卷积神经网络中的基本概念
文章目录
- 前言
- 一、CNN是什么?
-
- CNN的应用
- 二、Convolution(卷积)
-
- 1、 概念
- 2、卷积的应用
- 3、三种卷积方式:
- 三、Pooling(池化层)
- 四、Full Connection(全连接)
- 五、Kernels(卷积核)
- 六、Padding(填充)
-
- padding的用途:
- padding模式:
- 七、Strides(步长)
- 八、Activation(激活)
-
- Sigmoid函数
- tanh函数
- ReLU函数
- Leaky ReLu函数
- 九、Receptive field(感受野)
- 总结
前言
例如:随着人工智能的不断发展,CNN这门技术也越来越重要,很多人都开启了卷积神经网络,本文就介绍了卷积神经网络的基础概念。一、CNN是什么?
卷积神经网络三个结构
神经网络(neural networks)的基本组成包括输入层、隐藏层、输出层。而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)以及激活层。
每一层的作用
卷积层:通过在原始图像上平移来提取特征
激活层:增加非线性分割能力
池化层:压缩数据和参数的量,减小过拟合,降低网络的复杂度,(最大池化和平均池化)
为了能够达到分类效果,还会有一个全连接层(FC)也就是最后的输出层,计算损失进行分类(或回归)。
对于卷积层,卷积层(Convolutional layer),卷积神经网络中每层卷积层由若干卷积单元(卷积核)组成,每个卷积单元的参数都是通过反向传播算法优化得到的。
卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
CNN的应用
之所以CNN会产生,是因为传统神经网络对于输入的数据X(X视为矩阵)维数太高,如果是一张32x32的灰度图片,一个神经元的权重w就需要32x32,为了提取足够丰富的特征,假设需要20个神经元,则权重W(W视为矩阵)的参数个数就是32x32x20=20480个,显示图片的维度不可能是32,可能是上千,那么W的个数就很容易到上亿,这显然太大了!所以我们需要一种可以显著降低计算量的机制,因此CNN孕育而生!
二、Convolution(卷积)
1、 概念
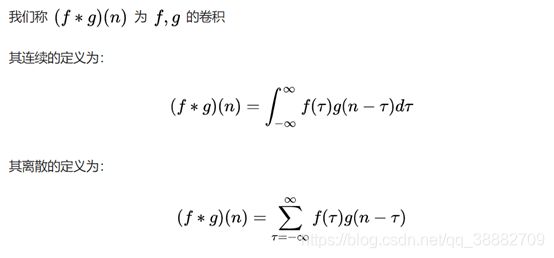
某一时刻的输出是之前很多次输入乘以各自的衰减系数之后的叠加而形成某一点的输出,然后再把不同时刻的输出点放在一起,形成一个函数,这就是卷积。
2、卷积的应用
用一个模板和一幅图像进行卷积,对于图像上的一个点,让模板的原点和该点重合,然后模板上的点和图像上对应的点相乘,然后各点的积相加,就得到了该点的卷积值。对图像上的每个点都这样处理。由于大多数模板都是对称的,所以模板不旋转。
卷积是一种积分运算,用来求两个曲线重叠区域面积。可以看作加权求和,可以用来消除噪声、特征增强。 把一个点的像素值用它周围的点的像素值的加权平均代替。
卷积是一种线性运算,图像处理中常见的mask运算都是卷积,广泛应用于图像滤波。
卷积关系最重要的一种情况,就是在信号与线性系统或数字信号处理中的卷积定理。利用该定理,可以将时间域或空间域中的卷积运算等价为频率域的相乘运算,从而利用FFT等快速算法,实现有效的计算,节省运算代价。
3、三种卷积方式:
● Vaild :卷积核完全在信号内
● Same:卷积核中心在信号内
● Full :卷积核边缘在信号内
三、Pooling(池化层)
作用:
1、通过池化层可以减少空间信息的大小,也就提高了运算效率;
2、减少空间信息也就意味着减少参数,这也降低了overfit的风险;
3、获得空间变换不变性(translation rotation scale invarance,平移旋转缩放的不变性);
最大池化(max pooling)和平均池化(average pooling)
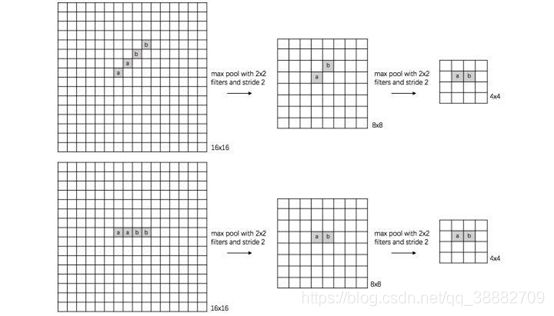
上图证实了空间变换不变性的作用。
平均池化类似,选取的不是每个过滤器的最大值,而是平均值,但是这种方式不常用。
四、Full Connection(全连接)
