搭建深度学习框架(六):实现LSTM网络的搭建
上一节已经实现了MLP网络的搭建、运用和框架的发布,这一节将实现LSTM网络的搭建和运用。
代码下载地址:xhpxiaohaipeng/xhp_flow_frame
1.LSTM的实现原理
本人在我的硕士毕业论文中已经对LSTM的实现原理做了具体分析和公式推导,本文的LSTM代码就是依据毕业论文内的公式推导实现的,有兴趣的可以下载进行查看,这里不做具体分析。
主要核心内容可参考如下:
(1)LSTM细胞,主要包括三个门,遗忘门、输入门,输出门。
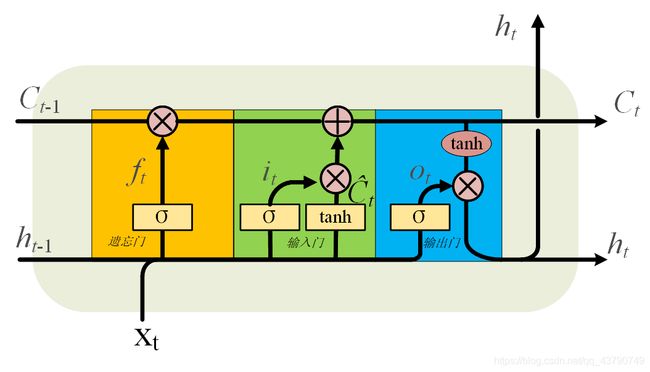
单个LSTM细胞前馈过程如下:
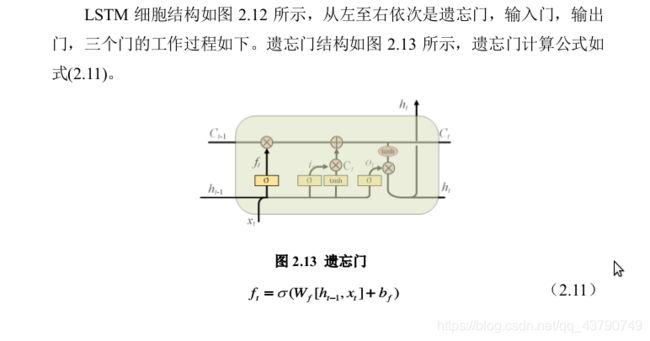
(I).遗忘门
(ii).输入门
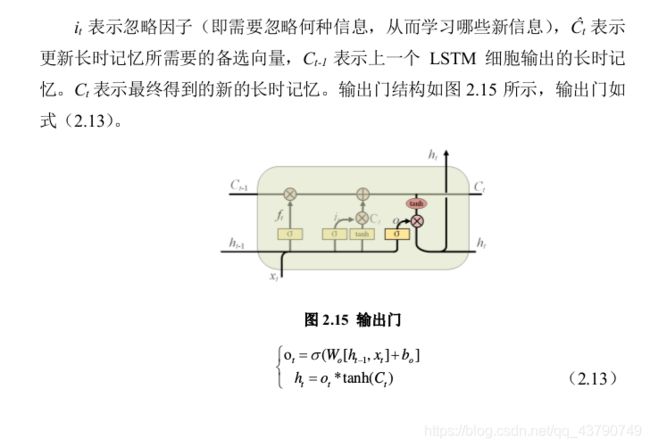
(III).输出门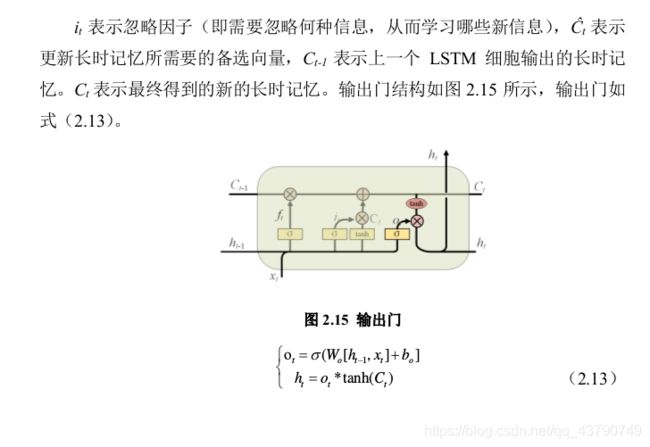
(2). LSTM网络,由多个LSTM细胞构成,每个LSTM细胞的输入包括现在的输入x和上个LSTM细胞输出的细胞状态C和隐藏状态h。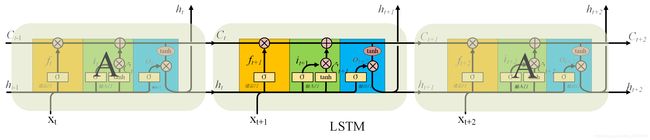
那么反向传播的计算公式如下:
(I)对于两个LSTM细胞构成的网络,公式推导如下:


(II)那么对于N个LSTM细胞组成的网络,公式推导如下:

2.LSTM代码实现
(1)LSTM细胞的前馈过程和反向传播过程实现。
class LSTMcell():
def __init__(self, x, wf, wi, wc, wo, bf, bi, bc, bo, input_size, hidden_size, s_prev=None, h_prev=None):
super(LSTMcell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
"""
判断输入变量的特征大小是否正确
"""
assert x.shape[2] == input_size ,'input expect size:{},but get size:{}!!'.format(input_size,x.shape[2])
"""
初始化计算变量
"""
self.f = np.zeros((x.shape[0], x.shape[1], hidden_size))
self.i = np.zeros((x.shape[0], x.shape[1], hidden_size))
self.c = np.zeros((x.shape[0], x.shape[1], hidden_size))
self.o = np.zeros((x.shape[0], x.shape[1], hidden_size))
self.s = np.zeros((x.shape[0], x.shape[1], hidden_size))
self.h = np.zeros((x.shape[0], x.shape[1], hidden_size))
self.xc= np.zeros((x.shape[0], x.shape[1], hidden_size+input_size))
self.wf = wf
self.wi = wi
self.wc = wc
self.wo = wo
"""
统一将偏置变量设为一维变量
"""
self.bf = bf.squeeze()
self.bi = bi.squeeze()
self.bc = bc.squeeze()
self.bo = bo.squeeze()
self.h_prev = h_prev
self.s_prev = s_prev
self.gradients = {}
self.x = x
def sigmoid(self,x):
return 1. / (1 + np.exp(-x))
def forward(self):
"""
如果输入的第一个LSTM细胞,初始化隐藏状态向量和细胞状态向量
"""
if self.s_prev is None:
self.s_prev = np.zeros((self.x.shape[0], self.x.shape[1], self.hidden_size))
if self.h_prev is None:
self.h_prev = np.zeros((self.x.shape[0], self.x.shape[1], self.hidden_size))
"""
LSTM细胞前向计算
"""
self.xc = np.concatenate((self.x,self.h_prev),axis=2)
self.f = self.sigmoid(np.matmul(self.xc,self.wf) + self.bf)
self.i = self.sigmoid(np.dot(self.xc,self.wi) + self.bi)
self.c = np.tanh(np.dot(self.xc,self.wc) + self.bc)
self.s = self.c*self.i + self.s_prev*self.f
self.o = self.sigmoid(np.dot(self.xc,self.wo) + self.bo)
self.h = np.tanh(self.s)*self.o
def diff_sigmoid(self, x):
return (1. - x) * x
def diff_tanh(self, x):
return 1. - x ** 2
def backward(self):
"""
LSTM细胞反向梯度计算,基于乘法运算求导和链式法则求导
"""
"""
公共的梯度
"""
ds = self.diff_tanh(np.tanh(self.s))
"""
各梯度
"""
