NNDL 实验四 线性分类 基于Logistic回归的二分类任务、基于Softmax回归的多分类任务和基于Softmax回归完成鸢尾花分类任务
pytorch实现
第3章 线性分类
3.1 基于Logistic回归的二分类任务
使用到的第三方库
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
import torch.nn as nn
import torch.optim as optim
import torch
import numpy as np
import random
3.1.1 数据集构建
构建一个简单的分类任务,并构建训练集、验证集和测试集。
本任务的数据来自带噪音的两个弯月形状函数,每个弯月对一个类别。我们采集1000条样本,每个样本包含2个特征。
随机采集1000个样本,并进行可视化。
将1000条样本数据拆分成训练集、验证集和测试集,其中训练集640条、验证集160条、测试集200条。
def get_moon_data():
X, y = make_moons(1000, noise=0.1)
'''plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()'''
X=torch.from_numpy(X.astype(np.float32))
y=torch.from_numpy(y.astype(np.float32)).reshape(len(y),1)#修改成需要的形状
'''将1000条样本数据拆分成训练集、验证集和测试集,其中训练集640条、验证集160条、测试集200条。'''
train_X,vertify_X,test_X=torch.split(X,[640,160,200])
train_y, vertify_y, test_y = torch.split(y, [640, 160, 200])
return [train_X,train_y],[vertify_X,vertify_y],[test_X,test_y]

3.1.2 模型构建
在本次实验中,我们想得到一个模型,使得输入一个坐标,输出0或1来判断他属于哪一类。因此设计一个输入层为2,隐含层数为3,输出层为1的神经网络,激活函数为sigmoid函数。
class LogisticRegression(nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__()
self.linear = nn.Linear(2, 3)
self.hide=nn.Linear(3,1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x1 = self.linear(x)
x2=self.hide(x1)
pre_y = self.sigmoid(x2)
return pre_y
问题1:Logistic回归在不同的书籍中,有许多其他的称呼,具体有哪些?你认为哪个称呼最好?
逻辑函数;逻辑斯蒂函数;物流函数;逻辑斯特函数等等
我觉得就记住英文logistic函数就挺好的,非要比较来说逻辑斯蒂和逻辑斯特更接近英文发音,这两个更好些。
问题2:什么是激活函数?为什么要用激活函数?常见激活函数有哪些?
Logistic函数的图像
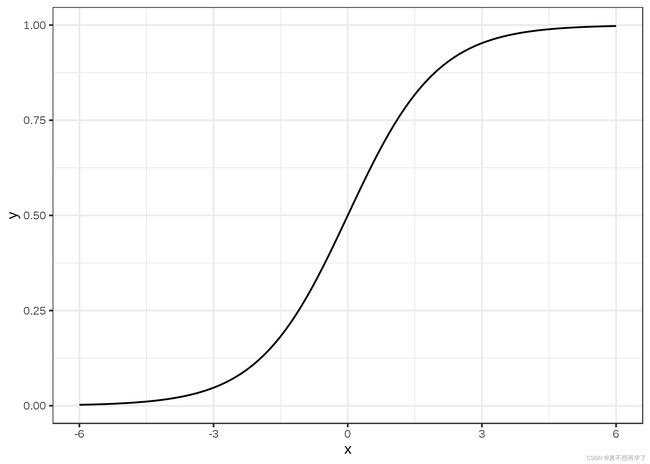
我们可以发现logistic函数就是我们知道的sigmoid函数。它的特点是当数据趋于无穷时,因变量趋于1,输入趋于负无穷时,因变量趋于0。可见logistic函数将输入x压缩到了0到1之间,我们知道,事件的概率也可以用0到1之间的数字表示,从这一点来说,二者之间建立了联系。softmax就是利用这一点来进行最后的判定分类的。
为什么要用激活函数?
