Ubuntu 18.04 YOLOv5 ros_yolo 环境配置 数据集标注
Ubuntu 18.04 YOLOv5 环境配置 GPU
- 提示 确保你有Nvidia显卡,并确定所支持的CUDA版本
- 准备
- CUDA + cuDNN
-
- 安装显卡驱动
- 安装CUDA
- 安装cuDNN
- OpenCV + OpenCV_Contrib
- Yolov5
- ros-yolov5
提示 确保你有Nvidia显卡,并确定所支持的CUDA版本
准备
- Yolov5
- opencv + opencv_contrib (下面使用的 opencv 的版本号为4.5.1 )
- CUDA (下面使用的CUDA版本为10.2,cuDNN版本为8.1.0)
- cuDNN (下载 cuDNN 需要注册Nvidia账号并登录,根据网页引导注册,注意阅读网页介绍,下载的cuDNN 版本需要与 自己安装的 CUDA 版本配套)

CUDA + cuDNN
安装显卡驱动
检查适合自己的显卡驱动
ubuntu-drivers devices

安装显卡驱动
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt install nvidia-driver-465
然后重启电脑即可,可以输入nvidia-smi来查看驱动是否安装成功
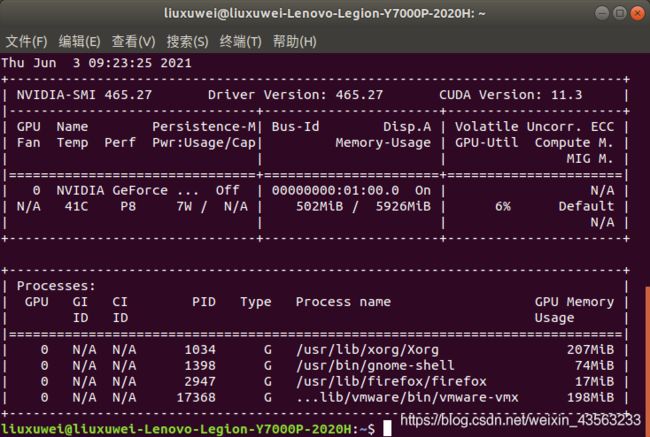
安装CUDA
进入下载好的cuda文件所在的文件夹,打开终端,输入命令:
sudo sh cuda_xxx_linux.run
选择continue,取消勾选Driver,然后安装即可。
然后打开bashrc,输入命令:
sudo gedit ~/.bashrc
在最后添加以下内容:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.2/lib64
export PATH=$PATH:/usr/local/cuda-10.2/bin
具体版本号根据你下载的为准
可以输入nvcc -V检查CUDA是否安装成功
安装cuDNN
解压cuDNN压缩文件
sudo tar -xzvf cudnn-xxx.tgz
会在当前文件夹下生成一个名为cuda的文件夹
然后输入以下命令:
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.2/lib64/
sudo cp cuda/include/cudnn* /usr/local/cuda-10.2/include/
sudo chmod a+r /usr/local/cuda-10.2/include/cudnn.h
sudo chmod a+r /usr/local/cuda-10.2/lib64/libcudnn*
到这里cuDNN就安装完成了
OpenCV + OpenCV_Contrib
打开Ubuntu商店,搜索cmake,安装即可
将下载好的OpenCV-4.5.1源码解压到主目录下,并在OpenCV-4.5.1中新建build文件夹
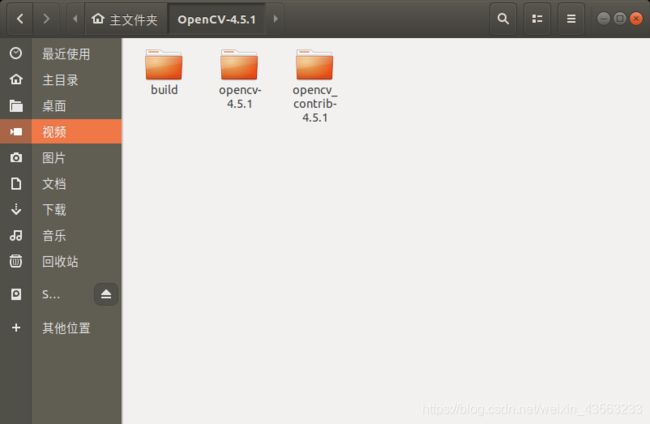
打开CMake,选择源码路径以及编译路径,并勾选Grouped和Advanced
点击Configure,选择Unix Makefiles ,勾选Use default native compilers
点击Configure
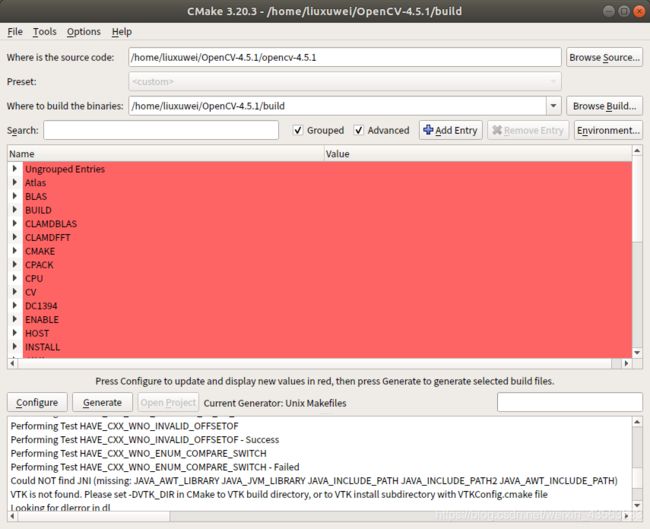
搜索OPENCV_EXTRA_MODULES_PATH,路径选择OpenCV4.5.1/opencv_contrib-4.5.1/modules
搜索cuda,勾选WITH_CUDA和OPENCV_DNN_CUDA
搜索NONFREE ,勾选OPENCV_ENABLE_NONFREE
点击Configure,会有自动下载一些文件。
但是由于网络原因,会下载失败,需要手动下载,打开/OpenCV-4.5.1/build/CMakeDownloadLog.txt,搜索文件内的cmake_download,找到要下载的文件的链接,复制链接,使用迅雷下载。
将下载好的文件复制到/OpenCV-4.5.1/opencv-4.5.1/.cache/下的对应文件夹内。
重新执行Configure,没有下载失败的报错后点击Generate。
然后终端进入OpenCV4.5.1/build
