C++在windows平台上布置yolov5
一、环境配置
环境:windows11,MX250,VS2019,pycharm,cmake,libtorch,pytorch,tensorrtx,opencv,cuda,cudnn
1.CUDA的下载及其安装:
①:选择版本
打开英伟达控制面板(NVIDIA Control Panel)

系统信息-》组件:从此处可以看出所支持最高版本的cuda,但是可能有libtorch和pytorch无法支持这么高版本的cuda,所以此处选择了cuda11.6.0

链接如下: https://developer.nvidia.com/cuda-toolkit-archive
将下载下来的exe运行进行安装,注意在安装选项中选择自定义安装,一定要包含vs那一项,这边建议全选;
2.CUDnn的下载及其安装:
下载链接:https://developer.nvidia.com/rdp/cudnn-download
选择合适版本后将bin,include,lib中的文件复制到cuda安装路径同名文件夹即可
3.opencv以及litorch安装:
下载链接:https://opencv.org/releases/
下载链接:PyTorch
libtorch的版本一定要和cuda的对应!(除此之外,pytorch的版本也要和cuda对应,否则无法在pycharm中训练模型和进行,模型转换)
此处我选择的是11.6的libtorch

1.用vs建立一个新项目
2.右键选择属性

在vc++目录中进行包含目录和库目录的路径选择
包含目录有:D:\opencv_lib\opencv\build\include
D:\libtorch_lib\libtorch-win-shared-with-deps-1.12.1+cu116\libtorch\include
D:\libtorch_lib\libtorch-win-shared-with-deps-1.12.1+cu116\libtorch\include\torch\csrc\api\include
库目录有:D:\libtorch_lib\libtorch-win-shared-with-deps-1.12.1+cu116\libtorch\lib
D:\opencv_lib\opencv\build\x64\vc15\lib(也可以选择vc14)


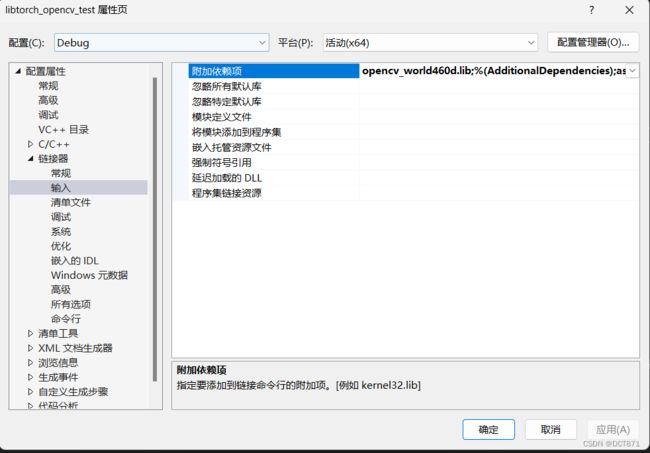
在链接器->输入->附加依赖项:将libtorch中的后缀为.lib的文件全部添加

选择左上角的所有配置,将其修改为debug配置,将opencv_world460d.lib添加进去
同理左上角配置为release时,将opencv_world460.lib添加进去。

4.tensorrtx安装:
下载链接:NVIDIA TensorRT Download | NVIDIA Developer
在其中选择适合的版本,即要对应上合适的
将下载的压缩包解压,然后放到自己合适的目录。如:D:\ProgramData\TensorRT-8.5.1.7
将解压后目录中的lib绝对路径添加到环境变量。
将lib目录下的dll文件复制到CUDA目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\bin。
5.环境变量的配置:
选择高级系统设置
选择环境变量选择path添加如下路径
复制下列代码选择其中对应部分可以分别验证opencv和libtorch是否有问题
//#include
//#include
//int main() {
// torch::Tensor data = torch::rand({ 3, 3 });
// std::cout << data << std::endl;
// std::cout << torch::cuda::is_available() << std::endl;
// return 0;
//}
#include
#include
#include
using namespace cv;
int main() {
//torch::Tensor data = torch::rand({ 3, 3 });
//std::cout << data << std::endl;
//std::cout << torch::cuda::is_available() << std::endl;
//return 0;
/*VideoCapture cap(0);
if (!cap.isOpened()) {
std::cout << "!!!";
return -1;
}
Mat frame;
bool judge = true;
namedWindow("test1");
while (judge)
{
cap >> frame;
if (frame.empty()) break;
imshow("test1", frame);
if (27 == waitKey(30)) {
break;
}
}
destroyWindow("test1");
return 0;*/
} 二、进行pt至wts文件的转换
首先要下载如下的几个库文档:
注意版本的选择,我选择的是yolov5-6.0
下载链接:https://github.com/Monday-Leo/Yolov5_Tensorrt_Win10
GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
注意选择yolov5的版本
1.将Yolov5_Tensorrt_Win10-master文件夹中的gen_wts.py文件复制到yolov5的文件目录下
在此目录下放置已经训练完成的.pt文件,进行转换,此处使用官方的案例pt文件,
2.打开pycharm使用搭建好的yolo环境
此处见:https://blog.csdn.net/ECHOSON/article/details/121939535?spm=1001.2014.3001.5502
将输入,输出的网络文件进行修改
parser.add_argument('--weights', default="yolov5s.pt", help='Input weights (.pt) file path (required)')
parser.add_argument('--output', default="yolov5s.wts", help='Output (.wts) file path (optional)')
也可以在命令行中直接运行:-w参数为输入pt模型路径,-o参数为输出wts模型的路径。
python gen_wts.py -w yolov5s.pt -o yolov5s.wts
将使用的硬件改为默认显卡(从“cpu“改为”0“)
device = select_device('0')运行该文件,从而得到了yolov5s.wts这一个网络文件。
三、进行工程编译
打开Yolov5_Tensorrt_Win10-master中的CMakeLists.txt文件;
1.将调用的环境路径按照如下进行更改 分别是opencv的build;tensorrt的位置以及本文件目录下的include。
 2.要将此处的-gencode;arch=compute_61;code=sm_61中的61改为适合自己显卡的算力数值
2.要将此处的-gencode;arch=compute_61;code=sm_61中的61改为适合自己显卡的算力数值
查看链接:CUDA GPUs - Compute Capability | NVIDIA Developer
或者在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\extras\demo_suite下的目录下进入命令行执行deviceQuery.exe,即可见其中6.1乘以10,即为该显卡算力。