df = self.s_prev * self.diff_sigmoid(self.f) * self.o * ds
di = self.c * self.diff_sigmoid(self.i) * self.o * ds
dc = self.i * self.diff_tanh(self.c) * self.o * ds
do = np.tanh(self.c) * self.diff_sigmoid(self.o)
dxc = self.o * self.diff_tanh(self.c)*(self.s_prev * self.diff_sigmoid(self.f) * self.wf + \
self.i*self.diff_tanh(self.c)*self.wc + self.c * \
self.diff_sigmoid(self.i)*self.wi ) + np.tanh(self.s) * \
self.diff_sigmoid(self.o)*self.wo
ds_prev = self.o * ds * self.f
"""
取一个batch_size梯度的平均值作为最后的梯度值
"""
self.xc = np.concatenate((self.x, self.h_prev), axis=2)
self.xc = self.xc.transpose(0, 2, 1)
self.gradients['wf'] = np.mean(np.multiply(self.xc,df),axis=0,keepdims=False)
self.gradients['wi'] = np.mean(np.multiply(self.xc,di),axis=0,keepdims=False)
self.gradients['wc'] = np.mean(np.multiply(self.xc,dc),axis=0,keepdims=False)
self.gradients['wo'] = np.mean(np.multiply(self.xc,do),axis=0,keepdims=False)
self.gradients['bf'] = np.mean(df,axis=0,keepdims=False)
self.gradients['bi'] = np.mean(di,axis=0,keepdims=False)
self.gradients['bc'] = np.mean(dc,axis=0,keepdims=False)
self.gradients['bo'] = np.mean(do,axis=0,keepdims=False)
self.gradients['xc'] = np.mean(dxc,axis=0,keepdims=False)
self.gradients['x'] = self.gradients['xc'][:self.x.shape[2]]
self.gradients['h_prev'] = self.gradients['xc'][self.x.shape[2]:]
self.gradients['s_prev'] = ds_prev
(2).LSTM网络的前馈过程和反向传播过程。
class LSTM(Node):
def __init__(self, input_x, wf, wi, wc, wo, bf, bi, bc, bo, input_size, hidden_size,
h_prev = None,s_prev = None,name='LSTM', is_trainable=False):
Node.__init__(self, [input_x, wf, wi, wc, wo, bf, bi, bc, bo], \
name=name, is_trainable=is_trainable)
"""
初始化变量值
"""
self.input_size = input_size
self.hidden_size = hidden_size
self.input_x = input_x
self.wf = wf
self.wi = wi
self.wc = wc
self.wo = wo
self.bf = bf
self.bi = bi
self.bc = bc
self.bo = bo
"""
用来传递初始细胞状态和隐藏状态
"""
self.h_ = h_prev
self.s_ = s_prev
def forward(self):
assert self.input_x.value.ndim == 3, 'expect 3 dim input,but get {} dim input!!'.format(self.input_x.ndim)
"""
定义存储LSTM细胞的列表容器,不能在init里定义,
否则所有输入的LSTM细胞都会被保存在列表里,
不会随着输入的更新而清空并更新列表
"""
self.lstm_node_list = []
"""
初始细胞状态和隐藏状态不能在init里定义,
否则上一个输入的最后一个LSTM细胞的细胞
状态和隐藏状态输出会被记住,并用于下一个
输入的初始细胞状态和隐藏状态输入,这会造成无法训练。
"""
self.s_prev = self.s_
self.h_prev = self.h_
"""
按照输入变量依次填入LSTM细胞
"""
for i in range(self.input_x.value.shape[1]):
"""
把前一个LSTM细胞输出的隐藏状态和细胞状态
传递给下一个LSTM细胞
"""
if len(self.lstm_node_list) > 0:
self.s_prev = self.lstm_node_list[i-1].s
self.h_prev = self.lstm_node_list[i-1].h
"""
按照输入数据的顺序依次填入LSTM细胞
"""