假如没有激活函数:
输入层为x,输出层为y
那么y=wx+b
如果加一层隐函数
h1,h2
h1=w1x+b1
h2=w2x+b2
y=w(h1+h2)=w(w1x+b1+w2x+b2)+b=(ww1+ww2)x+wb1+wb2+b
我们发现最后还是相当于y=wx+b,也就是说最后的结果仍然是个线性模型。而激活函数实际上是将线性输入转换为非线性的输出,可以去除模型的线性,从而解决非线性问题。
常见的激活函数还有sigmoid函数
f ( z ) = 1 1 + e − z f \left ( z \right )= \frac{1}{1+e^{-z}} f(z)=1+e−z1
Tanh / 双曲正切激活函数
f ( x ) = 2 1 + e − 2 x − 1 f\left ( x \right )=\frac{2}{1+e^{-2x}}-1 f(x)=1+e−2x2−1
ReLU 激活函数
σ ( x ) = { m a x ( 0 , x ) , x > = 0 0 , x < 0 \sigma \left ( x \right )= \left\{\begin{matrix} max\left ( 0,x \right ),x>=0 & & \\ 0,x<0& & \end{matrix}\right. σ(x)={max(0,x),x>=00,x<0
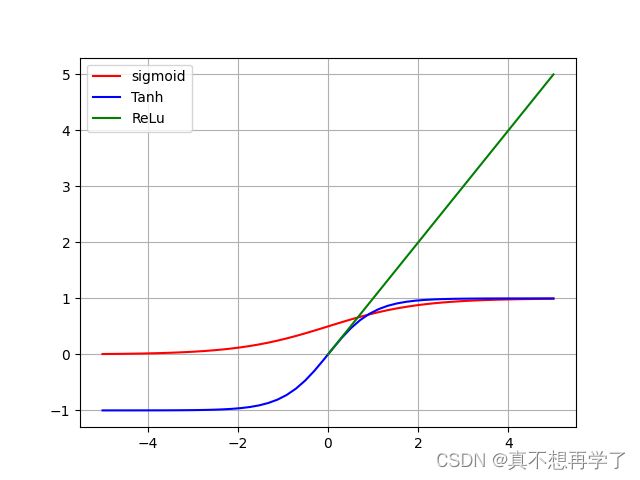
其他种类的激活函数也有这几种的变用,都是类似的,针对于处理不同的问题,这里不再赘述。
3.1.3 损失函数
交叉熵损失函数
l o s s = − ∑ i = 0 n y i l o g ( y i ′ ) loss=-\sum_{i=0}^{n}y_{i}log\left ( y_{i}'\right ) loss=−i=0∑nyilog(yi′)
在信息论中,用交叉熵来衡量两个概率分布之间的距离,在交叉熵损失函数中,yi与yi’分别代表实际值与预测值,所以他代表的是预测值与实际值之间的距离,可以代表分类效果的好坏。其值越小越好。
loss = nn.BCELoss()
3.1.4 模型优化
不同于线性回归中直接使用最小二乘法即可进行模型参数的求解,Logistic回归需要使用优化算法对模型参数进行有限次地迭代来获取更优的模型,从而尽可能地降低风险函数的值。
在机器学习任务中,最简单、常用的优化算法是梯度下降法。
使用梯度下降法进行模型优化,首先需要初始化参数W和 b,然后不断地计算它们的梯度,并沿梯度的反方向更新参数。
换句话说就是类似于反向传播法,每次迭代都更新一次参数w和b,更新方向由梯度下降方向决定。
optimizer = optim.SGD(net.parameters(), lr=0.01)
3.1.5 评价指标
在分类任务中,通常使用准确率(Accuracy)作为评价指标。
a c c = 正确数 总数 ∗ 100 % acc=\frac{\text正确数}{\text总数}*100\% acc=总数正确数∗100%
在进行多次迭代后,模型的输出也不一定全是0或1,因此我们取临界值0.5,大于这个值的都记为1,小于的都记为0,再进行判断。
在这里已经尽量避免用循环方法了,但是实在是找不到更好的办法,以后找到了可能会修改。
def acc(model, X, y):
ct=0
for i in range(len(y)):
pre_y = model(X[i])
if pre_y>=0.5:
pre_y=1
else:pre_y=0
if pre_y==y[i]:
ct+=1
return ct/y.shape[0]
3.1.6 完善Runner类
基于RunnerV1,本章的RunnerV2类在训练过程中使用梯度下降法进行网络优化,模型训练过程中计算在训练集和验证集上的损失及评估指标并打印,训练过程中保存最优模型。
# coding:utf-8
import torch
import torch.nn as nn
from torch import optim
import random
class Runner():
def __init__(self,model,loss,optim,eval_loss):
'''传入模型、损失函数、优化器和评价指标'''
self.model=model
self.loss=loss
self.optim=optim
self.eval_loss=eval_loss
def LosgisticCliassify_train(self,X,y,epoches):
for i in range(epoches):
loss = nn.BCELoss()
optimizer = optim.SGD(self.model.parameters(), lr=0.01, momentum=0.9)
pre_y = self.model(X)
l = loss(pre_y, y)
optimizer.zero_grad() # 梯度清零
l.backward()
optimizer.step()
if i % 50 == 0:
print('epoch %d, loss: %f' % (i, l.item()))
def LSM_train(self,train_data,epoches):
'''train_data:列表类型,两个元素为tensor类型,第一个是x,第二个是y'''
model=self.model
loss = torch.nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-3)
X = train_data[0]
y = train_data[1]
num_epochs = epoches
for epoch in range(num_epochs):
pre_y = model(X)
l = loss(pre_y, y)
optimizer.zero_grad() # 梯度清零
l.backward()
optimizer.step()
print('epoch %d, loss: %f' % (epoch, l.item()))
self.__save_model(model)
def LSM_evaluate(self,test_data):
'''测试模型
test_data:列表类型,两个元素为tensor类型,第一个是x,第二个是y'''
x = test_data[0]
y = test_data[1]
l = self.loss(self.model(x), y)
print('测试集loss:', l.item())
def predict(self,X):
'''预测数据'''
return self.model(X)
def save_model(self, save_path):
''''.pt'文件'''
torch.save(self, save_path)
def read_model(self, path):
