;同时,也需要探索环境,去发现更好的策略,尤其是在目前的策略仍然不是最优策略或者环境并不稳定等情况下。
在免模型 (model-free) 强化学习方法中,智能体不知道状态转移和奖赏模型,从与环境的交互经验中通过试错的方式直接学习。而基于模型(model-based)强化学习方法则利用模型。模型可以是给定的,比如像计算机围棋中那样通过游戏规则得到的完美模型,或是通过数据学习来的。
在线模式 (online) 算法通过序列数据流来训练,不保存数据,不进一步使用数据。离线模式(offline) 或批量模式 (batch mode) 算法则通过一组数据来训练。
在自助法(bootstrapping)中,对一个状态或动作的值函数估计会通过其它状态或动作的值函数估计来获得。
03
如何应用强化学习
1. 如何应用强化学习
把强化学习应用于实际场景,首先要明确强化学习问题的定义,包括环境、智能体、状态、动作、奖赏这些核心元素。有时也可能知道状态转移模型。需要考察监督学习或情境老虎机(contextual bandits)是否更适合要解决的问题;如果是那样,强化学习则不是最好的解决方案。强化学习的应用场景一般需要一定的资源,包括人才、计算力、大数据等。
目前成功的强化学习应用一般需要有足够的训练数据;可能来自完美的模型、很接近真实系统的仿真程序、或通过与环境交互收集到的大量数据。收集到的数据根据问题做相应处理。
一个模型或好的仿真程序可以产生足够的数据进行训练。有些问题,比如健康医疗、教育、自动驾驶等方面的问题,可能很难、不可行、或不合乎道德规范对所有情况采集数据。这种情况,异策略技术可以用行为策略产生的数据来学习目标策略。把在仿真程序学到的策略迁移到真实场景方面最近有一些喜人的进展,尤其在机器人方面。有些问题可能需要大量的计算。比如,AlphaGo的成功有几个重要因素:通过游戏规则得到了完美模型,产生大量训练数据,谷歌级的海量计算能力进行大规模训练,以及研发人员非凡的科研和工程能力。
特征工程一般需要大量的手工处理并结合很多相关行业知识。随着深度学习兴起的端到端学习模式,手工的特征工程可能很少用,甚至不用。不过,在实际问题中,特征工程很可能无法避免,也可能是取得好性能至关重要的因素。
需要考虑强化学习的表征问题,比如,是否需要以及需要什么样的神经网络来表达值函数和策略;是否考虑线性模型;而对于规模并不大的问题,甚至可以考虑表格的方式。
有了数据、特征、和表征,需要考虑选取什么算法来计算最优值函数和最优策略。有许多强化学习算法可能选择,可能是在线的或离线的、同策略或异策略的、免模型或有模型的等。通常根据问题的具体情况,选择几种算法,然后挑性能最好的。
通过做实验,参数调优,比较算法性能。强化学习应该与目前最高水平的算法对比,可能是其它强化学习算法,也可能是监督学习、情境老虎机、或某种传统算法。为了调优算法,可能多次迭代前面几步。
当训练的强化学习算法性能足够好,就把它部署到实际系统中,监控性能,不断调优算法。可能需要多次迭代前面几步,调优系统性能。

上图描述了应用强化学习的流程,简单总结如下。
第一步:定义强化学习问题。定义环境、智能体、状态、动作、奖赏这些核心元素。
第二步:数据准备,收集数据,预处理。
第三步:特征工程,一般根据领域知识手动生成,也可能以端到端的方式自动产生。
第四步:选择表征方式,有深度神经元网络、其它非线性、线性、甚至表格等表征方式。
第五步:选择算法,根据问题选择几种算法。
第六步:实验、调优系统;可能要多次迭代前面几步。
第七步:部署、调优系统。可能要多次迭代前面几步。
2. 强化学习现存问题及建议
强化学习虽然取得了很多骄人的成绩,但是仍然存在不少问题。强化学习与函数近似结合,尤其与深度学习结合,存在“死亡三组合” (deadly triad) 问题。就是说,在异策略、函数近似、自助法同时结合时,训练可能会碰到不稳定或发散的问题。样本效率、稀疏奖赏、成绩分配、探索-利用、表征等是常见问题。深度强化学习还有可复制性的问题,实验结果可能会受到网络结构、奖赏比例、随机种子、随机实验、环境、程序实现等的影响。强化学习同机器学习一样面临一些问题,比如时间效率、空间效率、可解释性、安全性、可扩展性、鲁棒性、简单性等等。从积极的角度看待,研发人员一直在这些方面努力工作。后面章节会进一步讨论。
强化学习虽然有这么多问题,却可以给很多问题提供有效的解决方案。麻省理工学院(Massachusetts Institute of Technology, MIT) Dimitri Bertsekas教授是强化学习领域有影响的研究者。他对强化学习的应用持谨慎乐观的态度。他指出:一方面,还没有强化学习方法可以解决所有甚至大多数问题;另一方面,有足够多的方法去尝试,有比较好的可能性在大多数问题上取得成功,比如确定性问题、随机性问题、动态问题、离散或连续问题、各类游戏等等。他说:我们开始用强化学习解决难以想象的难题!他又说:我们前面的强化学习旅程令人激动!
下面讨论几个话题,关于现实世界中强化学习面临的挑战,机器人高效学习的基础、强化学习应用于健康的参考原则、把机器学习负责任地应用于健康医疗、以及人工智能创业。虽然有些话题关于人工智能或机器学习,但对强化学习及其应用也有参考意义。
3. 现实世界中强化学习面临的挑战
谷歌Deepmind和谷歌研究院合作发表论文,研究为什么强化学习虽然在游戏等问题获得了巨大成功,但在现实世界中仍然没有被大规模应用。他们讨论了下面九个制约因素:1)能够对现场系统从有限的采样中学习;2)处理系统执行器、传感器、或奖赏中存在的未知、可能很大的延迟;3)在高维状态空间和动作空间学习、行动;4)满足系统约束,永远或极少违反;5)与部分可观察的系统交互,这样的系统可以看成是不平稳的或随机的;6)从多目标或没有很好指明的奖赏函数学习;7)可以提供实时动作,尤其是高控制频率的系统;8)从外部行为策略的固定的日志数据离线学习;9)为系统操作员提供可解释的策略。他们辨识并定义了这些挑战因素,对每个挑战设计实验并做分析,设计实现基线任务包含这些挑战因素,并开源了软件包。
4. 机器人高效学习的基础
在目前的深度学习、强化学习、机器学习的基础上,机器人学习算法取得成功的一个关键因素是需要大量的实际数据。而一个通用机器人要面对各种各样的情况,则获取大量训练数据成本会很高。这样,下面几个方面会很关键:1)采样高效 (sample efficient),需要比较少的训练数据;2)可泛化性 (generalizable),训练的机器人不光能应用于训练的情况,还可以扩展到很多其它情况;3)组合方式 (compositional),可以通过以前的知识组合而成;4)增量方式 (incremental),可以逐渐增加新知识和新能力。目前的深度强化学习虽然可以学习很多新能力,不过,一般需要很多数据,泛化性不好,不是通过组合或增量的方式训练和执行。学习算法如果要获得泛化能力,需要具备固有的知识或结构等形式的归纳偏向(inductive bias),同时提高采样效率。组合性和增量性可以通过特定的结构化的归纳偏向获得,把学到的知识分解成语义相互独立的因子,就可以通过组合解决更多的问题。
在学习算法中加入先验知识或结构,有一定的争议。强化学习之父Richard Sutton认为不应该在学习系统中加入任何先验知识,因为人工智能的历史经验表明,每次我们想人为加些东西,结果都是错的。MIT教授Rodney Brooks写博客做了强烈回应。这样的学术争论很有益,可以让我们辩明设计学习系统时的问题:应该把什么样的归纳偏向包括到学习系统中,可以帮助从适量的数据中学到可以泛化的知识,同时又不会导致不准确或过度约束?
