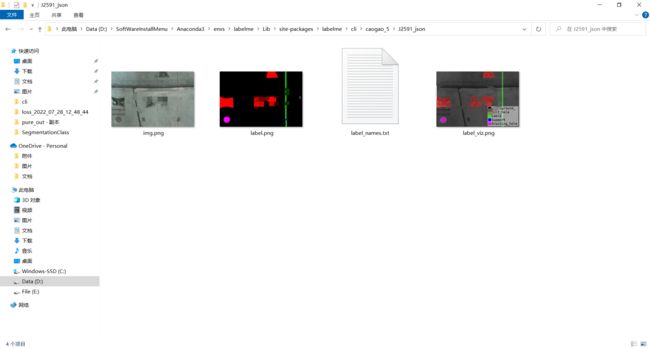
【数据集制作】用于语义分割,labelme4.5.13版本,实现按照指定颜色生成分割颜色批量转换json文件
实现按照指定颜色生成分割颜色批量转换json文件、并生成对应的颜色卡(会比原始转换文件多生成mask、pure两个文件夹)
参考链接
- 图像分割标注工具labelme各个版本改变标注颜色
- labelme的安装、批量转换方法(版本号4.5.13)
以下步骤,均在安装了labelme 4.5.13版本下的环境中操作
这是步骤1的py文件,内容是一样的,我暂存一下文件:百度网盘-提取码: 3rti
我是在相关环境中,找到了labelme这个文件夹,然后用pycharm打开,进行操作的
(不用跟着我单独创建环境哈,只要在任意一个环境下,安装了labelme,然后再用打开labelme文件夹就可以了)
本来直接在cmd中指定好labelme的json_to_dataset.py位置运行就可以,但是因为我想要打断点看看具体情况,所以就用pycharm打开工程来查看了
❀❀❀❀❀❀❀❀❀❀❀❀❀一点废话分割线❀❀❀❀❀❀❀❀❀❀❀❀❀
我是单独创建了一个labelme的环境,安装步骤可参考:labelme的安装、批量转换方法(版本号4.5.13)
然后进入到D:\SoftWareInstallMenu\Anaconda3\envs\labelme\Lib\site-packages,右键在pycharm中打开项目,将json_to_dataset.py的内容直接按照我的代码做更改即可(也可以新建一个py文件),然后改为自己待转换的json文件地址即可
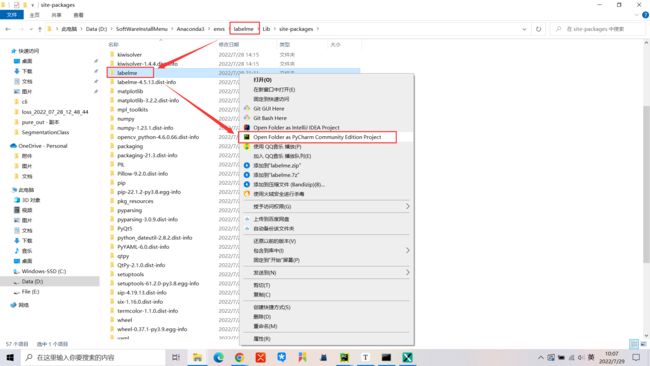
如果想像往常一样,直接调用json_to_dataset.py脚本运行,则按照下图进行更改即可
实现:将指定文件夹下的所有json文件,转化为相应的单个文件夹 + 全部都是标注图像的文件夹
共有3个参数需要您输入,输入格式为:python json_to_dataset.py --json [xxxx] --out [xxxx]
- 运行方式1:
python json_to_dataset.py --json [xxxx]将会默认在json的根目录下生成out、mask文件夹 - 运行方式2:
python json_to_dataset.py --json [xxxx] --out [xxxx]将会在指定目录下生成out、mask文件夹
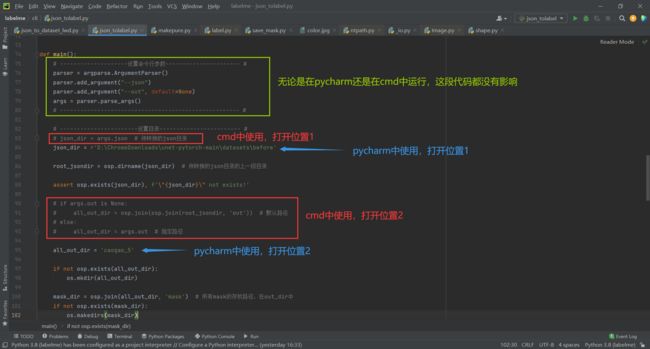
操作步骤
建议还是先在pycharm中打开,再做更改,比较方便,也利于阅读代码
1. 【批量转换】在cli文件夹内新建一个py文件,复制以下代码,例如json_to_dataset_new.py
import argparse
import base64
import json
import os
import os.path as osp
import imgviz
import PIL.Image
from labelme.logger import logger
from labelme import utils
import numpy as np
from PIL import Image, ImageFont, ImageDraw
import re
"""
注意:
1.使用此代码的前提:labelme版本为4.5.13
2.记得在label.py做相应更改,可参考链接:http://t.csdn.cn/wDVPg
"""
# 自己的类别英文名称,注意:'_background_'要保留
cls_name = ['_background_', 'Support', 'Bolt_hole', 'Grouting_hole', 'Cable', 'Pipe', 'Sign', 'Signal_light', 'Railway',
'PJB', 'Instrument_box', 'Crack', 'Falling_block', 'Segment_joint']
# 自己的类别英文名称对应的中文名称
ch_name = {'_background_': '背景', 'Support': '支架', 'Bolt_hole': '螺栓孔', 'Grouting_hole': '注浆孔', 'Cable': '线缆',
'Pipe': '罐道', 'Sign': '标识', 'Signal_light': '信号灯', 'Railway': '铁轨', 'PJB': '接线盒', 'Instrument_box': '设备箱',
'Crack': '裂缝', 'Falling_block': '掉块', 'Segment_joint': '管片缝'}
# (255,255,0) 太黄了,就没要 (128, 128, 0)是分给crack的土黄色
ctuple = [(0, 0, 0), (255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 0, 255), (0, 255, 255), (128, 0, 0), (0, 128, 0),
(0, 0, 128), (128, 128, 0), (128, 0, 128), (0, 128, 128), (128, 128, 128), (255, 64, 128)]
def changeJsonLabelName(json_dir, out_dir):
"""
修改json文件中的某些label
"""