''''.pt'文件'''
torch.load(path)
def LogisticClassify_acc(self, X, y):
ct = 0
for i in range(len(y)):
pre_y = self.model(X[i])
if pre_y >= 0.5:
pre_y = 1
else:
pre_y = 0
if pre_y == y[i]:
ct += 1
return ct / y.shape[0]
3.1.7 模型训练
Logistic回归模型的训练,使用交叉熵损失函数和梯度下降法进行优化。
使用训练集和验证集进行模型训练,共训练 500个epoch,每隔50个epoch打印出训练集上的指标。
if __name__ == '__main__':
net = LogisticRegression()
train_data, verify_data, test_data=get_moon_data()
X=train_data[0];y=train_data[1]
epoches=300
for i in range(epoches):
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
pre_y = net(X)
l = loss(pre_y, y)
optimizer.zero_grad() # 梯度清零
l.backward()
optimizer.step()
if i%50==0:
print('epoch %d, loss: %f' % (i, l.item()))
net.save_model('lNet.pt')
print('Current acc in verify data:',acc(net,verify_data[0],verify_data[1])*100,'%')
print('acc in test data :',acc(net,test_data[0],test_data[1])*100,'%')
epoch 0, loss: 0.818943
Current acc in verify data: 45.625 %
epoch 50, loss: 0.748746
Current acc in verify data: 45.625 %
epoch 100, loss: 0.701320
Current acc in verify data: 45.625 %
epoch 150, loss: 0.665143
Current acc in verify data: 45.625 %
epoch 200, loss: 0.634816
Current acc in verify data: 73.75 %
epoch 250, loss: 0.607729
Current acc in verify data: 78.75 %
epoch 300, loss: 0.582630
Current acc in verify data: 77.5 %
epoch 350, loss: 0.558943
Current acc in verify data: 80.625 %
epoch 400, loss: 0.536438
Current acc in verify data: 80.625 %
epoch 450, loss: 0.515067
Current acc in verify data: 80.625 %
acc in test data : 80.5 %
3.1.8 模型评价
使用测试集对训练完成后的最终模型进行评价,观察模型在测试集上的准确率和loss数据。
print(acc(net,test_data[0],test_data[1]))
3.2 基于Softmax回归的多分类任务
Logistic回归可以有效地解决二分类问题。
但在分类任务中,还有一类多分类问题,即类别数C大于2 的分类问题。
Softmax回归就是Logistic回归在多分类问题上的推广。
3.2.1 数据集构建
数据来自3个不同的簇,每个簇对一个类别。我们采集1000条样本,每个样本包含2个特征。
def normal_circle(x,y,num,sigma):
'''指定中心位置随机生成若干个正态分布的点'''
X=[]
for i in range(num):
while True:
x1=random.normalvariate(x,sigma)
x2=random.normalvariate(y,sigma)
if [x1,x2] not in X:
X.append([x1,x2])
break
return np.array(X)
def get_data():
'''数据来自3个不同的簇,每个簇对一个类别。我们采集1000条样本,每个样本包含2个特征。333,333,334
返回数据集包括特征X和标签y'''
X1 = torch.from_numpy(normal_circle(1, 1, 333, 0.1).astype(np.float32))
X2 = torch.from_numpy(normal_circle(1.25, 1.5, 333, 0.1).astype(np.float32))
X3 = torch.from_numpy(normal_circle(1.5, 1, 334, 0.1).astype(np.float32))
y1=torch.from_numpy(np.array([0,0,0]*333).astype(np.float32))
y2=torch.from_numpy(np.array([0,1,0]*333).astype(np.float32))
y3=torch.from_numpy(np.array([0,0,1]*334).astype(np.float32))
return torch.cat([torch.cat([X1,X2],dim=0),X3],dim=0),torch.cat([torch.cat([y1,y2],dim=0),y3],dim=0).reshape(1000,3)

3.2.2 模型构建
按照实验要求,创建输入层为2 ,隐含层为4,输出层为3,激活函数为softmax的神经网络。
class SoftMaxClassification(nn.Module):
def __init__(self):
super(SoftMaxClassification, self).__init__()
self.linear = nn.Linear(2, 4)
self.hide=nn.Linear(4,3)
self.softmax = nn.Softmax(dim=1)
'''不加dim=1会报错,意思是torch.softmax()已经被弃用
UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.'''