有两种方式可以找到合适的归纳偏向。一种是元学习(meta-learning)。在系统设计阶段,以离线方式学习结构、算法、先验知识;这样,到系统部署后,就可以在新环境高效地在线学习。在系统设计阶段,元学习通过可能在部署后碰到的任务的大量训练数据,学习一个学习算法,当遇到新的任务时,可以尽可能高效地学习;而不是学习对一个环境好的算法,或是试图学一个对所有环境都好的算法。元学习通过学习训练任务之间的共性,形成先验知识或归纳偏向,这样,遇到新任务就可以主要去学习差异性。
还有一些可能的方向,包括让人教机器人,与其它机器人合作学习,修改机器人软件的时候一道修改硬件。利用从计算机科学与工程和认知神经科学获得的灵感,帮助设计机器学习的算法和结构。卷积神经元网络(convolutional neural networks)是一个很好的例子。卷积利用了翻译不变性(translation invariance),就是说,物体不管在图像中的什么位置,其表现基本不变;还有空间局部性(spatial locality),就是说,一组临近的像素共同提供图片的信息。用了卷积这样的归纳偏向,神经元网络的参数就大幅减少了,也大幅减少了训练。哺乳动物的视觉中枢应该就有类似于卷积这样的计算过程。机器人和强化学习需要类似的灵感来设计更高效的算法。
5. 强化学习应用于健康的参考原则
最近《自然医学》一篇短评论文讨论强化学习应用于健康问题时,要考虑的几个参考原则。第一,强化学习算法最好可以使用影响决定的所有数据。强化学习算法需要获得医生可以获得的信息。第二,有效样本量与学到的策略和医生的策略之间的相似度相关;相似度越高则有效样本量越大。序列中决策越多,新的策略与产生数据的策略不同的可能性就越大。第三,需要审查学到的策略,使其有合理的表现。需要考察问题建模是否合适,比如奖赏函数的定义,数据记录及处理是否会引入误差,以及策略的适用范围,等等。
6. 把机器学习负责任地应用于健康医疗
最近《自然医学》发表一篇观点论文,讨论机器学习在医学中为什么没有广泛应用,提出成功、负责任的发展方案。
第一,选择合适的问题。确定所研发的问题在健康医疗中有意义,收集合适的数据,对项目成功做出明确定义。于项目早期,就在团队中包括利益相关人员:a) 业务专家,包括临床医生、机器学习研究人员、健康医疗信息技术专家、开发实现专家;b) 决策者,包括医院管理人员、研究机构管理人员、监管部门人员、政府人员;c) 用户,包括护士、医生、实验室人员、病人、家人朋友。
第二,开发有用的解决方案。在预测一个结果时,一定要了解数据是什么时候如何收集的,收集数据的目的是什么。在模型应用的环境中,数据要有代表性。在开发模型的过程中,要改正电子病历数据中存在的偏向,否则会降低模型的可靠性。
第三,考虑伦理道德方面的因素。加入相关专家,改正数据中的偏向。
第四,对模型进行严格的评估。在训练和测试模型过程中,保证没有数据泄露发生。评估模型在什么情况很可能成功或失败。统计分析应该考虑与临床相关的评价指标。另外,用定性的方式评估,可能可以发现定量的方法没有发现的偏向和干扰(confounding)因素。
第五,做深思熟虑的汇报。详细描述数据源、参与者、结果、预测变量、以及模型本身。报告模型在什么情境下验证、应用,需要满足什么假设或条件。分享生成结果的代码、软件包、输入数据,以及支持文档。对下面两种技术路线的权衡分析:简单、快速、可解释的模型与复杂、比较慢却更准确的模型,提供帮助信息。
第六,负责任地部署。对于学到的模型,应该先实时预测结果,让临床专家评估其有效性,再给病人用。了解如何把干预策略与医护团队的工作流整合到一起也很重要。病人群体、临床规范经常变化,应该经常监视并评估模型的可靠性和错误,并对模型做相应改进。
第七,推向市场。机器学习健康医疗工具必须要满足所在国家的监管要求。
在健康医疗、自动驾驶等系统中,开发部署高效的机器学习系统存在很多复杂的问题。上面的发展方案可以帮助解决健康医疗中的问题,对其它领域也会有参考意义。
虽然离机器学习大规模应用于医疗健康还有很长的路,但是,政策制定者、健康医疗管理人员、研发人员等正在通力合作。在大力发展智慧医疗时,我们有时可能需要暂时放缓脚步,重温希波格拉底誓言(Hippocratic oath),即医生誓约,其首要之务就是不可伤害(first, do no harm)。
人工智能创业:人工智能公司代表一种新的商业模式
这里介绍一篇Andreessen Horowitz投资公司网站上的一篇博客,讨论人工智能公司代表一种新的商业模式,与传统的软件业有所不同,更像是传统的软件服务公司。
软件的优势在于生产一次就可以卖很多次。这样,就带来重复的收益流、高利润、有的时候还有超线性规模化,而且知识产权,一般是程序,可以形成高护城河。在软件服务业中,每个项目需要专门的开发人员,然后只能卖一次。这样,收益不能重复,总利润低,最好的情况就是线性增长。同时,不容易建护城河。
人工智能公司,因为对云计算平台的依赖,加上需要不断的人工支持,总利润比较低;因为要处理麻烦的边缘情况,上规模充满挑战;因为人工智能模型的商品化,以为数据是竞争资源并具有野蛮生长的网络效应而事实并非如此,护城河比较弱。
大多数人工智能应用程序看起来像软件,与用户交互,管理数据,与其它系统融合等。但其核心是一组训练好的数据模型,维护起来更像是软件服务。人工智能公司看着像软件公司与软件服务公司的某种组合,从总利润、规模化、防御性等方面看,代表了一种新的商业模式。
总利润方面,对于人工智能公司,云计算平台带来相当大的花费,包括训练模型、模型推断、处理丰富的媒体类型、复杂的云操作等。人工智能应用程序依赖人工作为系统的一部分,帮助清洗、标注大量数据,或需要实时的帮助,比如在认知推理任务中,以获得高准确率。这些会让总利润降低。当人工智能的性能逐步提高,人工的参与会越来越少,但很可能不会一点没有。因为人工智能经常面对长尾效应,或者说要经常处理边缘情况,很难让人工智能系统规模化。而保护人工智能商业的方案还没有成型。人工智能产品与纯软件产品比起来,不一定更难防御。不过,人工智能公司的护城河看起来比预想的要浅。
下面给创业人员一些实用建议,创建、规模化、防御伟大的人工智能公司。1)尽可能消除模型的复杂性。2)仔细选择问题领域,一般选择窄领域,降低数据复杂性,最小化边缘情况的挑战。3)为高变动的费用做好打算。4)拥抱服务。人工智能公司长期成功的关键是把软件和服务的优点结合起来。5)为新技术的不断出现做好打算。6)用旧的方式构建防御能力,好商业总需要好产品和私有数据。
