ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs论文解读
- 发表时间:2015
- 论文链接:https://arxiv.org/pdf/1512.05193.pdf
- 开源代码:https://github.com/galsang/ABCNN (tensorflow) https://github.com/lsrock1/abcnn_pytorch (pytorch)
- 代码语言:python
- 适用: Answer Slection(AS) paraphrase identification (PI) textual entailment (TE)
BCNN: Bi-CNN
介绍ABCNN之前,要先介绍BCNN,该网络是基于孪生网络,包括了两个权重共享(weight-sharing)的CNN网络,每个CNN网络处理一个句子,最后的层处理句子对(sentence pair)任务. 其结构如下所示:

输入层: 如上图,假设有两个句子,分别含有5个词和7个词(实际应用中要将所有句子通过补padding,补成一样长度s,图中为了理解,按照不同长度展示),通过word embedding可以将每个词表示为一个 d d d维的向量,则输入为 d × s d \times s d×s.
卷积层: 卷积核在时间维(长度s)的大小设为w,则在进行卷积操作时,在输入矩阵的左右各补(w-1)列,输入矩阵变为(batchsize, 1, d d d, s+2(w-1)),然后卷积操作的卷积核大小设置为( d d d, w),滤波器数目为 N N N, 激活函数采用tanh,卷积操作后feature map为(batchsize, N, 1, s+w-1), 交换维度成(batchsize, 1, N, s+w-1).
均值池化层: 从上图可以看出,池化层包括两种, w − a p w-ap w−ap和 a l l − a p all-ap all−ap,对于输出层,采用 a l l − a p all-ap all−ap:对所有列求均值,feature map大小变为(batchsize, N), 即每个句子用一个N维向量表示,再对两个句子对应的N维向量经过某些操作来获取句子对任务得分; w − a p w-ap w−ap:pooling层kernel大小为(1, w),feature map变为(batchsize, 1, N, s),该feature map用于送入下一卷积层.
输出层: 根据具体任务进行选择,如二分类任务,输出层可以为逻辑回归层.
ABCNN: Attention-Based CNN
ABCNN顾名思义就是在BCNN的基础上添加注意力机制,本文提出三种注意力机制:ABCNN-1, ABCNN-2, ABCNN-3.

ABCNN-1: 采用注意力特征矩阵 A ∈ R s × s \bold A \in \bold R^{s \times s} A∈Rs×s来影响卷积, 是对卷积层的输入feature map进行操作的, A \bold A A的第 i i i行表示卷积层输入的左feature map的第 i i i个单元(长度为5的有5个单元)与右feature map每个单元的注意力分布,按Figure 3(a)举例, 为了便于理解,左右两个句子长度按照5和7不同长度介绍,此时矩阵 A ∈ R 5 × 7 \bold A \in \bold R^{5 \times 7} A∈R5×7 , A \bold A A的第1行第1列表示左句子第一个词和右句子第一个词的注意力分布(匹配度), 第1行第2列表示左句子第一个词和右句子第二个词的注意力分布(匹配度). 接下来看一下其数学表达式:
假设左右两个feature map分别为 F 0 , r ∈ R ( d × s ) F_{0,r} \in \bold R^{(d \times s)} F0,r∈R(d×s) 和 F 1 , r ∈ R ( d × s ) F_{1,r} \in \bold R^{(d \times s)} F1,r∈R(d×s) , 则:
A i , j = m a t c h − s c o r e ( F 0 , r [ : , i ] , F : , j ) = 1 1 + ∣ F 0 , r [ : , i ] − F : , j ∣ \bold A_{i,j} = match-score(F_{0,r}[:,i], F_{:,j} ) = \frac{1}{1+|F_{0,r}[:,i]-F_{:,j}|} Ai,j=match−score(F0,r[:,i],F:,j)=1+∣F0,r[:,i]−F:,j∣1
论文中 ∣ ⋅ ∣ | \cdot | ∣⋅∣表示两个向量间的欧式距离, 基于此注意力特征矩阵 A \bold A A,生成两个注意力feature map:
F 0 , a = W 0 ⋅ A T , F 1 , a = W 1 ⋅ A \bold F_{0,a} = \bold W_0 \cdot \bold A^{T}, \bold F_{1,a} = \bold W_1 \cdot \bold A F0,a=W0⋅AT,F1,a=W1⋅A
其中 W 0 ∈ R ( d × s ) \bold W_0 \in \bold R^{(d \times s)} W0∈R(d×s), W 1 ∈ R ( d × s ) \bold W_1 \in \bold R^{(d \times s)} W1∈R(d×s),他们是网络要学习的参数, F 0 , a \bold F_{0,a} F0,a和 F 1 , a \bold F_{1,a} F1,a表现为Figure 3中的红色矩阵,然后将 F i , a \bold F_{i,a} Fi,a和 F i , r \bold F_{i,r} Fi,r作为两个channel构成新的feature map送入卷积层.
ABCNN-2: 由上述介绍可以知道,ABCNN-1在卷积层的输入上计算注意力权重,旨在改善卷积计算的feature map,接下来介绍的ABCNN-2是在卷积的输出上计算注意力权重,旨在reweighting卷积层的输出.