前面的卷积和池化相当于做特征工程,最后的全连接层在整个卷积神经网络中起到“分类器”的作用(如果FC层作为最后一层,再加上softmax或者wx+b,则可以分别作为分类或回归的作用,即“分类器”或“回归器”的作用);如果作为倒数第2,3层的话,FC层的作用是信息融合,增强信息表达。
五、Kernels(卷积核)
卷积是图像处理常用的方法,给定输入图像,在输出图像中每一个像素是输入图像中一个小区域中像素的加权平均,其中权值由一个函数定义,这个函数称为卷积核。
比如说卷积公式:R(u,v)=∑∑G(u-i,v-j)f(i,j) ,其中f为输入,G为卷积核。
我们直接来说CNN中最重要的卷积核,什么是卷积核,本质就是一个很小的矩阵,如11,33,5*5等。卷积核会在原数据(很高维的大矩阵)上移动,其实就是一个个小的矩阵,在比它大很多的矩阵上移动(移动的步长一般是1,即一次移动1步),每次移动,做一次点乘,得到一个数字。
六、Padding(填充)
之前在讨论卷积神经网络的时候,我们是使用filter来做元素乘法运算来完成卷积运算的。目的是为了完成探测垂直边缘这种特征。但这样做会带来两个问题。
• 卷积运算后,输出图片尺寸缩小;
• 越是边缘的像素点,对于输出的影响越小,因为卷积运算在移动的时候到边缘就结束了。中间的像素点有可能会参与多次计算,但是边缘像素点可能只参与一次。所以我们的结果可能会丢失边缘信息。
那么为了解决这个问题,我们引入padding, 什么是padding呢,就是我们认为的扩充图片, 在图片外围补充一些像素点,把这些像素点初始化为0.
padding的用途:
(1)保持边界信息,如果没有加padding的话,输入图片最边缘的像素点信息只会被卷积核操作一次,但是图像中间的像素点会被扫描到很多遍,那么就会在一定程度上降低边界信息的参考程度,但是在加入padding之后,在实际处理过程中就会从新的边界进行操作,就从一定程度上解决了这个问题。
(2)可以利用padding对输入尺寸有差异图片进行补齐,使得输入图片尺寸一致。
(3)卷积神经网络的卷积层加入Padding,可以使得卷积层的输入维度和输出维度一致。
(4)卷积神经网络的池化层加入Padding,一般都是保持边界信息和(1)所述一样。
padding模式:
SAME和VALID
(1)Valid卷积意味着不填充,这样的话,如果你有一个nn的图像,用一个ff的过滤器卷积,它将会给你一个(n-f+1)*(n-f+1)维的输出。这类似于我们在前面的视频中展示的例子,有一个6×6的图像,通过一个3×3的过滤器,得到一个4×4的输出。
(2)另一个经常被用到的填充方法叫做Same卷积,那意味你填充后,你的输出大小和输入大小是一样的。根据这个公式n-f+1,当你填充个像素点,n就变成了n+2p,最后公式变为n+2p-f+1。因此如果你有一个nn的图像,用p个像素填充边缘,输出的大小就是这样的(n+2p-f+1)(n+2p-f+1)。如果你想让n+2p-f+1=n的话,使得输出和输入大小相等,如果你用这个等式求解p,那么p =(f-1)/2。所以当f是一个奇数的时候,只要选择相应的填充尺寸,你就能确保得到和输入相同尺寸的输出。这也是为什么前面的例子,当过滤器是3×3时,和上一张幻灯片的例子一样,使得输出尺寸等于输入尺寸,所需要的填充是(3-1)/2,也就是1个像素。另一个例子,当你的过滤器是5×5,如果f=5,然后代入那个式子,你就会发现需要2层填充使得输出和输入一样大,这是过滤器5×5的情况。
习惯上,计算机视觉中,f通常是奇数,甚至可能都是这样。你很少看到一个偶数的过滤器在计算机视觉里使用,我认为有两个原因。
(1)其中一个可能是,如果是一个偶数,那么你只能使用一些不对称填充。只有f是奇数的情况下,Same卷积才会有自然的填充,我们可以以同样的数量填充四周,而不是左边填充多一点,右边填充少一点,这样不对称的填充。
(2)第二个原因是当你有一个奇数维过滤器,比如3×3或者5×5的,它就有一个中心点。有时在计算机视觉里,如果有一个中心像素点会更方便,便于指出过滤器的位置。
七、Strides(步长)
可以把卷积核看作是一个矩形窗口,当这个窗口在某个位置完成一次卷积操作后,他需要进行水平or竖直方向上的滑动,‘步长’就是控制每次滑动的距离的。
八、Activation(激活)
现假设一神经网络N,其中w为权值参数,x为输入,b为偏置。神经网络中上层的信号wx+b 在作为下层的输入 之前,需要使用激活函数激活。为什么要使用激活函数激活?