人工智能创业:弥补概念验证与产品的差距
下面讨论吴恩达(Andrew Ng)博士于2020年10月初在斯坦福大学以人为本人工智能(Human-Centered AI, HAI)研究院做的一个学术报告。讨论了如何弥补人工智能中概念验证与产品的差距,包括以下三个方面:1)小数据;2)泛化性和鲁棒性;3)变化管理。
小数据算法包括合成数据生成,比如生成对抗网络(Generative Adversarial Networks, GANs),单样本/少样本学习,自我监督学习,迁移学习,异常检测等。
在一个数据集上训练的模型是否能泛化到其它数据集上?是个问题。论文里工作的模型,在产品中经常不工作。人工智能产品项目除了机器学习程序,还包括标注定义、歧义消解、高效批量数据标注、为罕见标注生成数据、数据验证、数据分析、环境变化检测、数据及模型版本控制、过程管理工具、模型性能下降检测等等。
管理技术带来的变化,包括计划足够的时间、发现所有的利益相关者,提供再保证,解释在发生什么,做规模合适的第一个项目。这里关键的技术是可解释人工智能和审计。
机器学习项目的周期包括:确定范围,决定要解决的问题;为模型获取数据;构建、训练模型;部署,运行产品创造价值。下面从后往前讨论这几个阶段。
先说部署。在云平台或边缘设备上实现。最初的部署允许分析结果,调整参数和模型。可以采取影子部署的方式,并不真正决策,只是实时监视性能。也可以先小规模部署。然后逐渐加大部署力度。长期保持监视和维护状态。
人工智能模型的构建和训练,是高度迭代的过程,从人工智能体系结构,包括算法、数据等,到程序和训练,再到分析,几个阶段反复循环;是开发过程,更是发现并修改错误的过程。机器学习模型由训练数据、超参数、算法/程序构成。一般通过修改超参数、算法/程序试图改进性能,也应该使用不同的训练数据,提高模型的泛化性。
对于获取模型需要的数据,并不需要等到有足够完美的数据才开始项目,却需要明确数据的定义,比如,如何定义图像边界框,或如何处理专家不同的意见,等等。
对于范围和要解决的问题,可以头脑风暴商业问题、技术解决方案,对价值和可行性做尽职调查,配置资源,制定计划,确定里程碑。人工智能专家确定什么可以做,领域专家确定什么是有价值的,这两个的交集里就有要解决的问题。
机器学习项目的周期中:确定范围,决定要解决的问题,需要不同功能部门的头脑风暴;为模型获取数据,需要不同功能部门的执行;构建、训练模型,需要人工智能的研究;部署,运行产品创造价值,需要机器学习开发、软件开发。
人工智能在用户互联网领域已经创造了价值。在互联网之外,人工智能仍然存在大量没有开发的机会。预计零售、旅游、交通、物流、汽车、材料、电子/半导体、健康、高科技、通信、能源、农业等领域2030年将创造13万亿美元的价值。但在很多其它领域仍然需要弥补概念验证到产品的差距。学术界和工业界应该联合起来把机器学习变成一个系统工程学科。
04
强化学习应用专刊与应用研讨会
1.《机器学习》强化学习应用专刊
强化学习是一类通用的学习、预测、决策的方法框架,在科学、工程、艺术等领域有广泛应用。已经在雅达利游戏、AlphaGo、机器人、推荐系统、AutoML等领域取得了突出成绩。不过,把强化学习应用到实际场景中仍然有很多挑战。这样,我们很自然地会问:问题是什么,如何解决?
这个专刊的主要目标为:(1) 确定能使强化学习成功应用的关键研究问题;(2) 报告在这些关键问题上的进展;3)让领域专家分享把强化学习应用到实际场景的成功故事,以及在应用过程中获得的洞察领悟。
专刊邀请解决强化学习落地相关的问题,把强化学习算法成功地应用于实际问题的稿件。专刊感兴趣的话题比较广泛,包括但不限于以下的话题:
实用强化学习算法,包括所有强化学习算法的挑战,尤其是在实际应用中遇到的挑战;
实际问题:泛化性、采样/时间/空间的效率、探索与利用、奖赏函数的详述(specification)与修整(shaping)、可扩展性、基于模型的学习(模型的效验与模型误差估计)、先验知识、安全性、责任、可解释性、可复制性、调超参数等等;
应用方向:推荐系统、广告、聊天系统、商业、金融、健康医疗、教育、机器人、自动驾驶、交通、能源、化学合成、药物设计、工业控制、美术、音乐、以及其它科学、工程、艺术问题。
专刊内容会在2021年初完成编辑,敬请关注。
2. 强化学习应用研讨会
在2019年国际机器学习大会(International Conference on Machine Learning, ICML)上,Alborz Geramifard (脸书), Lihong Li (谷歌), Csaba Szepesvari (Deepmind & 阿尔伯塔大学), Tao Wang (苹果) 共同组织举办了强化学习应用研讨会(Reinforcement Learning for Real Life, RL4RealLife). 工业界和学术界对强化学习应用感兴趣的研发人员集聚一堂,探讨如何将强化学习应用于实际场景。
研讨会有三个一流的特邀报告:
AlphaStar:理解星际争霸。报告人:David Silver
如何开展强化学习应用的革命?报告人:John Langford
推荐系统中的强化学习。报告人:Craig Boutilier
顶级专家组成了专题讨论小组: Craig Boutilier (谷歌研究院), Emma Brunskill (斯坦福大学), Chelsea Finn (谷歌研究院, 斯坦福大学, 加州大学伯克利分校), Mohammad Ghavamzadeh (脸书人工智能研究院), John Langford (微软研究院), David Silver (Deepmind), 和Peter Stone (得克萨斯大学奥斯丁分校, Cogitai). 讨论了重要的问题,比如,强化学习哪些方向最有前景?把强化学习应用到实际场景的一般性原则是什么?等等。
有大约60篇海报/论文。选择了4篇最佳论文:
Chow et al. 讨论了连续动作问题里的安全性
Dulac-Arnold et al. 讨论了强化学习应用的9个挑战
Gauci et al. 讨论了脸书的开源应用强化学习平台Horizon
Mao et al. 讨论了增强计算机系统开放平台Park
欢迎访问研讨会网站;有特邀报告的视频链接、大部分论文和一部分海报;网址为:sites.google.com/view/R.