def forward(self, x):
x1 = self.linear(x)
x2=self.hide(x1)
pre_y = self.softmax(x2)
return pre_y
def save_model(self, save_path):
torch.save(self, save_path)
def read_model(self, path):
torch.load(path)
思考题:Logistic函数是激活函数。Softmax函数是激活函数么?谈谈你的看法。
Softmax函数
f ( x ) = e x i ∑ j = 0 n e x j , i = 0 , 1 , . . . , n f\left(x\right)=\frac{e^{xi}}{\sum_{j=0}^{n}e^{xj}} , i=0,1,...,n f(x)=∑j=0nexjexi,i=0,1,...,n
softmax将输入数据转化为指数分布,再将指数分布归一化处理,令输出近似成为输入的概率分布,且概率和为1。softmax函数将输入归一成[p1,p2,p3,…pn]。而sigmoid函数将输入约束到0~1之间,而且而二分类问题中我们只取[0,1]这两个值,那么我们也可以认为输出了两个概率,且概率为0或1,可以认为输出的概率和也为1。从这一观点来看,二者有很大的相似性,那么既然sigmoid函数是激活函数,softmax也是一种激活函数。
3.2.3 损失函数
softmax同样使用交叉熵函数作为损失函数。
loss = nn.BCELoss()
3.2.4 模型优化
使用3.1.4.2中实现的梯度下降法进行参数更新
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
3.2.5 模型训练
实例化RunnerV2类,并传入训练配置。使用训练集和验证集进行模型训练,共训练500个epoch。每隔50个epoch打印训练集上的指标。
if __name__ == '__main__':
net = SoftMaxClassification()
X,y=get_data()
print(X,y)
epoches=300
for i in range(epoches):
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
pre_y = net(X)
l = loss(pre_y, y)
optimizer.zero_grad() # 梯度清零
l.backward()
optimizer.step()
if i%50==0:
print('epoch %d, loss: %f' % (i, l.item()))
net.save_model('SNet.pt')
epoch 0, loss: 0.630300
epoch 50, loss: 0.470632
epoch 100, loss: 0.453022
epoch 150, loss: 0.438994
epoch 200, loss: 0.420810
epoch 250, loss: 0.393069
acc of train data: 66.4 %
3.2.6 模型评价
使用测试集对训练完成后的最终模型进行评价,观察模型在测试集上的准确率。
def acc(model, X, y):
'''返回正确率'''
pre_y=model(X)
max_pre_y=torch.argmax(pre_y,dim=1)
max_y=torch.argmax(y,dim=1)
return torch.nonzero(max_y.eq(max_pre_y)).shape[0]/y.shape[0]
3.3 实践:基于Softmax回归完成鸢尾花分类任务
步骤:数据处理、模型构建、损失函数定义、优化器构建、模型训练、模型评价和模型预测等,
使用到的库
from Runner import *
import pandas as pd
import numpy as np
数据处理:根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取;
def init_Iris():
df = pd.read_csv('Iris.csv')
data_array = df.to_numpy()
X = data_array[:, :-1]
labels = data_array[:, -1]
lenth = [0, 0, 0]
for i in range(len(labels)):
if labels[i] == 1:
lenth[0] += 1
elif labels[i] == 2:
lenth[1] += 1
elif labels[i] == 3:
lenth[2] += 1
y = np.array([[1, 0, 0] * lenth[0], [0, 1, 0] * lenth[1], [0, 0, 1] * lenth[2]]).reshape(len(labels), 3)
X = torch.from_numpy(X.astype(np.float32))
y = torch.from_numpy(y.astype(np.float32))
return X,y
模型构建:定义Softmax回归模型类;
水仙花数据集包括四个特征,一个标签,而为了适应模型,我们将标签由一维转化成三维的。据此建立一个输入层为4,隐含层为6,输出层为3,激活函数为softmax的神经网络。
class Irismodel(nn.Module):
def __init__(self):
super(Irismodel, self).__init__()
self.linear = nn.Linear(4, 6)
self.hide=nn.Linear(6,3)
self.softmax = nn.Softmax(dim=1)
'''不加dim=1会报错,意思是torch.softmax()已经被弃用
UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.'''