注意力矩阵 A ∈ R s × s \bold A \in \bold R^{s \times s} A∈Rs×s中的行列意义和ABCNN-1相同, a 0 , j = ∑ A [ j , : ] a_{0,j} = \sum \bold A[j,:] a0,j=∑A[j,:]表示左句子 s 0 s_0 s0中第j个单元的注意力权重, a 1 , j = ∑ A [ : , j ] a_{1,j} = \sum \bold A[:,j] a1,j=∑A[:,j]表示右句子 s 1 s_1 s1中第j个单元的注意力权重, F i , r c ∈ R d × ( s i + w − 1 ) \bold F_{i,r}^c \in \bold R^{d \times (s_i +w -1)} Fi,rc∈Rd×(si+w−1)(和BCNN中卷积层的输出对应上了)为卷积层输出, 则新的feature map F i , r p \bold F_{i,r}^p Fi,rp的第 j j j列通过w-ap产生:
F i , r p [ : , j ] = ∑ k = j : j + w a i , k F i , r c [ : , k ] \bold F_{i,r}^p[:,j]=\sum_{k=j:j+w}a_{i,k}\bold F_{i,r}^c[:,k] Fi,rp[:,j]=k=j:j+w∑ai,kFi,rc[:,k]
结合Figure 3(b)来理解一下这个公式,只看左侧(右侧同理),卷积输出feature map F i , r c \bold F_{i,r}^c Fi,rc大小为 8 × 7 8 \times 7 8×7 , w = 3 w=3 w=3, 看一下7 = 5+3-1(s+w-1),跟BCNN卷积层中的讲解相对应,左侧中间虚框的向量则为 a 0 a_0 a0, F : , 0 = a 0 , 0 F i , r c [ : , 0 ] + a 0 , 1 F i , r c [ : , 1 ] + a 0 , 2 F i , r c [ : , 2 ] \bold F_{:,0} = a_{0,0}\bold F_{i,r}^c[:,0] + a_{0,1}\bold F_{i,r}^c[:,1] + a_{0,2}\bold F_{i,r}^c[:,2] F:,0=a0,0Fi,rc[:,0]+a0,1Fi,rc[:,1]+a0,2Fi,rc[:,2] , 则新feature map矩阵的第一列是由卷积输出feature map矩阵的前三列乘以对应前三个加权值的和, 可以看成是一个 8 × 3 8 \times 3 8×3的滑动窗, 步长为1, 第二列 F : , 1 = a 0 , 1 F i , r c [ : , 1 ] + a 0 , 2 F i , r c [ : , 2 ] + a 0 , 3 F i , r c [ : , 3 ] \bold F_{:,1} = a_{0,1}\bold F_{i,r}^c[:,1] + a_{0,2}\bold F_{i,r}^c[:,2] + a_{0,3}\bold F_{i,r}^c[:,3] F:,1=a0,1Fi,rc[:,1]+a0,2Fi,rc[:,2]+a0,3Fi,rc[:,3] ,以此类推得到新feature map矩阵,大小为 8 × 5 8 \times 5 8×5,当卷积层filters数目N与输入feature map的H(每个词的向量维度)相同时,卷积层输入和输出尺度相同,这就使得可以堆叠多个这样的卷积-池化块来提取特征.
ABCNN-3: 该注意力机制是结合了ABCNN-1和ABCNN-2两种.
实验
设置
在三个任务上进行实验验证:AS PI TE
word Embedding通过word2vec初始化,维度为300,训练过程中word Embedding不变,其他参数随机初始化, k-1个卷积-池化块堆叠进行特征提取,最后输出采用逻辑回归层,逻辑回归层的输入为k个consine相似度得分,每个卷积层输出的feature map进行all-ap,左右两个all-ap输出向量求cosine相似度, 一共有k-1个cosine相似度得分,第一层卷积的输入也进行相同操作求cosine相似度,所以一共得到k个相似度得分,这k 个相似度得分堆叠成一个一维向量,送入全连接层(权重 w ∈ R k × 2 \bold w \in \bold R^{k \times 2} w∈Rk×2) .
结果
- AS任务
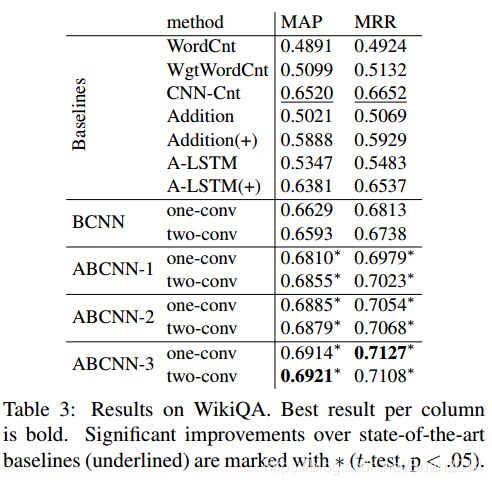
one-conv表示一个卷积-池化块, two-conv表示两个卷积-池化块. - PI任务
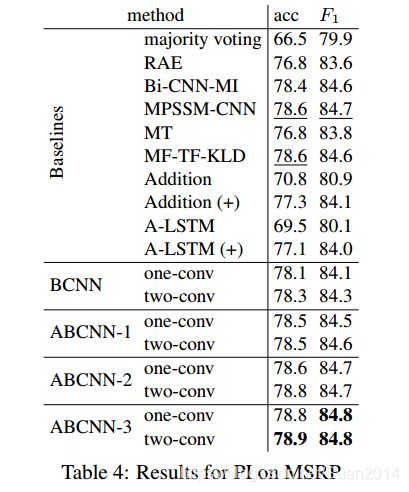
- TE任务