2020年6月,Gabriel Dulac-Arnold (谷歌), Alborz Geramifard (脸书), Omer Gottesman (哈佛大学),Lihong Li (谷歌), Anusha Nagabandi (加州大学伯克利分校), Zhiwei (Tony) Qin (滴滴), Csaba Szepesvari (Deepmind & 阿尔伯塔大学) 在网上共同组织举办了强化学习应用研讨会。会议邀请了顶级专家组成了两个专题讨论小组,分别讨论“强化学习+健康医疗”和“一般性强化学习”两个专题;会议有30多篇海报/论文。
强化学习+健康医疗专题讨论由Finale Doshi-Velez (哈佛大学), Niranjani Prasad (普林斯顿大学), Suchi Saria (约翰霍普金斯大学)组成, 由Susan Murphy (哈佛大学)主持,由Omer Gottesman (哈佛大学)做开场及总结主持。
一般性强化学习专题讨论由Ed Chi (谷歌), Chelsea Finn (斯坦福大学), Jason Gauci (脸书)组成, 由Peter Stone (得克萨斯大学&索尼)主持, 由Lihong Li (谷歌)做开场及总结主持。
更多信息参见会议网址:sites.google.com/view/R.
05
强化学习资料与简史
1. 强化学习资料
强化学习的学习资料中,Sutton & Barto 的强化学习教科书是必读的,David Silver的UCL课程是经典,阿尔伯塔大学最近在Coursera上线了强化学习课程。强化学习里概念比较多,仔细学一些基础,会很有帮助。如果有一定深度学习背景,可能可以考虑直接学深度强化学习。OpenAI Spinning Up比较简洁,Deepmind与UCL合出了深度学习与强化学习课程,UC Berkeley的深度强化学习课程是高级进阶。下面列了这几个资料。
Sutton & Barto RL强化学习教科书,incompleteideas.net/boo
David Silver强化学习课程,www0.cs.ucl.ac.uk/staff
阿尔伯塔大学在Coursera上的强化学习课,coursera.org/specializa
OpenAI Spinning Up, blog.openai.com/spinnin
DeepMind & UCL 的深度学习与强化学习课程,youtube.com/playlist?
UC Berkeley深度强化学习课程,rail.eecs.berkeley.edu/
学习强化学习,有必要对深度学习和机器学习有一定的了解。下面推荐几篇综述论文。
LeCun, Bengio and Hinton, Deep Learning, Nature, May 2015
Jordan and Mitchell, Machine learning: Trends, perspectives, and prospects, Science, July 2015
Littman, Reinforcement learning improves behaviour from evaluative feedback, Nature, May 2015
希望深入了解深度学习、机器学习,Goodfellow et al. (2016)、Zhang et al. (2019) 介绍了深度学习;周志华(2016)、李航(2019)介绍了机器学习。
学习基本概念的同时应该通过编程加深理解。OpenAI Gym很常用,gym.openai.com.
下面的Github开源把Sutton & Barto强化学习书里面的例子都实现了,也有很多深度强化学习算法的实现:github.com/ShangtongZha.
2. 强化学习简史
早期的强化学习有两个主要的丰富绵长的发展线索。一个是源于动物学习的试错法;在早期的人工智能中发展,与二十世纪八十年代促进了强化学习的复兴。另一个是最优控制及其解决方案:值函数和动态规划。最优控制大部分没有包括学习。这两个线索先是分头进展,到二十世纪八十年代,时序差分(temporal-difference)方法出现,形成第三条线索。然后几种线索交织融合到一起,发展成现代强化学习。
最优控制始于二十世纪五十年代,设计控制器来优化动态系统一段时间内行为的性能指标。动态规划是最优控制的一个解决方法,由Richard Bellman等人提出,基于以前Hamilton和Jacobi的理论。动态规划使用动态系统的状态和值函数,或最优回报函数,来定义一个等式,现在被称为Bellman等式。通过解这个等式的一组方法则被称为动态规划方法。Bellman也提出离散随机版的最优控制问题,既马尔科夫决策过程(Markov decision processes, MDP). Ronald Howard在1960年给MDP问题设计了策略迭代方法。这些都是现代强化学习理论和算法的基本元素。
一般认为,动态规划是解决一般性的随机优化控制的唯一方法。动态规划会遇到“维度灾难”问题,就是说,它的计算复杂性随着状态变量的个数而指数增长。不过,动态规划仍然是最高效、应用最广的方法。动态规划已经被扩展到部分可见马尔科夫决策过程(Partially Observable MDP, POMDP),异步方法,以及各种应用。
最优控制、动态规划与学习的联系,确认得却比较慢。可能的原因是这些领域由不同的学科在发展,而目标也不尽相同。一个流行的观点是动态规划是离线计算的,需要准确的系统模型,并给出Bellman等式的解析解。还有,最简单的动态规划是按时间从后向前运算的,而学习则是从前往后的,这样,则很难把两者联系起来。事实上,早期的一些研究工作,已经把动态规划与学习结合起来了。而在1989年,Chris Watkins用MDP的形式定义强化学习问题,把动态规划和线上学习完全结合起来,也得到广泛接受。之后,这样的联系获得进一步的发展。麻省理工学院的Dimitri Bertsekas和John Tsitsiklis提出了神经元动态规划(neurodynamic programming)这一术语,用来指代动态规划与神经元网络的结合。现在还在用的另一个术语是近似动态规划(approximate dynamic programming). 这些方法与强化学习都是在解决动态规划的经典问题。
在某种意义上,最优控制就是强化学习。强化学习问题与最优控制问题紧密相关,尤其是描述成MDP的随机优化控制问题。这样,最优控制的解决方法,比如动态规划,也是强化学习方法。大部分传统的最优控制方法需要完全的系统模型知识,这样把它们看成强化学习有些不够自然。不过,许多动态规划算法是增量的、迭代的。像学习方法一样,它们通过连续的近似逐渐达到正确解。这些相似性有着深刻的意义,而对于完全信息和不完全信息的理论和方法也紧密相关。