self.lstm_node_list.append(LSTMcell(self.input_x.value[:,i,:][:,None,:], self.wf.value, self.wi.value, self.wc.value, self.wo.value, \
self.bf.value, self.bi.value, self.bc.value, self.bo.value, self.input_size, self.hidden_size, self.s_prev, self.h_prev))
"""
LSTM细胞进行前向计算
"""
self.lstm_node_list[i].forward()
"""
合并LSTM细胞的输出结果作为LSTM的输出
"""
if i == 0:
self.value = self.lstm_node_list[i].h
else:
self.value = np.concatenate((self.value, self.lstm_node_list[i].h), axis=1)
def backward(self):
"""
初始化各个梯度值为0
"""
self.gradients[self.wf] = np.zeros_like(self.wf.value)
self.gradients[self.wi] = np.zeros_like(self.wi.value)
self.gradients[self.wc] = np.zeros_like(self.wc.value)
self.gradients[self.wo] = np.zeros_like(self.wo.value)
self.gradients[self.bf] = np.zeros_like(self.bf.value).squeeze()
self.gradients[self.bi] = np.zeros_like(self.bi.value).squeeze()
self.gradients[self.bc] = np.zeros_like(self.bc.value).squeeze()
self.gradients[self.bo] = np.zeros_like(self.bo.value).squeeze()
"""
实际上与LSTM网络连接的MLP,相当于只与最后一个LSTM细胞相连,
因为最后的梯度更新都会流向最后一个LSTM细胞, 相当于梯度更新
只与最后一个LSTM细胞有关
"""
self.gradients[self.input_x] = np.zeros_like(self.input_x.value[:,0,:])
"""
按照倒序进行梯度计算
将节点反转过来求梯度
"""
for backward_node_index in range(len(self.lstm_node_list[::-1])):
self.lstm_node_list[backward_node_index].backward()
"""
最后一个LSTM细胞的梯度不涉及到基于时间序列的链式法则求解梯度
"""
if backward_node_index == 0:
gradients_wf = self.lstm_node_list[backward_node_index].gradients['wf']
gradients_wi = self.lstm_node_list[backward_node_index].gradients['wi']
gradients_wc = self.lstm_node_list[backward_node_index].gradients['wc']
gradients_wo = self.lstm_node_list[backward_node_index].gradients['wo']
gradients_bf = self.lstm_node_list[backward_node_index].gradients['bf']
gradients_bi = self.lstm_node_list[backward_node_index].gradients['bi']
gradients_bc = self.lstm_node_list[backward_node_index].gradients['bc']
gradients_bo = self.lstm_node_list[backward_node_index].gradients['bo']
gradients_h = self.lstm_node_list[backward_node_index].gradients['h_prev']
gradients_x = self.lstm_node_list[backward_node_index].gradients['x']
else:
"""
基于时间的梯度计算法则计算梯度(BPTT,其实就是链式法则)
"""
h_grdient_index = 1
while h_grdient_index != backward_node_index:
"""
#0,1,2,...i-1 各LSTM细胞之间的h梯度相乘,按照先后顺序有不同数量的h梯度因数
"""
gradients_h *= self.lstm_node_list[h_grdient_index].gradients['h_prev']
h_grdient_index += 1
"""
梯度相加原则
#0,1,2,3,....i 所有节点的梯度相加
"""
gradients_wf += np.dot(self.lstm_node_list[backward_node_index].gradients['wf'], gradients_h)
gradients_wi += np.dot(self.lstm_node_list[backward_node_index].gradients['wi'], gradients_h)
gradients_wc += np.dot(self.lstm_node_list[backward_node_index].gradients['wc'], gradients_h)