3.打开cmake
在Yolov5_Tensorrt_Win10-master下建立build文件夹
第一行选择CMakeLists.txt目录
第三行选择其下的build文件夹
点击configure,按照如下进行配置(选择对vs版本)

configure无错后genrate然后打开工程,在yololayer.h中进行修改,修改为你训练模型的类别和图像大小
重新生成

打开build下的release文件夹会看到三个文件
将之前的wts文件复制过来
打开命令行,执行如下命令,前者为之前转化过来的wts文件,后者为生成的engine文件,使用的s模型最后加s,如果使用m模型最后改为m。执行该行代码可以需要一段时间10~30分钟
yolov5 -s yolov5s.wts yolov5s.engine s
生成后可以进行图片的检测
yolov5 -d yolov5s.engine ./pic到此步模型的转换已经完成
四、实现实时视频检测
将yolov5.cpp中的函数进行如下的修改(其实就是将命令进行了修改,然后从图片检测转变为了视频检测)
bool parse_args(int argc, char** argv, std::string& engine) {
if (argc < 3) return false;
if (std::string(argv[1]) == "-v" && argc == 3) {
engine = std::string(argv[2]);
}
else {
return false;
}
return true;
}
int main(int argc, char** argv) {
cudaSetDevice(DEVICE);
//std::string wts_name = "";
std::string engine_name = "";
//float gd = 0.0f, gw = 0.0f;
//std::string img_dir;
if (!parse_args(argc, argv, engine_name)) {
std::cerr << "arguments not right!" << std::endl;
std::cerr << "./yolov5 -v [.engine] // run inference with camera" << std::endl;
return -1;
}
std::ifstream file(engine_name, std::ios::binary);//以二进制的方式打开engine文件
if (!file.good()) {
std::cerr << " read " << engine_name << " error! " << std::endl;
return -1;
}
char* trtModelStream{ nullptr };
size_t size = 0;
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
// prepare input data ---------------------------
static float data[BATCH_SIZE * 3 * INPUT_H * INPUT_W];
//for (int i = 0; i < 3 * INPUT_H * INPUT_W; i++)
// data[i] = 1.0;
static float prob[BATCH_SIZE * OUTPUT_SIZE];
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
assert(engine != nullptr);
IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
assert(engine->getNbBindings() == 2);
void* buffers[2];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
// Create stream
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
cv::VideoCapture capture(0);
//cv::VideoCapture capture("../overpass.mp4");
//int fourcc = cv::VideoWriter::fourcc('M','J','P','G');
//capture.set(cv::CAP_PROP_FOURCC, fourcc);
if (!capture.isOpened()) {
std::cout << "Error opening video stream or file" << std::endl;
return -1;
}
int key;
int fcount = 0;
while (1)
{
cv::Mat frame;
capture >> frame;
if (frame.empty())
{
std::cout << "Fail to read image from camera!" << std::endl;
break;
}
fcount++;
//if (fcount < BATCH_SIZE && f + 1 != (int)file_names.size()) continue;
for (int b = 0; b < fcount; b++) {
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
cv::Mat img = frame;
if (img.empty()) continue;
cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox BGR to RGB
int i = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[b * 3 * INPUT_H * INPUT_W + i] = (float)uc_pixel[2] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
}
// Run inference
auto start = std::chrono::system_clock::now();
doInference(*context, stream, buffers, data, prob, BATCH_SIZE);
auto end = std::chrono::system_clock::now();
//std::cout << std::chrono::duration_cast(end - start).count() << "ms" << std::endl;
int fps = 1000.0 / std::chrono::duration_cast(end - start).count();
std::vector> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(frame, res[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(frame, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
std::string jetson_fps = " FPS: " + std::to_string(fps);
cv::putText(frame, jetson_fps, cv::Point(11, 80), cv::FONT_HERSHEY_PLAIN, 3, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
}
//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);
}
cv::imshow("yolov5", frame);
key = cv::waitKey(1);
if (key == 'q') {
break;
}
fcount = 0;
}
capture.release();
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
再到release文件夹下执行该命令即可
yolov5 -v yolov5s.engine