下面讨论强化学习早期发展的另外一条线索:试错学习法。试错学习法最早可以追溯到十九世纪五十年代。1911年,Edward Thorndike简明地把试错学习法当成学习的原则:对于同一情况下的几个反应,在其它因素一样时,只有伴随着或紧随动物的喜悦之后的那些反应,才会被更深刻地与当下的情况联系起来,这样,当这些反应再次发生,再次发生的可能性也更大;而只有伴随着或紧随动物的不适之后的那些反应,与当下的情况联系会被削弱,这样,当这些反应再次发生,再次发生的可能性会更小。喜悦或不适的程度越大,联系的加强或减弱的程度也越大。Thorndike称其为“效果定律”(Law of Effect), 因为它描述了强化事件对选择动作的倾向性的效果,也成为许多行为的基本原则。
“强化”这一术语出现于1927年巴浦洛夫(Pavlov)条件反射论文的英译本,晚于Thorndike的效果定律。巴浦洛夫把强化描述成,当动物接收到刺激,也就是强化物,对一种行为模式的加强,而这个刺激与另一个刺激或反应的发生有合适的时间关系。
在计算机里实现试错法学习是人工智能早期的想法之一。在1948年,阿兰·图灵(Alan Turing)描述了一个“快乐-痛苦系统”,根据效果定律设计:达到一个系统状态时,如果选哪个动作还没有确定,就暂时随机选一个,作为临时记录。当出现一个痛苦刺激,取消所有的临时记录;当出现一个快乐刺激,所有的临时记录变成永久记录。
1954年,图灵奖获得者马文·明斯基(Marvin Minsky)在他的博士论文里讨论了强化学习的计算模型,描述了他搭建的模拟电路机器,用来模仿大脑中可以修改的突触连接。他于1961年发表《通向人工智能的几个步骤》(Steps Toward Artificial Intelligence), 讨论了与试错学习法相关的几个问题,包括预测、期望、还有被他称为复杂强化学习系统中基本的奖赏分配问题:如何把成功获得的奖赏分配给可能导致成功相关的那些决定?这个问题仍然是现代强化学习的一个关键问题。
二十世纪六十年代、七十年代试错学习法有一些发展。Harry Klopf在人工智能领域对试错法在强化学习中的复兴做了重要贡献。Klopf发现,当研究人员专门关注监督学习时,则会错过自适应行为的一些方面。按照Klopf所说,行为的快乐方面被错过了,而这驱动了从环境成功获得结果,控制环境向希望的结果发展,而远离不希望的结果。这是试错法学习的基本思想。Klopf的思想对强化学习之父Richard Sutton和Andrew Barto有深远影响,使得他们深入评估监督学习与强化学习的区别,并最终专注强化学习,包括如何为多层神经元网络设计学习算法。
现在讨论强化学习发展的第三个线索,时序差分学习。时序差分学习基于对同一个量在时间上相连的估计,比如,围棋例子中赢棋的概率。时序差分学习是强化学习中一个新的独特的方法。
时序差分学习部分上起源于动物学习心理学,尤其是次要强化物的概念。次要强化物与像食物和痛苦这样的主要强化物相伴而来,所以也就有相应的强化特点。明斯基于1954年意识到这样的心理学原则可能对人工学习系统的重要意义;他可能是第一位。1959年,Arthur Samuel在其著名的国际跳棋程序中,第一次提出并实现了包括时序差分学习的学习方法。Samuel受克劳德·香农(Claude Shannon)1950年工作的启发,发现计算机程序可以用评估函数玩国际象棋,棋艺也可以通过在线修改这个评估函数来提高。明斯基于1961年深入讨论Samuel的方法与次要强化物的联系。Klopf在1972年把试错学习法与时序差分学习联系起来。
Sutton在1978年进一步研究Klopf的想法,尤其是与动物学习的联系,通过连续时间预测的变化来定义学习规则。Sutton和Barto继续改进这些想法,提出了基于时序差分学习的经典条件反射心理学模型。同时期有不少相关工作;一些神经科学模型也可以用时序差分学习来解释。
Sutton和Barto于1981年提出了行动者-评价者体系结构,把时序差分学习与试错学习结合起来。Sutton1984年的博士论文深入讨论了这个方法。Sutton于1988年把时序差分学习与控制分开,把它当做一种通用的预测方法。那篇论文也提出了多步时序差分学习算法。
在1989年,Chris Watkins提出Q学习,把时序差分学习、最优控制、试错学习法三个线索完全融合到一起。这时,开始在机器学习和人工智能领域出现大量的强化学习方面的研究。1992年,
Gerry Tesauro成功地使用强化学习和神经元网络设计西洋双陆棋(Backgammon)的TD-Gammon算法,进一步增加了强化学习的热度。
Sutton和Barto于1998年发表《强化学习介绍》之后,神经科学的一个子领域专注于研究强化学习算法与神经系统中的强化学习,而这归功于时序差分学习算法的行为与大脑中生成多巴胺的神经元的活动之间神秘的相似性。强化学习还有数不胜数的进展。
最近,随着DQN算法的出现以及AlphaGo的巨大成功,强化学习进一步发展,也出现了深度强化学习这一子领域。这样,强化学习简史就与前面的介绍衔接起来了。
06
强化学习的前景
强化学习时代正在到来
强化学习是一类一般性的学习、预测、决策方法框架。如果一个问题可以描述成或转化成序列决策问题,可以对状态、动作、奖赏进行定义,那么强化学习很可能可以帮助解决这个问题。强化学习有可能帮助自动化、最优化手动设计的策略。
强化学习考虑序列问题,具有长远眼光,考虑长期回报;而监督学习一般考虑一次性的问题,关注短期效益,考虑即时回报。强化学习的这种长远眼光对很多问题找到最优解非常关键。比如,在最短路径的例子中,如果只考虑最近邻居节点,则可能无法找到最短路径。
David Silver博士是AlphaGo的核心研发人员,他提出这样的假设:人工智能=强化学习+深度学习。Russell和Norvig的经典人工智能教材里提到:强化学习可以说包括了整个人工智能。有研究表明,计算机科学中任何可以计算的问题,都可以表达成强化学习问题。
本书前面首先介绍了强化学习,然后介绍了强化学习在游戏、推荐系统、计算机系统、健康医疗、教育、金融、机器人、交通、能源、制造等领域的一些应用。应该说,这里的每个领域都有很多工作、很多方向没有讨论,另外还有很多领域没有包括进来;难免挂一漏万。下图中描述了强化学习的应用领域及方向。可能的应用领域太广了。
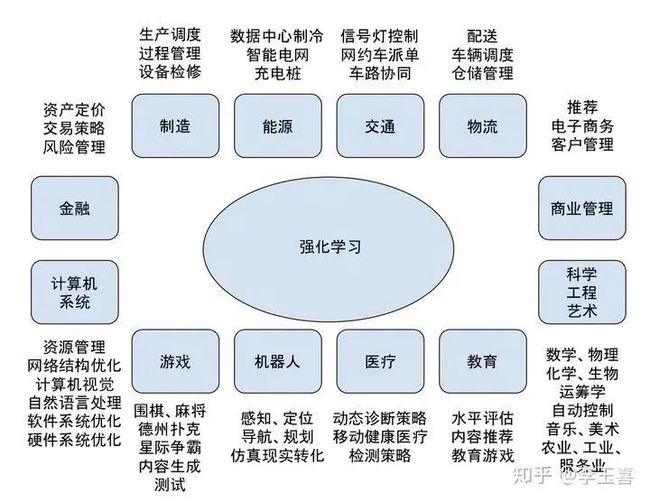 强化学习在计算机系统中的各个方向,从底层的芯片设计、硬件系统,到操作系统、编译系统、数据库管理系统等软件系统,到云计算平台、通信网络系统等基础设施,到游戏引擎、推荐系统等应用程序,到计算机视觉、自然语言处理、机器学习人工智能系统本身,都有广泛的应用。
强化学习在计算机系统中的各个方向,从底层的芯片设计、硬件系统,到操作系统、编译系统、数据库管理系统等软件系统,到云计算平台、通信网络系统等基础设施,到游戏引擎、推荐系统等应用程序,到计算机视觉、自然语言处理、机器学习人工智能系统本身,都有广泛的应用。