def forward(self, x):
x1 = self.linear(x)
x2=self.hide(x1)
pre_y = self.softmax(x2)
return pre_y
def save_model(self, save_path):
torch.save(self, save_path)
def read_model(self, path):
torch.load(path)
训练配置:训练相关的一些配置,如:优化算法、评价指标等;
这个和之前的保持一致
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
组装Runner类:Runner用于管理模型训练和测试过程;
# coding:utf-8
import torch
import torch.nn as nn
from torch import optim
class Runner():
def __init__(self,model,loss,optim):
'''传入模型、损失函数、优化器,
评价指标作为类方法可实例化调用'''
self.model=model
self.loss=loss
self.optim=optim
def SoftmaxClassify_train(self,X,y):
print('start training....')
epoches = 300
for i in range(epoches):
loss = nn.BCELoss()
optimizer = optim.SGD(self.model.parameters(), lr=0.1, momentum=0.9)
pre_y = self.model(X)
l = loss(pre_y, y)
optimizer.zero_grad() # 梯度清零
l.backward()
optimizer.step()
if i % 50 == 0:
print('epoch %d, loss: %f' % (i, l.item()))
print('training ended.')
def LosgisticCliassify_train(self,X,y,epoches):
print('start training....')
for i in range(epoches):
loss = nn.BCELoss()
optimizer = optim.SGD(self.model.parameters(), lr=0.01, momentum=0.9)
pre_y = self.model(X)
l = loss(pre_y, y)
optimizer.zero_grad() # 梯度清零
l.backward()
optimizer.step()
if i % 50 == 0:
print('epoch %d, loss: %f' % (i, l.item()))
print('training ended.')
def LSM_train(self,train_data,epoches):
'''train_data:列表类型,两个元素为tensor类型,第一个是x,第二个是y'''
print('start training....')
model=self.model
loss = torch.nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-3)
X = train_data[0]
y = train_data[1]
num_epochs = epoches
for epoch in range(num_epochs):
pre_y = model(X)
l = loss(pre_y, y)
optimizer.zero_grad() # 梯度清零
l.backward()
optimizer.step()
print('epoch %d, loss: %f' % (epoch, l.item()))
print('training ended.')
def LSM_evaluate(self,test_data):
'''测试模型
test_data:列表类型,两个元素为tensor类型,第一个是x,第二个是y'''
x = test_data[0]
y = test_data[1]
l = self.loss(self.model(x), y)
print('loss in test data:', l.item())
def predict(self,X):
'''预测数据'''
return self.model(X)
def save_model(self, save_path):
''''.pt'文件'''
torch.save(self, save_path)
def read_model(self, path):
''''.pt'文件'''
torch.load(path)
def LogisticClassify_acc(self, X, y):
'''最大项的为预测的类别'''
ct = 0
for i in range(len(y)):
pre_y = self.model(X[i])
if pre_y >= 0.5:
pre_y = 1
else:
pre_y = 0
if pre_y == y[i]:
ct += 1
return ct / y.shape[0]
def SoftmaxClassify_acc(self, X, y):
pre_y = self.model(X)
max_pre_y = torch.argmax(pre_y, dim=1)
max_y = torch.argmax(y, dim=1)
return torch.nonzero(max_y.eq(max_pre_y)).shape[0] / y.shape[0]
模型训练和测试:利用Runner进行模型训练、评价和测试。
(说明:使用深度学习进行实践时的操作流程基本一致,后文不再赘述。)
if __name__ == '__main__':
net = Irismodel()
X,y=init_Iris()
epoches=300
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
runner=Runner(net,loss=loss,optim=optimizer)
runner.SoftmaxClassify_train(X,y,epoches)
runner.save_model('Irismodel.pt')
runner.SoftmaxClassify_acc(X,y)
print('acc of train data:',runner.SoftmaxClassify_acc(X,y)*100,'%')
start training…
epoch 0, loss: 0.926990
epoch 50, loss: 0.334160
epoch 100, loss: 0.215052
epoch 150, loss: 0.145577
epoch 200, loss: 0.171034
epoch 250, loss: 0.095275
training ended.