gradients_wo += np.dot(self.lstm_node_list[backward_node_index].gradients['wo'], gradients_h)
gradients_bf += np.dot(self.lstm_node_list[backward_node_index].gradients['bf'], gradients_h)
gradients_bi += np.dot(self.lstm_node_list[backward_node_index].gradients['bi'], gradients_h)
gradients_bc += np.dot(self.lstm_node_list[backward_node_index].gradients['bc'], gradients_h)
gradients_bo += np.dot(self.lstm_node_list[backward_node_index].gradients['bo'], gradients_h)
gradients_x += np.dot(self.lstm_node_list[backward_node_index].gradients['x'], gradients_h)
gradients_bf = gradients_bf.squeeze()
gradients_bi = gradients_bi.squeeze()
gradients_bc = gradients_bc.squeeze()
gradients_bo = gradients_bo.squeeze()
for n in self.outputs:
gradients_from_loss_to_self = n.gradients[self]
gradients_from_loss_to_self = np.mean(gradients_from_loss_to_self, axis=0, keepdims=False)
"""
对于输入x的梯度计算需保留所有LSTM细胞的梯度计算,为LSTM的输入节点的梯度计算做准备。
"""
self.gradients[self.input_x] += np.dot(gradients_from_loss_to_self,gradients_x.T)
"""
#取一个batch的平均值和所有node的平均值
"""
gradients_from_loss_to_self = np.mean(gradients_from_loss_to_self, axis=0, keepdims=True)
self.gradients[self.wf] += gradients_from_loss_to_self*gradients_wf
self.gradients[self.wi] += gradients_from_loss_to_self*gradients_wi
self.gradients[self.wc] += gradients_from_loss_to_self*gradients_wc
self.gradients[self.wo] += gradients_from_loss_to_self*gradients_wo
self.gradients[self.bf] += gradients_from_loss_to_self*gradients_bf
self.gradients[self.bi] += gradients_from_loss_to_self*gradients_bi
self.gradients[self.bc] += gradients_from_loss_to_self*gradients_bc
self.gradients[self.bo] += gradients_from_loss_to_self*gradients_bo
3.使用搭建的LSTM运用解决时间序列回归问题。
实现代码如下:
from sklearn.datasets import load_boston
from tqdm import tqdm
from sklearn.utils import shuffle, resample
import numpy as np
from xhp_flow.nn.node import Placeholder,Linear,Sigmoid,ReLu,Leakrelu,Elu,Tanh,LSTM
from xhp_flow.optimize.optimize import toplogical_sort,run_steps,optimize,forward,save_model,load_model
from xhp_flow.loss.loss import MSE,EntropyCrossLossWithSoftmax
import matplotlib.pyplot as plt
import torch
from glob import glob
from data_prepare_for_many import *
torch.manual_seed(1)
MAX_LENGTH = 100
torch.cuda.set_device(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
print('ok')
length = 10
predict_length = 1
batch_size = 512
file_path_train = np.array(glob('data/train/*'))