对于科学、工程、艺术,本书有所涉及,比如游戏中涉及心理学、设计艺术等,而机器人、交通、能源、制造等与工程密切相关。应该说,对于强化学习在科学、工程、艺术等方面广泛的应用场景,以及这些领域对强化学习的反哺,本书的涉猎有限。
自然科学及工程的问题,一般比较客观,有标准答案,容易评估。如果有模型、比较准确的仿真、或大量数据,强化学习/机器学习就有希望解决问题。AlphaGo是这种情况。组合优化、运筹学、最优控制、药学、化学、基因等方向,基本符合这种情况。社会科学及艺术问题,一般包含人的因素,会受心理学、行为科学等影响,一般比较主观,不一定有标准答案,不一定容易评估。游戏设计及评估、教育等基本符合这种情况。内在动机等心理学概念为强化学习/人工智能与社会科学及艺术之间搭建了联系的桥梁。
深度学习和强化学习分别于2013年和2017年被《麻省理工学院科技评论》评为当年10项突破性技术之一。深度学习已经被广泛应用。强化学习会在实际应用场景中发挥越来越重要的作用。强化学习已经被成功应用于游戏、推荐系统等领域,也可能已经成功应用于量化金融中。目前,强化学习可能还没有被广泛应用于某些场景的产品和服务中;我们也很可能需要对不同情况做不同的分析。不过,如果考虑长期回报,现在很可能是培养、教育、引领强化学习市场的绝佳时机。我们会看到深度学习和强化学习大放异彩。
注释参考文献
Sutton and Barto (2018) 是强化学习的首选教材,而且写的很直观。Szepesvari (2010) 讨论了强化学习算法。Bertsekas (2019) 介绍了强化学习和最优控制。Bertsekas and Tsitsiklis (1996) 讨论了神经元动态规划,理论性比较强。Powell (2011) 讨论了近似动态规划,及其在运筹学中的应用。Powell (2019) 和 Recht (2019) 讨论了强化学习与最优控制的关系。Botvinick et al. (2019) 讨论了强化学习与认知科学、心理学、神经科学的关系。
Csaba Szepesvari在ACM KDD 2020 深度学习日上对强化学习做了全方位的深入剖析,理清了许多错误观念;参见Szepesvari (2020)。我对其做了双语解读,参见《强化学习的“神话”和“鬼话”》,zhuanlan.zhihu.com/p/19。
Goodfellow et al. (2016)、Zhang et al. (2020) 介绍深度学习。周志华(2016)、李航(2019)介绍机器学习。Russell and Norvig (2009) 介绍了人工智能。张钹等(2020) 讨论第三代人工智能。
Mnih et al. (2015) 介绍了深度Q网络 (Deep Q-Network, DQN)。Badia et al. (2020)讨论了Agent57. Silver et al. (2016) 介绍了AlphaGo. Silver et al. (2017) 介绍了AlphaGo Zero;可以不用人类知识就能掌握围棋,超越人类围棋水平。Silver et al. (2018) 介绍了AlphaZero, 把AlphaGo Zero扩展到国际象棋和日本将棋等更多游戏。Tian et al. (2019) 实现、分析了AlphaZero,并提供了开源软件。Moravcik et al. (2017) 介绍了DeepStack;Brown and Sandholm (2017) 介绍了Libratus;是两个无限注双人德州扑克计算机算法。
Vinyals et al. (2019)介绍了AlphaStar,打败了星际争霸人类高手。Jaderberg et al. (2018) 介绍了取得人类水平的夺旗程序。OpenAI (2019)介绍了OpenAI Five,打败了刀塔人类高手。微软在麻将方面取得了进展(Suphx)。冰壶(curling)被称为冰上国际象棋,最近也有进展(Curly)。这些在多玩家游戏上取得的成绩表明强化学习在团队游戏中对战术和战略已经有了一定的掌握。
OpenAI (2018)介绍了人形机器手Dactyl,用来灵巧地操纵实物。Hwangbo et al. (2019)、Lee et al. (2020) 介绍了灵活的四足机器人。Peng et al. (2018) 介绍了仿真人形机器 DeepMimic完成高难度杂技般的动作。Lazic et al. (2018) 研究了数据中心制冷。Segler et al. (2018) 把强化学习应用于化学分子逆合成。Popova et al. (2018) 把强化学习应用于全新药物设计。等等。
DQN结合了Q学习和深度神经元网络,使用了经验回放 (experience replay) 和目标网络 (target network) 技术来稳定训练过程。在经验回放中,经验被存储在回放缓冲器中,然后随机样本用于学习。目标网络保留一份单独的网络参数,用于在学习中使用的网络参数;目标网络定期更新,却并非每个训练迭代步骤都更新。Mnih et al. (2016) 介绍了异步优势行动者-评价者算法(Asynchronous Advantage Actor-Critic, A3C), 其中并行的行动者使用不同的探索方法来稳定训练,而并没有使用经验回放。确定策略梯度可以帮助更高效地估计策略梯度。Silver et al. (2014) 介绍了确定策略梯度 (Deterministic Policy Gradient, DPG);Lillicrap et al. (2016) 将它扩展为深度确定策略梯度 (Deep Deterministic Policy Gradient, DDPG)。可信区域方法对梯度更新设置了约束条件,用来稳定策略优化。Schulman et al. (2015)介绍了可信区域策略优化算法 (Trust Region Policy Optimization, TRPO);Schulman et al. (2017)介绍了近端策略优化算法 (Proximal Policy Optimization, PPO)。Haarnoja et al. (2018)介绍了软行动者-评价者(Soft Actor Critic)算法。2020年谷歌Deepmind设计了Agent57算法,可以在57个雅达利游戏上都取得非常好的成绩。而之前在几款游戏上,比如Montezuma’s Revenge, Pitfall, Solaris和Skiing上,成绩总差强人意。Agent57融合了DQN之后的很多进展,包括分布式学习、短期记忆、片段式记忆、用内在动机方法鼓励直接探索(包括在长时间尺度上和短时间尺度上追求新颖性)、设计元控制器,用来学习如何平衡探索和利用。