acc of train data: 97.33333333333334 %
主要配置:
数据:Iris数据集;
模型:Softmax回归模型;
损失函数:交叉熵损失;
优化器:梯度下降法;
评价指标:准确率。
为了加深对机器学习模型的理解,请自己动手完成以下实验:
尝试调整学习率和训练轮数等超参数,观察是否能够得到更高的精度;(必须完成)
以训练Iris数据集为例
首先固定训练epoches=50,改变lr
if __name__ == '__main__':
for lr in [10,1,0.1,0.01,0.001]:
print('##############lr={}##########'.format(lr))
net = Irismodel()
X,y=init_Iris()
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr, momentum=0.9)
runner=Runner(net,loss=loss,optim=optimizer)
runner.SoftmaxClassify_train(X,y,epoches=50)
runner.save_model('Irismodel.pt')
print('acc of train data:',runner.SoftmaxClassify_acc(X,y)*100,'%')
##############lr=10##########
start training…
epoch 0, loss: 1.113797
training ended.
acc of train data: 72.0 %
##############lr=1##########
start training…
epoch 0, loss: 1.246632
training ended.
acc of train data: 84.0 %
##############lr=0.1##########
start training…
epoch 0, loss: 0.609572
training ended.
acc of train data: 90.0 %
##############lr=0.01##########
start training…
epoch 0, loss: 0.830052
training ended.
acc of train data: 80.66666666666666 %
##############lr=0.001##########
start training…
epoch 0, loss: 1.486146
training ended.
acc of train data: 70.0 %
然后固定lr=0.01,改变epoches
if __name__ == '__main__':
for epoches in [1,10,50,100,300]:
print('#################epoches={}##########'.format(epoches))
net = Irismodel()
X,y=init_Iris()
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
runner=Runner(net,loss=loss,optim=optimizer)
runner.SoftmaxClassify_train(X,y,epoches)
runner.save_model('Irismodel.pt')
print('acc of train data:',runner.SoftmaxClassify_acc(X,y)*100,'%')
#################epoches=1##########
start training…
epoch 0, loss: 0.660881
training ended.
acc of train data: 33.33333333333333 %
#################epoches=10##########
start training…
epoch 0, loss: 0.697144
training ended.
acc of train data: 66.66666666666666 %
#################epoches=50##########
start training…
epoch 0, loss: 0.666411
training ended.
acc of train data: 86.66666666666667 %
#################epoches=100##########
start training…
epoch 0, loss: 1.068868
epoch 50, loss: 0.342197
training ended.
acc of train data: 95.33333333333334 %
#################epoches=300##########
start training…
epoch 0, loss: 1.192703
epoch 50, loss: 0.293516
epoch 100, loss: 0.187842
epoch 150, loss: 0.130309
epoch 200, loss: 0.100085
epoch 250, loss: 0.103519
training ended.
acc of train data: 98.0 %
发现训练轮数越多,模型训练准确率越高,当训练轮数一定时,学习率却不是越高越好,也不是越低越好。过低时训练速度太慢,轮数不够时不容易达到最优值,而过高时容易出现跳过最优解的情况,也达不到最优解。
在解决多分类问题时,还有一个思路是将每个类别的求解问题拆分成一个二分类任务,通过判断是否属于该类别来判断最终结果。请分别尝试两种求解思路,观察哪种能够取得更好的结果;(选做)
有两种思路:
1.分成三次二分类,取最大值?
2.分一次,如果不是,再分剩下两个?