# file_path_test = np.array(glob('data/test/*'))
# file_path_valid = np.array(glob('data/valid/*'))
# Training_generator1, Test, Valid, WholeSet= get_dataloader(batch_size,length,predict_length)
Training_generator, WholeSet_train = get_dataloader(batch_size, length, predict_length, file_path_train, 'train')
x1, y = next(iter(Training_generator))
input_x, y = x1.numpy(), y.numpy()
class LSTMtest():
def __init__(self, input_size=8, hidden_size=256, output_size=1):
self.x, self.y = Placeholder(name='x', is_trainable=False), Placeholder(name='y', is_trainable=False)
self.wf, self.bf = Placeholder(name='wf'), Placeholder(name='bf')
self.wi, self.bi = Placeholder(name='wi'), Placeholder(name='bi')
self.wc, self.bc = Placeholder(name='wc'), Placeholder(name='bc')
self.wo, self.bo = Placeholder(name='wo'), Placeholder(name='bo')
self.w0, self.b0 = Placeholder(name='w0'), Placeholder(name='b0')
self.w1, self.b1 = Placeholder(name='w1'), Placeholder(name='b1')
self.w2, self.b2 = Placeholder(name='w2'), Placeholder(name='b2')
self.linear0 = Linear(self.x, self.w0, self.b0, name='linear0')
self.lstm = LSTM(self.linear0, self.wf, self.wi, self.wc, self.wo, self.bf, self.bi, self.bc, self.bo,
input_size, hidden_size, name='LSTM')
self.linear1 = Linear(self.lstm, self.w1, self.b1, name='linear1')
self.output = ReLu(self.linear1, name='Elu')
self.y_pre = Linear(self.output, self.w2, self.b2, name='output_pre')
self.MSE_loss = MSE(self.y_pre, self.y, name='MSE')
# 初始化数据结构
self.feed_dict = {
self.x: input_x,
self.y: y,
self.w0: np.random.rand(input_x.shape[2], input_size),
self.b0: np.zeros(input_size),
self.wf: np.random.rand(input_size + hidden_size, hidden_size),
self.bf: np.zeros(hidden_size),
self.wi: np.random.rand(input_size + hidden_size, hidden_size),
self.bi: np.zeros(hidden_size),
self.wc: np.random.rand(input_size + hidden_size, hidden_size),
self.bc: np.zeros(hidden_size),
self.wo: np.random.rand(input_size + hidden_size, hidden_size),
self.bo: np.zeros(hidden_size),
self.w1: np.random.rand(hidden_size, hidden_size),
self.b1: np.zeros(hidden_size),
self.w2: np.random.rand(hidden_size, output_size),
self.b2: np.zeros(output_size),
}
# In[ ]:
lstm = LSTMtest(16, 16, 1)
graph_sort_lstm = toplogical_sort(lstm.feed_dict) # 拓扑排序
print(graph_sort_lstm)
def train(model, train_data, epoch=6, learning_rate=1e-3):
# 开始训练
losses = []
loss_min = np.inf
for e in range(epoch):
for X, Y in train_data:
X, Y = X.numpy(), Y.numpy()
model.x.value = X
model.y.value = Y
run_steps(graph_sort_lstm)
# if model.y_pre.value is not None:
# print(model.y_pre.value.shape,Y.shape)
optimize(graph_sort_lstm, learning_rate=learning_rate)
loss = model.MSE_loss.value
losses.append(loss)