make -j8
注意,make -j后面的数字是线程数,根据你自己的CPU情况选择合适的线程,比如我的CPU是8核16线程,使用8个线程进行编译。
编译完成之后,输入以下命令安装:
sudo make install
opencv 到这里就安装成功了
Yolov5
GitHub地址https://github.com/wudashuo/yolov5
Yolo v5按照网络大小分为四个模型,分别是Yolov5s、Yolov5m、Yolov5l和Yolov5x,它们的准确度和速度的比较如下图所示:

下载上述GitHub链接中的代码,在下载的yolov5-master文件中打开终端,输入以下命令配置环境:
pip3 install -r requirement.txt
【注意】有可能会出现下图中的错误
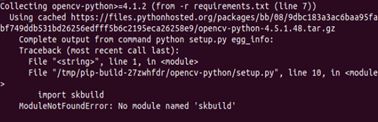
打开终端,输入以下命令即可:
pip3 install scikit-build
然后重新执行以下命令等待安装完成。
pip3 install -r requirement.txt
如果下载速度过慢或下载失败,可以选择其他源下载,比如指定清华源:
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
如果在安装opencv-python时卡住或时间过长,则需要先升级pip3,然后重新执行上述命令:
sudo pip3 install –upgrade pip
通过以上步骤,Yolo v5运行所需的环境就已经配置好了,接下来就可以进行简单的测试。在yolov5-master文件夹下打开终端,然后运行以下命令:
python3 detect.py --source 0 # 本机默认摄像头
file.jpg # 图片
file.mp4 # 视频
path/ # 文件夹下所有媒体
path/*.jpg # 文件夹下某类型媒体
rtsp:// # rtsp视频流
http:// # http视频流
如果没有指定权重,则会自动下载默认的COCO预训练权重模型yolov5s.pt,最终检测结果会保存在./runs/detect/文件夹中,运行结果如下图所示。

当然我们还可以指定权重文件,权重文件下载链接为,将下载好的权重文件放在yolov5-master/weights/文件夹中,下述命令使用yolov5m.pt去检测./data/image文件夹中的所有图片和视频,并设置置信度为0.5:
python3 detect.py --source ./data/images/ --weights ./weights/yolov5m.pt --conf 0.5
在./runs/detect/文件中找到最新的文件夹,里面是最后一次运行的检测结果,如下图所示:
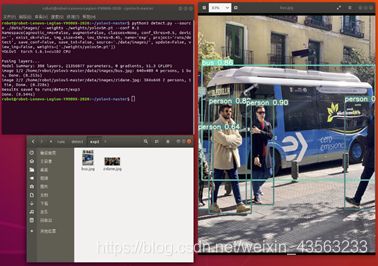
detect命令中可使用的参数及其含义如下:
--source 指定检测来源
--weights 指定权重,不指定的话会使用yolov5s.pt预训练权重
--img-size 指定推理图片分辨率,默认640,也可使用--img
--conf-thres 指定置信度阈值,默认0.4,也可使用--conf
--iou-thres 指定NMS(非极大值抑制)的IOU阈值,默认0.5
--device 指定设备,如--device 0 --device 0,1,2,3 --device cpu
--classes 只检测特定的类,如--classes 0 2 4 6 8
--project 指定结果存放路径,默认./runs/detect/
--name 指定结果存放名,默认exp
--view-img 以图片形式显示结果
--save-txt 输出标签结果(yolo格式)
--save-conf 在输出标签结果txt中同样写入每个目标的置信度
--agnostic-nms 使用agnostic NMS
--augment 增强识别
--update 更新所有模型
--exist-ok 若重名不覆盖
以上的步骤都是使用官方训练好的权重模型进行检测,如果我们想训练自己的数据集,就需要经过采集图片,标注图片和训练模型这三步。下面将会对这些步骤一一介绍。
下载图片将训练集放至yolov5-master/coco/images/train/文件夹内,该训练集有40张图片,只有两个类别,分别是Curry和Durant。将验证集放至yolov5-master/coco/images/val/文件夹内