还是以水仙花分类为例。
提供两种思路,只分析第一种。首先数据集的预处理就发生了变化,标签要把所要判断的类记为1,其他的所有都记为0。
def init_Iris():
df = pd.read_csv('Iris.csv')
data_array = df.to_numpy()
X = data_array[:, :-1]
labels = data_array[:, -1]
lenth = [0, 0, 0]
for i in range(len(labels)):
if labels[i] == 1:
lenth[0] += 1
elif labels[i] == 2:
lenth[1] += 1
elif labels[i] == 3:
lenth[2] += 1
y1 = np.array([[1]* lenth[0],[0] * lenth[1],[0] * lenth[2]]).reshape(len(labels), 1)
y2 = np.array([[0] * lenth[0], [1] * lenth[1], [0] * lenth[2]]).reshape(len(labels), 1)
y3 = np.array([[0] * lenth[0],[ 0] * lenth[1], [1] * lenth[2]]).reshape(len(labels), 1)
y = np.array([[1, 0, 0] * lenth[0], [0, 1, 0] * lenth[1], [0, 0, 1] * lenth[2]]).reshape(len(labels), 3)
X = torch.from_numpy(X.astype(np.float32))
y1 = torch.from_numpy(y1.astype(np.float32))
y2 = torch.from_numpy(y2.astype(np.float32))
y3 = torch.from_numpy(y3.astype(np.float32))
y= torch.from_numpy(y.astype(np.float32))
return X,y1,y2,y3,y
模型也发生一些改动:
class Logistic_Irismodel(nn.Module):
def __init__(self):
super(Logistic_Irismodel, self).__init__()
self.linear = nn.Linear(4, 6)
self.hide=nn.Linear(6,1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x1 = self.linear(x)
x2=self.hide(x1)
pre_y = self.sigmoid(x2)
return pre_y
def save_model(self, save_path):
torch.save(self, save_path)
def read_model(self, path):
torch.load(path)
主函数区:
随机输入[5.7,4.4,1.3,1.2],先试一下判断过程,然后再计算准确率。
if __name__ == '__main__':
X,y1,y2,y3=init_Iris()
test_x=torch.tensor(np.array([5.7,4.4,1.3,1.2]).astype(np.float32))
pre_y=[0,0,0]
for i,y in enumerate([y1,y2,y3]):
net = Logistic_Irismodel()
print('#######判断是否为第{}类###############'.format(i))
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
runner=Runner(net,loss=loss,optim=optimizer)
runner.LosgisticCliassify_train(X,y,epoches=300)
runner.save_model('Irismodel.pt')
print('acc of train data:',runner.LogisticClassify_acc(X,y)*100,'%')
print(runner.predict(test_x).item())
pre_y[i]+=runner.predict(test_x).item()
print('预测属于第{}类'.format(pre_y.index(max(pre_y))))
#######判断是否为第0类###############
start training…
epoch 0, loss: 0.911817
epoch 50, loss: 0.571656
epoch 100, loss: 0.463612
epoch 150, loss: 0.364378
epoch 200, loss: 0.275647
epoch 250, loss: 0.204969
training ended.
acc of train data: 100.0 %
0.8682891130447388
#######判断是否为第1类###############
start training…
epoch 0, loss: 0.735830
epoch 50, loss: 0.672121
epoch 100, loss: 0.647529
epoch 150, loss: 0.629978
epoch 200, loss: 0.616987
epoch 250, loss: 0.607266
training ended.
acc of train data: 66.66666666666666 %
0.21764957904815674
#######判断是否为第2类###############
start training…
epoch 0, loss: 0.752226
epoch 50, loss: 0.574329
epoch 100, loss: 0.501701
epoch 150, loss: 0.446914
epoch 200, loss: 0.405241
epoch 250, loss: 0.373096
training ended.
acc of train data: 97.33333333333334 %
0.04293675348162651
预测属于第0类
接下来全部测试:
if __name__ == '__main__':
X,y1,y2,y3,y=init_Iris()
max_y = torch.argmax(y, dim=1)
pre_y=torch.tensor([])
for i,y in enumerate([y1,y2,y3]):
net = Logistic_Irismodel()
print('#######判断是否为第{}类###############'.format(i))
loss = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
runner=Runner(net,loss=loss,optim=optimizer)
runner.LosgisticCliassify_train(X,y,epoches=300)
runner.save_model('Irismodel.pt')
print('acc of train data:',runner.LogisticClassify_acc(X,y)*100,'%')
pre_y = torch.cat([pre_y, runner.predict(X)],dim=1)
max_pre_y = torch.argmax(pre_y, dim=1)
print('acc of all train data:',torch.nonzero(max_y.eq(max_pre_y)).shape[0] / y.shape[0] * 100, '%')
#######判断是否为第0类###############
start training…
epoch 0, loss: 0.452272
epoch 50, loss: 0.318383
epoch 100, loss: 0.234283
epoch 150, loss: 0.172803
epoch 200, loss: 0.130368
epoch 250, loss: 0.101332
training ended.
acc of train data: 100.0 %
#######判断是否为第1类###############
start training…
epoch 0, loss: 0.657824
epoch 50, loss: 0.643840
epoch 100, loss: 0.633450
epoch 150, loss: 0.624940
epoch 200, loss: 0.617817
epoch 250, loss: 0.611801
training ended.
acc of train data: 66.66666666666666 %
#######判断是否为第2类###############
start training…
epoch 0, loss: 1.001562
epoch 50, loss: 0.613669
epoch 100, loss: 0.537713
epoch 150, loss: 0.474406
epoch 200, loss: 0.423824
epoch 250, loss: 0.384738
training ended.