# print('loss:',loss)
print("epoch:{}/{},loss:{:.6f}".format(e,epoch,np.mean(losses)))
if np.mean(losses) < loss_min:
print('loss is {:.6f}, is decreasing!! save moddel'.format(np.mean(losses)))
save_model("model/lstm.xhp", model)
loss_min = np.mean(losses)
print('min loss:',loss_min)
plt.plot(losses)
plt.savefig("image/lstm_loss.png")
plt.show()
train(lstm, Training_generator, 1000)
最后得到的最小损失为5.9795,训练过程如下:
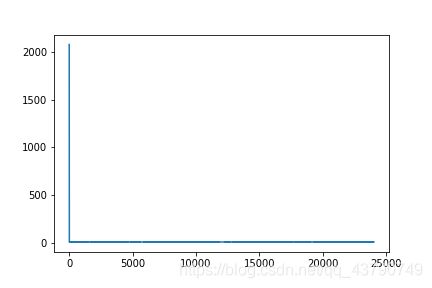
4.使用pytorch搭建网络解决同样的问题
代码如下:
import torch
from torch import nn
class lstmtest(nn.Module):
def __init__(self, input_size,hidden_size,output_size,dropout=0):
super(lstmtest, self).__init__()
self.hidden_size = hidden_size
self.num_layers = 1
self.in2lstm = nn.Linear(input_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers=self.num_layers, bidirectional=False, batch_first=False,
dropout=dropout)
self.fc0 = nn.Linear(hidden_size, hidden_size)
self.relu = nn.ReLU()
nn.LogSoftmax()
self.fc1 = nn.Linear(hidden_size, output_size)
def forward(self, input):
out1 = self.in2lstm(input)
lstm,_ = self.lstm(out1)
out1 = self.fc0(lstm)
out1 = self.relu(out1)
output = self.fc1(out1)
return output
from data_prepare_for_many import *
torch.manual_seed(1)
MAX_LENGTH = 100
torch.cuda.set_device(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
print('ok')
length = 10
predict_length = 1
batch_size = 512
file_path_train = np.array(glob('data/train/*'))
#file_path_test = np.array(glob('data/test/*'))
#file_path_valid = np.array(glob('data/valid/*'))
# Training_generator1, Test, Valid, WholeSet= get_dataloader(batch_size,length,predict_length)
Training_generator, WholeSet_train = get_dataloader(batch_size, length, predict_length, file_path_train, 'train')
lstm = lstmtest(7,16,1)
lstm = lstm.double()
encoder_optimizer = torch.optim.Adam(lstm.parameters(), lr=1e-3)
def train(model,train_data,epoch = 1000,learning_rate = 1e-3):
#开始训练
losses = []
criterion = nn.MSELoss()
loss_min = np.inf
for e in range(epoch):
for X,Y in train_data:
y = model(X)
loss = criterion(y, Y)
loss.backward()
encoder_optimizer.step()
losses.append(loss.item())
if np.mean(losses) < loss_min:
print('loss is {:.6f}, is decreasing!! save moddel'.format(np.mean(losses)))
torch.save(model.state_dict(),'model/torch_lstm_test.pth')
loss_min = np.mean(losses)
print("epoch:{},loss:{}".format(e, np.mean(losses)))
print('min loss:',loss_min)
plt.plot(losses)
plt.savefig("image/torch_lstm_loss.png")
plt.show()
train(lstm,Training_generator,1000)
最小损失为3.58.
训练过程如下: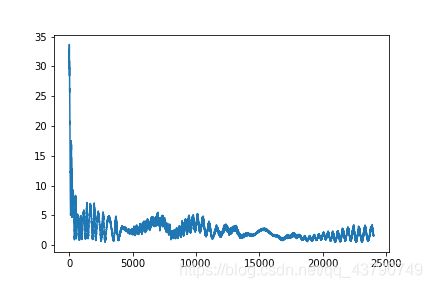
相比pytorch,自己搭建的网络还是有差距。主要是:
1.没有实现Adam优化算法。
2.没有对初始参数做最优设计。
3.还有原因还待分析解决。