assert os.path.exists(json_dir), f'\"{json_dir}\" not exixts. changeJsonLabelName over!'
if not os.path.exists(out_dir):
os.makedirs(out_dir)
json_files = os.listdir(json_dir)
for json_file in json_files:
jsonfile = os.path.join(json_dir, json_file)
json_out = os.path.join(out_dir, json_file)
# 读单个json文件
with open(jsonfile, 'r', encoding='utf-8') as jf:
load_dict = json.load(jf)
objects = load_dict['shapes']
for i, obj in enumerate(objects):
label = obj['label']
new_name = getcls_id_name(label)[1]
obj['label'] = new_name
# 将替换后的内容写入原文件
with open(json_out, 'w') as new_jf:
json.dump(load_dict, new_jf, indent=2)
print('change name over!')
def getcls_id_name(label):
"""
根据lebal匹配到应该的编号、名称
"""
for i, name in enumerate(cls_name):
if re.match(name, label):
# 如果当前标号cls是 'Sign',就再判断一下是否与'Signal_light'匹配
if name == 'Sign' and re.match('Signal_light', label):
return i + 1, cls_name[i + 1]
return i, name
return -1, 'error'
def create_purepic(colorlist, out_dir, dict=None, add_font=False):
"""
将colorlist给出的颜色做成颜色图片并保存 (并且拼接在一起)
:param colorlist: 要转换的颜色列表
:param out_dir: 保存纯色图片的文件
:return: 无
"""
if not os.path.exists(out_dir):
os.makedirs(out_dir)
pure_size = (300, 300, 3) # HMC
# 将纯色图像拼接在一起 尺寸是 WH
row, col = 3, 5 # 自定义颜色卡上的行数、列数
new_img = Image.new(mode="RGB", size=(pure_size[1] * col, pure_size[0] * row), color=(255, 255, 255)) # 竖着拼接,固定宽度
keys = [key for key in dict] # 字典的keys
for i, color in enumerate(colorlist):
image = np.zeros(pure_size, dtype=np.uint8)
for x in range(3):
if color[x] != 0:
image[..., x] = color[x]
image = Image.fromarray(image)
# add_font=True时,在图片上添加文字
if add_font:
font_en = ImageFont.truetype('C:/Windows/Fonts/timesbd.ttf', size=30) # 粗体
font_zh = ImageFont.truetype('C:/Windows/Fonts/msyhbd.ttc', 30) # 微软雅黑 粗体
draw = ImageDraw.Draw(image)
if not keys: # 如果没有指定dict,也就是没有其它的颜色顺序,就按照默认的ctuple中颜色顺序来
draw.text((30, 30), f'{i - 1}: {cls_name[i]}' if i > 0 else cls_name[i], font=font_en,
fill=(255, 255, 255)) # 英文名
draw.text((30, 70), ch_name[cls_name[i]], font=font_zh, fill=(255, 255, 255)) # 中文名
else: # 如果指定了颜色顺序,就要按照指定的来
draw.text((30, 30), f'{i - 1}: {keys[i]}' if i > 0 else keys[i], font=font_en,
fill=(255, 255, 255)) # 英文名
draw.text((30, 70), ch_name[keys[i]], font=font_zh, fill=(255, 255, 255)) # 中文名
draw.text((30, 110), str(color), font=font_en, fill=(255, 255, 255)) # 写上RGB值
image.save(os.path.join(out_dir, f'pure_{i}.jpg'))
print(f'pure_{i}.jpg had saved.')