acc of train data: 97.33333333333334 %
acc of all train data: 75.33333333333333 %
总结,可以发现epoches都等于300的情况下,softmax的分类准确率明显优于这种二分法。
参考softmax:
#################epoches=300##########
start training…
epoch 0, loss: 0.715637
epoch 50, loss: 0.319327
epoch 100, loss: 0.210033
epoch 150, loss: 0.200815
epoch 200, loss: 0.138273
epoch 250, loss: 0.102282
training ended.
acc of train data: 98.66666666666667 %
尝试使用《神经网络与深度学习》中的其他模型进行鸢尾花识别任务,观察是否能够得到更高的精度。(选做)
#coding:utf-8
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
'''绘制直方图以使得数据更直观'''
'''尝试自己编写SVM计算过程,发现极其困难,于是导入sklearn中的SVM'''
from sklearn import svm, datasets
from sklearn.inspection import DecisionBoundaryDisplay
'''图片显示中文'''
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def init_Iris():
df = pd.read_table('Iris.csv', encoding='gbk', names=['x1', 'x2', 'x3', 'x4', 'y'])
train_df = df.sample(frac=2 / 3, random_state=None, axis=0, replace=False)
'''print(train_df)'''
'''print(outcome_tree)'''
test_df = df.drop(index=train_df.index)
y = train_df['y'].tolist()
# print(y)
x1 = train_df['x1'].tolist()
x2 = train_df['x2'].tolist()
X = []
for i in range(len(x1)):
X.append([x1[i], x2[i]])
X=np.array(X)
t_y = test_df['y'].tolist()
# print(y)
t_x1 = test_df['x1'].tolist()
t_x2 = test_df['x2'].tolist()
t_X = []
for i in range(len(t_x1)):
t_X.append([t_x1[i], t_x2[i]])
t_X = np.array(t_X)
return X,y,t_X,t_y
def SVC(X,y,t_X,t_y):
C = 5 # SVM regularization parameter
models = (
svm.SVC(kernel="linear", C=C),
svm.LinearSVC(C=C, max_iter=100000),
svm.SVC(kernel="rbf", gamma=0.7, C=C),
svm.SVC(kernel="poly", degree=3, gamma="auto", C=C),
)
models = (clf.fit(X, y) for clf in models)
# title for the plots
titles = (
"SVC线性核",
"LinearSVC线性核 (迭代次数为100000)",
"SVC高斯核",
"SVC多项式核",
)
# Set-up 2x2 grid for plotting.
fig, sub = plt.subplots(2, 2)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
X0= X[:, 0]
X1= X[:, 1]
t_X0 = t_X[:, 0]
t_X1 = t_X[:, 1]
#分别用每个核函数进行训练
for clf, title, ax in zip(models, titles, sub.flatten()):
disp = DecisionBoundaryDisplay.from_estimator(#决策边界显示
clf,
X,
response_method="predict",
cmap=plt.cm.coolwarm,
alpha=0.8,
ax=ax,
xlabel='花萼宽度',
ylabel='花萼长度',
)
ax.scatter(X0, X1, c=y, cmap=plt.cm.coolwarm, s=20, edgecolors="k")
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(title)
print('----{}----'.format(title))
# 获取训练集的准确率
train_score = clf.score(X, y)
print("训练集:", train_score*100,'%')
# 获取验证集的准确率
test_score = clf.score(t_X, t_y)
print("测试集:", test_score*100,'%')
#plt.show()
def test_SVM(clf,df):
y = df['y'].tolist()
# print(y)
x1 = df['x1'].tolist()
x2 = df['x2'].tolist()
X = []
for i in range(len(x1)):
X.append([x1[i], x2[i]])
score=clf.score(X,y)
return score
if __name__=='__main__':
X, y, t_X, t_y=init_Iris()
SVC(X,y,t_X,t_y)
----SVC线性核----
训练集: 84.0 %
测试集: 80.0 %
----LinearSVC线性核 (迭代次数为100000)----
训练集: 79.0 %
测试集: 78.0 %
----SVC高斯核----
训练集: 83.0 %
测试集: 78.0 %
----SVC多项式核----
训练集: 83.0 %
测试集: 78.0 %
可见和函数方法也没有达到更好的分类效果。
总结:通过实验,我对torch的理解更深入了一层,并且掌握了很多相关知识,了解了不同模组之间的关系。通过亲手建立神经网络,对常见的分类问题的印象进一步加深了,同时对数据处理部分也有了更深的理解。掌握了更多torch中常用的函数,对torch中常用的函数的输入与输出进行了测试,运用更加灵活。尝试用二分类问题解决多分类问题的实践,让我对logistic分类与softmax分类的理解进一步加深。