A:如果不用激活函数(其实相当于激活函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。
B : 在网络N中,并不是所有的上一层信号都可以激活下一层,如果所有的上一层信号都可以激活下一层,那么这一层相当于什么都没有做。因此需要选择一些信号激活下一层的神经元。如何表示激活呢?就是当activation function的输出结果是0,就代表抑制;是1,就代表激活。
机器学习中常见的激活函数
Sigmoid函数
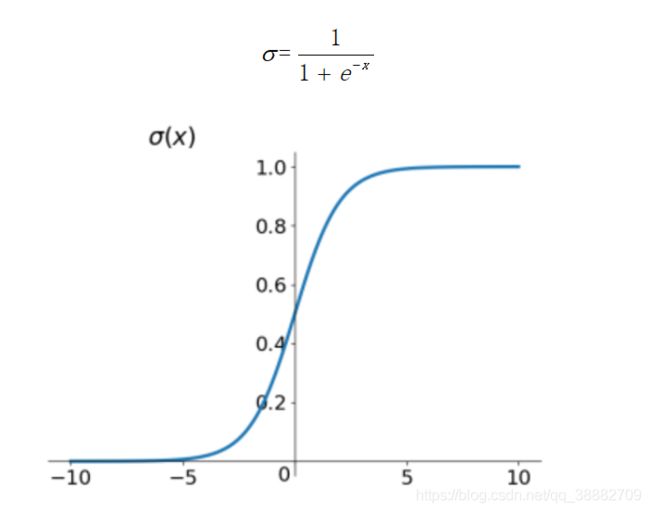
Sigmoid函数是深度学习领域开始时使用频率较高的activation function。它是便于求导的平滑函数,其导数为σ(x)(1−σ(x))σ(x)(1−σ(x)),这是优点。然而,Sigma有三大缺点:
• 容易出现gradient vanishing
• 函数输出并不是zero-centered
• 幂运算相对来讲比较耗时
tanh函数
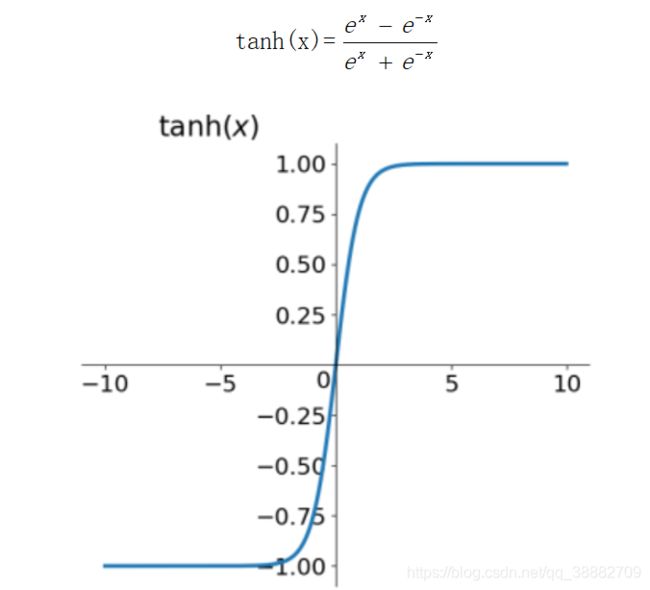
如上图所示,它解决了zero-centered的输出问题,然而,gradient vanishing的问题和幂运算的问题仍然存在。
ReLU函数
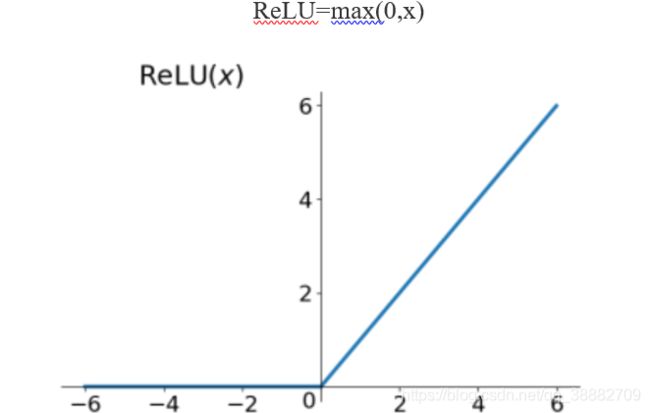
ReLU虽然简单,但是确实近几年的重要成果,有以下几大优点:
• 解决了gradient vanishing的问题(在正区间)
• 计算速度非常快,只需要判断输入是否大于0
• 收敛速度快于Sigmoid和tanh
ReLU也有几个需要特别注意的问题:
(1)ReLU的输出不是zero-centered