值得关注Pieter Abbeel, Dimitri Bertsekas, Emma Brunskill, Chelsea Finn, Leslie Kaelbling, Lihong Li, Michael Littman, Joelle Pineau, Doina Precup, Juergen Schmidhuber, David Silver, Satinder Singh, Dale Schuurmans, Peter Stone, Rich Sutton, Csaba Szepesvari等研究人员,以及像CMU, Deepmind, Facebook, Google, Microsoft, MIT, OpenAI, Stanford, University of Alberta, UC Berkeley等研究机构在强化学习方面的工作。
Amershi et al. (2019)讨论了机器学习中的软件工程;很可能对强化学习也有帮助。作者展示了机器学习工作流的9个阶段:模型需求、数据收集、数据清洗、数据标注、特征工程、模型训练、模型评估、模型部署、以及模型监视。在工作流中有很多反馈回路,比如,在模型训练和特征工程之间;而模型评估和模型监视可能会回到前面任何一个阶段。作者也指出人工智能中的软件工程与以前软件应用中的软件工程的三个不同:1)发现数据、管理数据、为数据确定版本号更复杂、更困难;2)模型定制和模型重用都需要不同的技能;3)人工智能组成部分缺少模块化、复杂的方式纠缠在一起。
现实世界中强化学习面临的挑战的讨论基于Dulac-Arnold et al. (2020) 。机器人高效学习的基础的讨论基于Kaelbling (2020)。里面提到两篇博客:Sutton (2019) The bitter lesson 和 Brooks (2019)A better lesson. 强化学习应用于健康的参考原则基于Gottesman et al. (2019)。Wiens et al. (2019)讨论了在健康医疗中应用机器学习如何做到负责任。人工智能创业:人工智能公司代表一种新的商业模式的讨论基于Casado and Bornstein (2020)。人工智能创业:弥补概念验证与产品的差距的讨论基于Ng (2020)。另外,Alharin et al. (2020), Belle and Papantonis (2020), Lipton (2018) 等讨论可解释性。
Li (2017) 是深度强化学习综述,兼顾了该领域的大方向和细节,在历史发展的背景下讨论了最新的进展。Li (2017) 讨论了六个核心元素:值函数、策略、奖赏、模型、探索-利用、以及表征;讨论了六个重要机制:注意力模型和存储器、无监督学习、分层强化学习、多智能体强化学习、关系强化学习、以及元学习;讨论了12个应用场景:游戏、机器人、自然语言处理、计算机视觉、金融、商业管理、医疗、教育、能源、交通、计算机系统、以及科学、工程、和艺术。
参考文献:
Alharin, A., Doan, T.-N., and Sartipi, M. (2020). Reinforcement learning interpretation methods: A survey. IEEE Access, 8:171058 – 171077.
Amershi, S., Begel, A., Bird, C., DeLine, R., Gall, H., Kamar, E., Nagappan, N., Nushi, B., and Zimmermann, T. (2019). Software engineering for machine learning: A case study. In ICSE.
Badia, A. P., Piot, B., Kapturowski, S., Sprechmann, P., Vitvitskyi, A., and Guo, D. (2020). Agent57: Outperforming the atari human benchmark. ArXiv.
Belle, V. and Papantonis, I. (2020). Principles and practice of explainable machine learning. AXiv.
Botvinick, M., Ritter, S., Wang, J. X., Kurth-Nelson, Z., Blundell, C., and Hassabis, D. (2019). Reinforcement learning, fast and slow. Trends in Cognitive Sciences, 23(5):408–422.
Brooks, R. (2019). A better lesson. rodneybrooks.com/a-bett
Brown, N. and Sandholm, T. (2017). Superhuman ai for heads-up no-limit poker: Libratus beats top professionals. Science.
Casado, M. and Bornstein, M. (2020). The new business of AI (and how its
different from traditional software). a16z.com/2020/02/16/ the-new-business-of-ai-and-how-its-different-from-traditional-software/.
Dulac-Arnold, G., Levine, N., Mankowitz, D. J., Li, J., Paduraru, C., Gowal, S., and Hester, T. (2020). An empirical investigation of the challenges of real-world reinforcement learning. ArXiv.
Gottesman, O., Johansson, F., Komorowski, M., Faisal, A., Sontag, D., Doshi-Velez, F., and Celi, L. A. (2019). Guidelines for reinforcement learning in healthcare. Nature Medicine, 25:14–18.
Goodfellow, I., Bengio, Y., and Courville, A. (2016). Deep Learning. MIT Press.
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In ICML.
Hwangbo, J., Lee, J., Dosovitskiy, A., Bellicoso, D., Tsounis, V., Koltun, V., and Hutter, M. (2019). Learning agile and dynamic motor skills for legged robots. Science Robotics, 4(26).