new_img.paste(image, (i % col * pure_size[1], i // col * pure_size[0]))
new_img.save(os.path.join(out_dir, 'color.jpg'))
print('color.jpg is done.')
def main():
# json_dir = r'D:\A_dataset\liao_Upan\Concrete Crack Images for Classification\crack_json'
# changeJsonLabelName(json_dir, json_dir)
# --------------------设置命令行参数---------------------- #
parser = argparse.ArgumentParser()
parser.add_argument("--json")
parser.add_argument("--out", default=None)
args = parser.parse_args()
# ----------------------------------------------------- #
# -----------------------设置目录------------------------ #
# json_dir = args.json # 待转换的json目录
# json_dir = r'D:\A_dataset\liao_Upan\orig_labelme_json'
json_dir = r'E:\crack_datasets\Original_Crack_DataSet_1024_1024\json'
root_jsondir = osp.dirname(json_dir) # 待转换的json目录的上一级目录
assert osp.exists(json_dir), f'\"{json_dir}\" not exists!'
# if args.out is None:
# all_out_dir = osp.join(osp.join(root_jsondir, 'out')) # 默认路径
# else:
# all_out_dir = args.out # 指定路径
# all_out_dir = r'D:\A_dataset\liao_Upan\orig_labelme_json_out_91'
all_out_dir = r'E:\crack_datasets\Original_Crack_DataSet_1024_1024\json_out'
if not osp.exists(all_out_dir):
os.mkdir(all_out_dir)
mask_dir = osp.join(all_out_dir, 'mask') # 所有mask的存放路径,在out_dir中
if not osp.exists(mask_dir):
os.makedirs(mask_dir)
# images_dir = osp.join(all_out_dir, 'images') # 所有mask的存放路径,在out_dir中
# if not osp.exists(images_dir):
# os.makedirs(images_dir)
pure_dir = osp.join(all_out_dir, 'pure') # 类别对应的颜色卡
if not osp.exists(pure_dir):
os.makedirs(pure_dir)
# ------------------------------------------------------ #
# -----------------------开始转换------------------------- #
filelist = os.listdir(json_dir) # 文件列表
print(len(filelist))
# label_name_to_value = {"_background_": 0}
for file in filelist: # 遍历文件列表
filename, _ = osp.splitext(file)
path = os.path.join(json_dir, file) # 文件路径
if os.path.isdir(path) or not file.endswith('.json'): # 如果是目录或者不是json文件则读取下一个
continue
son_out = file.replace(".", "_") # 单个文件目录名称
out_dir = osp.join(all_out_dir, son_out) # 兼容out参数 -- 总目录 + 文件目录
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(path)) # 读取目录标注文件
imageData = data.get("imageData")
if not imageData:
imagePath = os.path.join(os.path.dirname(json_dir), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
# for shape in sorted(data["shapes"], key=lambda x: x["label"]): # 将label进行排序
# for shape in data["shapes"]: # 将label进行排序
# label_name = shape["label"]
# # label_name = getcls_id_name(label_name)[1]
# if label_name not in label_name_to_value:
# label_value = len(label_name_to_value)
# label_name_to_value[label_name] = label_value
# 指定类别顺序
label_name_to_value = {'_background_': 0, 'Support': 1, 'Bolt_hole': 2, 'Grouting_hole': 3, 'Cable': 4,