安装图片标注软件labelImg:
pip3 install labelImg
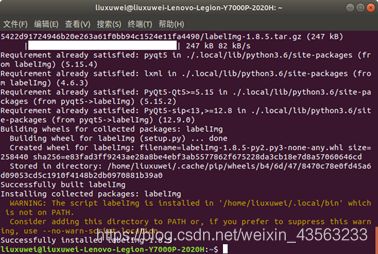
如果出现上图中的错误,请在终端中输入
echo 'export PATH=/home/xxx/.local/bin:$PATH' >>~/.bashrc
source ~/.bashrc
pip3 uninstall labelImg
pip3 install labelImg
打开labelImg
labelImg
可能会出现下图中的错误
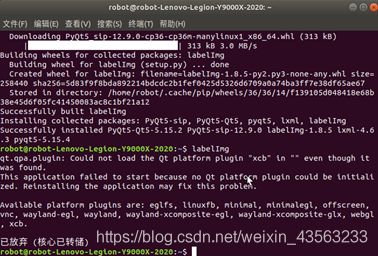
输入以下指令,然后重新打开labelImg:
sudo apt install libxcb-xinerama0
打开目录,选择yolov5-master/coco/images/train/,选中2.jpg,点击创建区块,框选Curry和Durant并设置标签名称为各自的姓名:
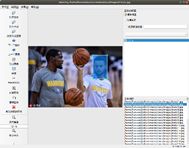
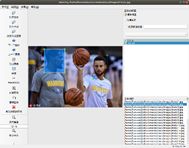
点击保存至图片所在的目录下即可:
完成这些步骤之后,对一张图片进行的标注操作就完成了。剩余的图片请大家遵循上述步骤依次标注。完成标注之后,将train文件夹内的所有xml文件统一移动到yolov5-master/coco/labels/train/内,接下来我们需要自己写一个python程序xml_to_txt.py,将xml文件中的目标位置信息提取到txt格式的文件中。
import glob
import xml.etree.ElementTree as ET
class_names = ['Curry', 'Durant']
path = 'coco/labels/train/'
def single_xml_to_txt(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
txt_file = xml_file.split('.')[0] + '.txt'
with open(txt_file, 'w') as txt_file:
for member in root.findall('object'):
picture_width = int(root.find('size')[0].text)
picture_height = int(root.find('size')[1].text)
class_name = member[0].text
class_num = class_names.index(class_name)
box_x_min = int(member[4][0].text)
box_y_min = int(member[4][1].text)
box_x_max = int(member[4][2].text)
box_y_max = int(member[4][3].text)
x_center = (box_x_min + box_x_max) / (2 * picture_width)
y_center = (box_y_min + box_y_max) / (2 * picture_height)
width = (box_x_max - box_x_min) / picture_width
height = (box_y_max - box_y_min) / picture_height
print(class_num, x_center, y_center, width, height)
txt_file.write(str(class_num)+' '+str(x_center)+' '+str(y_center)+' '
+str(width) +' '+str(height)+'\n')
def dir_xml_to_txt(path):
for xml_file in glob.glob(path + '*.xml'):
single_xml_to_txt(xml_file)
dir_xml_to_txt(path)
将xml_to_txt.py放置在yolov5-master/文件夹下,输入以下命令运行:
python3 xml_to_txt.py
该程序会在yolov5-master/coco/labels/train/文件中生成每一个xml文件对应的txt文件。然后将xml文件删除即可。