(2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生:
• 非常不幸的参数初始化,这种情况比较少见;
• learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法可以采用Xavier初始化方法,以及避免learning rate设置太大或使用adagrad等自动调节learning rate的算法;
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试;
Leaky ReLu函数
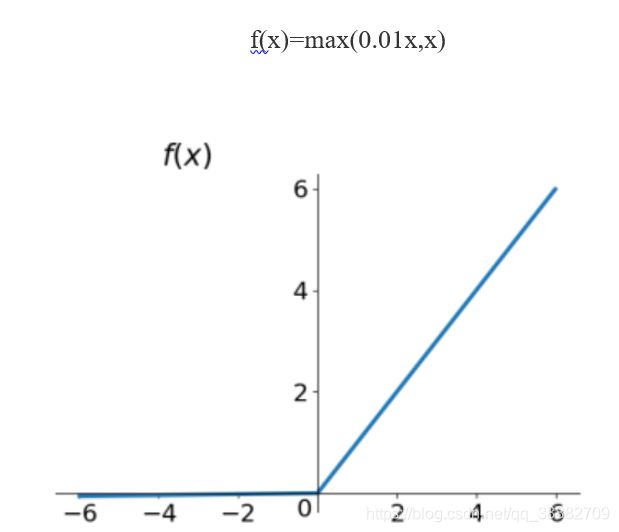
人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为0.01x0.01x而非0。另外一种直观的想法是基于参数的方法,即Parametric ReLU:f(x)=max(αx,x)f(x)=max(αx,x),其中αα可由back propagation学出来。理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
九、Receptive field(感受野)
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域的大小,被称作感受野。通俗的解释是,输出feature map上的一个单元对应输入层上的区域大小。
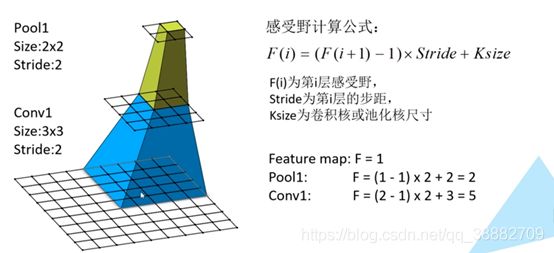
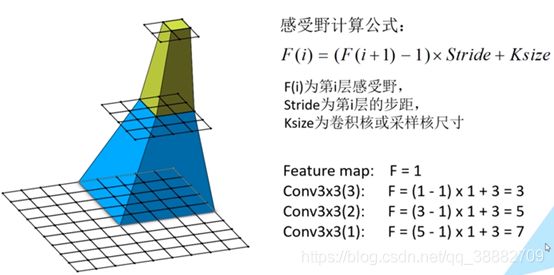

使用多个33的卷积核堆叠来替代77的卷积核原因是通过堆叠多个小的卷积核与大的卷积核对应的感受野相同,并且堆叠多个小的卷积核所需要的参数更少。