Kaelbling, L. P. (2020). The foundation of efficient robot learning. Science, 369(6506):915–916.
Lazic, N., Boutilier, C., Lu, T., Wong, E., Roy, B., Ryu, M., and Imwalle, G. (2018). Data center cooling using model-predictive control. In NeurIPS.
Lee, J., Hwangbo, J., Wellhausen, L., Koltun, V., and Hutter, M. (2020). Learning quadrupedal locomotion over challenging terrain. Science Robotics.
Li, Y. (2017). Deep Reinforcement Learning: An Overview. ArXiv.
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. (2016). Continuous control with deep reinforcement learning. In ICLR.
Lipton, Z. C. (2018). The mythos of model interpretability. ACM Queue, 16(3):31–57.
Jaderberg, M., Czarnecki, W. M., Dunning, I., Marris, L., Lever, G., Garcia Castaneda, A., Beat- tie, C., Rabinowitz, N. C., Morcos, A. S., Ruderman, A., Sonnerat, N., Green, T., Deason, L., Leibo, J. Z., Silver, D., Hassabis, D., Kavukcuoglu, K., and Graepel, T. (2018). Human-level performance in first-person multiplayer games with population-based deep reinforcement learning. ArXiv.
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Harley, T., Lillicrap, T. P., Silver, D., and Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In ICML.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., and Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540):529–533.
Moravcik, M., Schmid, M., Burch, N., Lisy, V., Morrill, D., Bard, N., Davis, T., Waugh, K., Johanson, M., and Bowling, M. (2017). Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science, 356(6337):508–513.
Ng, A. (2020). Bridging AI’s proof-of-concept to production gap. youtube. com/watch?v=tsPuVAMaADY.
OpenAI, Andrychowicz, M., Baker, B., Chociej, M., Jozefowicz, R., McGrew, B., Pachocki, J., Petron, A., Plappert, M., Powell, G., Ray, A., Schneider, J., Sidor, S., Tobin, J., Welinder, P., Weng, L., and Zaremba, W. (2018). Learning dexterous in-hand manipulation. ArXiv.
OpenAI, Berner, C., Brockman, G., Chan, B., Cheung, V., Debiak, P., Dennison, C., Farhi, D., Fischer, Q., Hashme, S., Hesse, C., Jozefowicz, R., Gray, S., Olsson, C., Pachocki, J., Petrov, M., de Oliveira Pinto, H. P., Raiman, J., Salimans, T., Schlatter, J., Schneider, J., Sidor, S., Sutskever, I., Tang, J., Wolski, F., and Zhang, S. (2019). Dota 2 with large scale deep reinforcement learning. ArXiv.
Peng, X. B., Abbeel, P., Levine, S., and van de Panne, M. (2018). Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. In SIGGRAPH.
Popova, M., Isayev, O., and Tropsha, A. (2018). Deep reinforcement learning for de novo drug design. Science Advances, 4(7).
Powell, W. B. (2011). Approximate Dynamic Programming: Solving the curses of dimensionality (2nd Edition). John Wiley and Sons.
Powell, W. B. (2019). From reinforcement learning to optimal control: A unified framework for sequential decisions. Arxiv.
Recht, B. (2019). A tour of reinforcement learning: The view from continuous control. Annual Review of Control, Robotics, and Autonomous Systems, 1:253–279.
Russell, S. and Norvig, P. (2009). Artificial Intelligence: A Modern Approach (3rd edition). Pearson.
Schulman, J., Levine, S., Moritz, P., Jordan, M. I., and Abbeel, P. (2015). Trust region policy optimization. In ICML.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal Policy Optimization Algorithms. ArXiv.
Segler, M. H. S., Preuss, M., and Waller, M. P. (2018). Planning chemical syntheses with deep neural networks and symbolic AI. Nature, 555:604–610.
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. (2016). Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489.
Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., and Riedmiller, M. (2014). Deterministic policy gradient algorithms. In ICML.
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., and Hassabis, D. (2018). A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362(6419):1140–1144.
Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., and Riedmiller, M. (2014). Deterministic policy gradient algorithms. In ICML.
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y., Lillicrap, T., Hui, F., Sifre, L., van den Driessche, G., Graepel, T., and Hassabis, D. (2017). Mastering the game of go without human knowledge. Nature, 550:354–359.
Sutton, R. (2019). The bitter lesson. incompleteideas.net/Inc BitterLesson.html.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd Edition). MIT Press.
Szepesvari, C. (2010). Algorithms for Reinforcement Learning. Morgan & Claypool.
Szepesvari, C. (2020). Myths and misconceptions in rl. sites.ualberta.ca/ ̃szepesva/talks.html. KDD 2020 Deep Learning Day.
Tian, Y., Ma, J., Gong, Q., Sengupta, S., Chen, Z., Pinkerton, J., and Zitnick, C. L. (2019). ELF OpenGo: An analysis and open reimplementation of AlphaZero. In ICML.
Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M., Dudzik, A., Chung, J., Choi, D. H., Powell, R., Ewalds, T., Georgiev, P., Oh, J., Horgan, D., Kroiss, M., Danihelka, I., Huang, A., Sifre, L., Cai, T., Agapiou, J. P., Jaderberg, M., Vezhnevets, A. S., Leblond, R., Pohlen, T., Dalibard, V., Budden, D., Sulsky, Y., Molloy, J., Paine, T. L., Gulcehre, C., Wang, Z., Pfaff, T., Wu, Y., Ring, R., Yogatama, D., Wunsch, D., McKinney, K., Smith, O., Schaul, T., Lillicrap, T., Kavukcuoglu, K., Hassabis, D., Apps, C., and Silver, D. (2019). Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575:350–354.
Wiens, J., Saria, S., Sendak, M., Ghassemi, M., Liu, V. X., Doshi-Velez, F., Jung, K., Heller, K., Kale, D., Saeed, M., Ossorio, P. N., Thadaney-Israni, S., and Goldenberg, A. (2019). Do no harm: a roadmap for responsible machine learning for health care. Nature Medicine, 25:1337–1340.
Zhang, A., Lipton, Z. C., Li, M., and Smola, A. J. (2020). Dive into Deep Learning. https: //d2l.ai.
李航. (2019). 统计学习方法(第二版). 清华大学出版社.
张钹, 朱军, 苏航. 迈向第三代人工智能. 中国科学: 信息科学, 2020, 50: 1281–1302, doi: 10.1360/SSI-2020-0204 Zhang B, Zhu J, Su H. Toward the third generation of artificial intelligence (in Chinese). Sci Sin Inform, 2020, 50: 1281–1302, doi: 10.1360/SSI-2020-0204
周志华. (2016). 机器学习. 清华大学出版社
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