对验证集的处理步骤和上述一致,只需将xml_to_txt.py中的path = 'coco/labels/train/'修改为path = ‘coco/labels/val/’。
然后制作一个数据文件,进入到yolov5-master/coco/data/文件夹中,拷贝coco.yaml并重命名为mydata.yaml。打开mydata.yaml,修改训练集、验证集、测试集路径、定义总类别数和定义类别名称。该文件内只保留以下内容:
train: ./coco/images/train/
val: ./coco/images/val/
test: ./coco/images/test/
nc: 2
names: [ 'Curry', 'Durant' ]
完成上述步骤之后,就可以开始训练了,在yolov5-master/文件夹中打开终端,输入以下命令:
#使用yolov5s模型初始化网络训练mydata数据集,300个epochs,batch size设为16
python3 train.py --batch 16 --epochs 300 --data ./data/mydata.yaml --weights ./weights/yolov5s.pt
训练得到的权重文件保存在yolov5-master/runs/train/文件夹中。
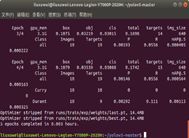
train命令中可使用的参数及其含义如下:
--weights 指定权重,如果不加此参数会默认使用官方预训练的yolov5s.pt
--cfg 指定模型文件
--data 指定数据文件
--hyp 指定超参数文件
--epochs 指训练完整数据的次数,默认300
--batch-size 指一次迭代训练的数据大小,默认16,官方推荐越大越好,用你GPU
能承受最大的。可简写为--batch
--img-size 指定训练图片大小,默认640,可简写为--img
--name 指定结果文件名,默认result.txt
--device 指定训练设备,如--device 0,1,2,3
--local_rank 分布式训练参数,不要自己修改!
--log-imgs W&B的图片数量,默认16,最大100
--workers 指定dataloader的workers数量,默认8
--project 训练结果存放目录,默认./runs/train/
--name 训练结果存放名,默认exp
使用训练好的权重检测图片:
python3 detect.py --source ./coco/images/val/ --weights ./runs/train/exp3/weights/best.pt --conf 0.5
结果如下:

ros-yolov5
工作空间/src目录下执行
cd catkin_ws/src
git clone https://github.com/OuyangJunyuan/ros-yolov5.git
git clone https://github.com/catkin/catkin_simple.git
然后回到工作空间目录下
cd ..
catkin_make
修改ros-yolov5-master/config/config.yaml
weight:/home/liuxuwei/yolov5-master/weights/yolov5l.pt
# 替换为你的yolov5权重文件路径
修改src/demo_service_server.py中首行 #!xxxxxx替换为你的虚拟环境下的python路径,如#!/home/liuxuwei/anaconda3/envs/yolov5/bin/python3.6
修改yolo_bridge.py
self.model = torch.hub.load('ultralytics/yolov5', 'custom', self.weight)
进入之前建好的yolov5虚拟环境下
conda activate yolov5
运行服务端
source devel/setup.bash
roslaunch ros_yolo service_demo.launch
新建终端,运行客户端
cd catkin_ws
source devel/setup.bash
rosrun ros_yolo service_client_demo
可以在service_client_demo.cpp中修改数据来源