'Pipe': 5, 'Sign': 6, 'Signal_light': 7, 'Railway': 8, 'PJB': 9, 'Instrument_box': 10,
'Crack': 11, 'Falling_block': 12, 'Segment_joint': 13}
# 存类别名索引
lbl, _ = utils.shapes_to_label(
img.shape, data["shapes"], label_name_to_value
)
# 为了写入label_names.txt,记录该图上有哪些类别
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
# 为了做可视化图像label_viz.png,将label、原始图像、类别名称都加到同一张图上进行可视化
lbl_viz = imgviz.label2rgb(
lbl, imgviz.asgray(img), label_names=label_names, loc="rb"
)
PIL.Image.fromarray(img).save(osp.join(out_dir, "img.png"))
utils.lblsave(osp.join(out_dir, "label.png"), lbl) # 做label.png,最有用的标签图
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, "label_names.txt"), "w") as f:
for lbl_name in label_names:
f.write(lbl_name + "\n")
utils.lblsave(osp.join(mask_dir, filename + ".png"), lbl) # 保存label.png到maks文件夹
# PIL.Image.fromarray(img).save(osp.join(images_dir, filename + ".jpg")) # 更改文件后缀为jpg
logger.info("Saved to: {}".format(all_out_dir))
# ---------------------绘制类别对应的颜色卡------------------------------ #
dictlen = len(label_name_to_value)
create_purepic(ctuple[:dictlen], pure_dir, label_name_to_value, True) # 只选取类别个数的颜色
if __name__ == "__main__":
main()
# 可把下面注释打开,把上一行main()先注释掉,看一下纯色图像是什么样子的
# dict = {'_background_': 0, 'Bolt_hole': 0, 'Support': 0, 'Signal_light': 0, 'Cable': 0, 'Pipe': 0, 'PJB': 0,
# 'Grouting_hole': 0, 'Sign': 0, 'Railway': 0, 'Falling_block': 0, 'Instrument_box': 0, 'Crack': 0,
# 'Segment_joint': 0}
#
# pure_dir = 'caogao_pure_last'
# create_purepic(ctuple, pure_dir, dict, True)
2. 【指定颜色映射】⭐
参考链接:图像分割标注工具labelme各个版本改变标注颜色
- 在步骤1的文件中,找到
utils.lblsave(osp.join(out_dir, "label.png"), lbl),大约100行的位置,在该行的lblsave处,Ctrl+鼠标跳至相应文件中 - 跳转后,找到16行左右的
colormap = imgviz.label_colormap(),在label_colormap()处按下Ctrl+鼠标跳至相应文件中 - 最终跳转至
imgviz/label.py文件中,如下图,在43行左右的下方,添加如下代码:
color = [(0, 0, 0), (255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 0, 255), (0, 255, 255), (128, 0, 0), (0, 128, 0),
(0, 0, 128), (128, 128, 0), (128, 0, 128), (0, 128, 128), (128, 128, 128), (255, 64, 128)]
for i, c in enumerate(color):
cmap[i, :] = c
(这段代码的意思就是:指定cmap某些index的像素值是多少。所以不一定要有这样的列表和循环,能懂得cmap[i, :] = c即可,i就是某个index,c就是自行设定的color三元组)
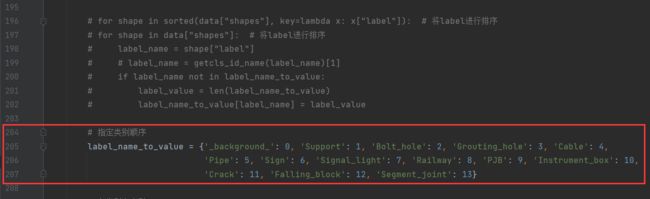
注意:这里的ctuple是配合了步骤1中的205行左右。
- ctuple是指定了调色盘
前面len(ctuple)个的颜色,下图中(步骤1的205行)指定了当前json文件中某个类别在ctuple中的下标,即指定成了ctuple中下标为index的颜色表示的是某个类别。 - 例如,下图中指定了类别
'Support'的index是1,而ctuple[1]=(255,0,0),则导出Support类显示为(255,0,0)即红色。
3. 最终结果
3.1 结果保存文件夹

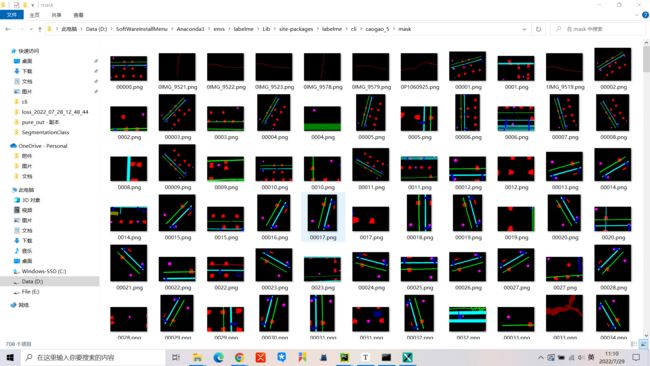
3.2 mask文件夹
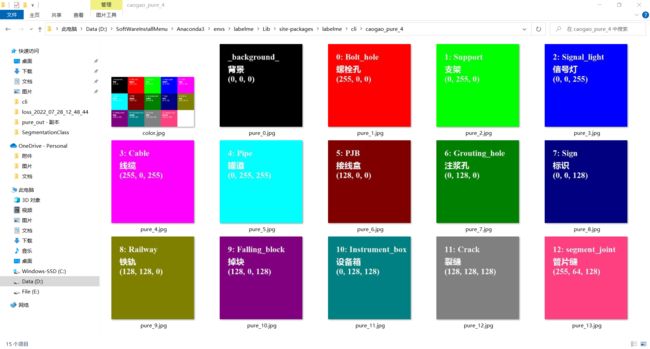
3.3 pure文件夹
3.4 单个json文件夹