李宏毅2021年机器学习作业3(CNN—classification)实验记录
李宏毅2021年机器学习作业2学习笔记
- 前言
- 一、问题描述
- 二、实验过程
-
- 2.1 跑助教提供的baseline
- 2.2 加入image-augmentation
- 2.3 修改数据增强部分
- 2.4 在2.3基础上,最后全连接层处理
- 2.5 半监督
- 三、总结
前言
声明:本文参考了李宏毅机器学习2021年作业例程,开发平台是kaggle notebook。
另一个CSDN大佬的博客
一、问题描述
实质是一个用CNN做多分类问题。
B站作业讲解视频
Kaggle地址
一个大佬的代码

二、实验过程
2.1 跑助教提供的baseline
操作:首先对dataloader部分代码进行修改,防止训练过程中爆内存。
# Construct data loaders.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=False)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=False)
初始CNN网络架构:
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# The arguments for commonly used modules:
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input image size: [3, 128, 128]
#假设输入图片尺寸为h,如果不加padding,输出的图片尺寸为h-k+1;(pytorch里左右填充,参数1相当于padding了2)
#加入padding,输出图片尺寸为h-k+p+1;
#如果加入stride,输出图片尺寸为(h-k+p+1)/s
#每次maxpooling相当于缩小n倍
self.cnn_layers = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1),#输出[64, 128-3+2+1, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0),#输出[64, (128-3+2+1)/2,64]
nn.Conv2d(64, 128, 3, 1, 1),#[128, 64,64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0),#[128,32,32]
nn.Conv2d(128, 256, 3, 1, 1),#[256,32,32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(4, 4, 0),#[256,8,8]
)
self.fc_layers = nn.Sequential(
nn.Linear(256 * 8 * 8, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 11)
)
def forward(self, x):
# input (x): [batch_size, 3, 128, 128]
# output: [batch_size, 11]
# Extract features by convolutional layers.
x = self.cnn_layers(x)
# The extracted feature map must be flatten before going to fully-connected layers.
x = x.flatten(1)
# The features are transformed by fully-connected layers to obtain the final logits.
x = self.fc_layers(x)
return x

发现有过拟合现象。
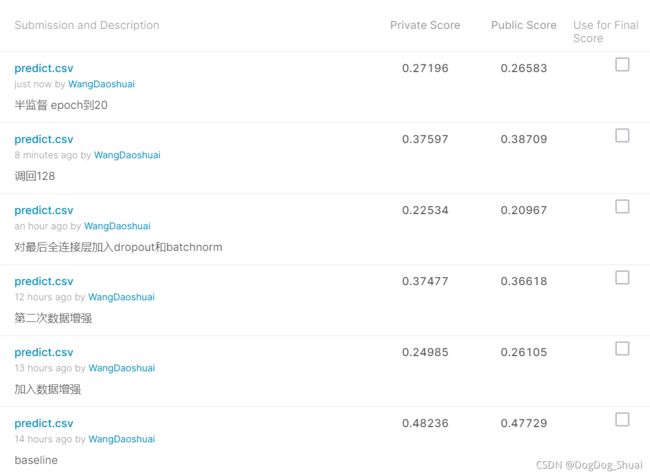
Kaggle得分: 0.47729
2.2 加入image-augmentation
操作:加入几个数据增强的方式,同时为了加快训练速度,batchsize(128->256)
 结果:
结果: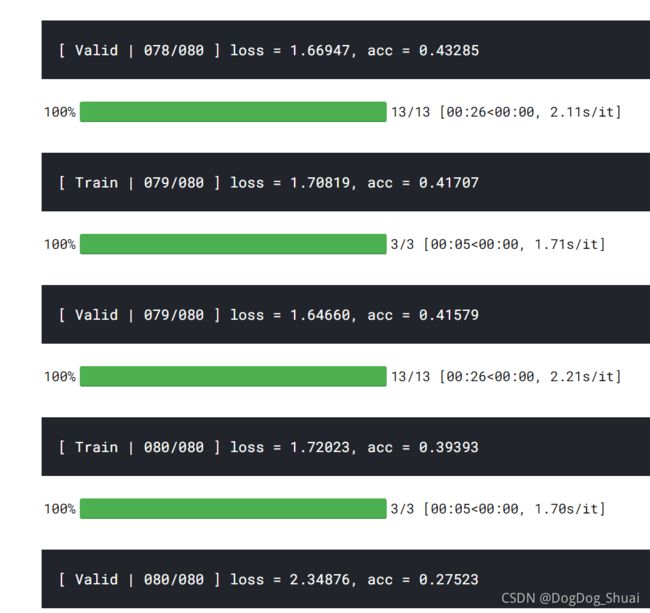
说明没train起来,可能与数据增强有关。
Kaggle得分:0.24985 0.26105
2.3 修改数据增强部分
操作:

结果: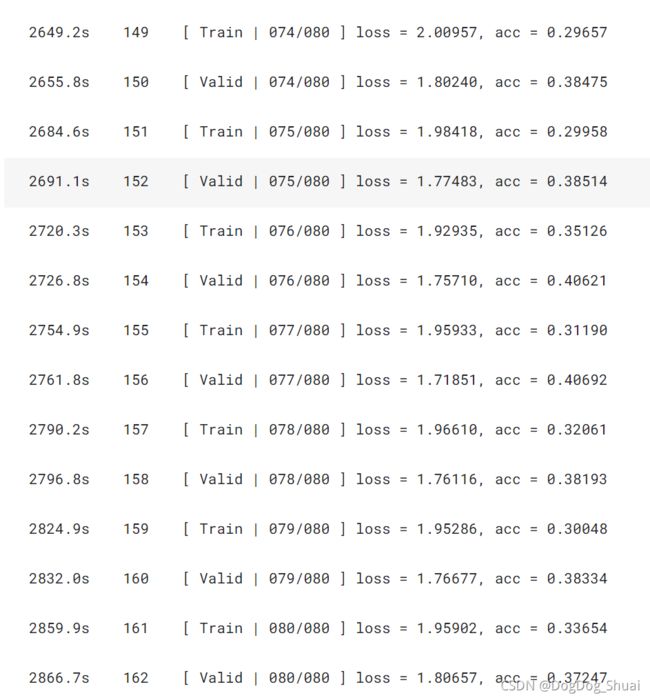
Kaggle得分:0.37477 0.36618(依然低于baseline)
说明单纯做数据增强不一定能使得结果变好。
2.4 在2.3基础上,最后全连接层处理
操作:加入dropout和batchnorm

结果:
Kaggle得分:0.22534 0.20967(最差)
操作:怀疑是batchsize调大了,调回128后试试。
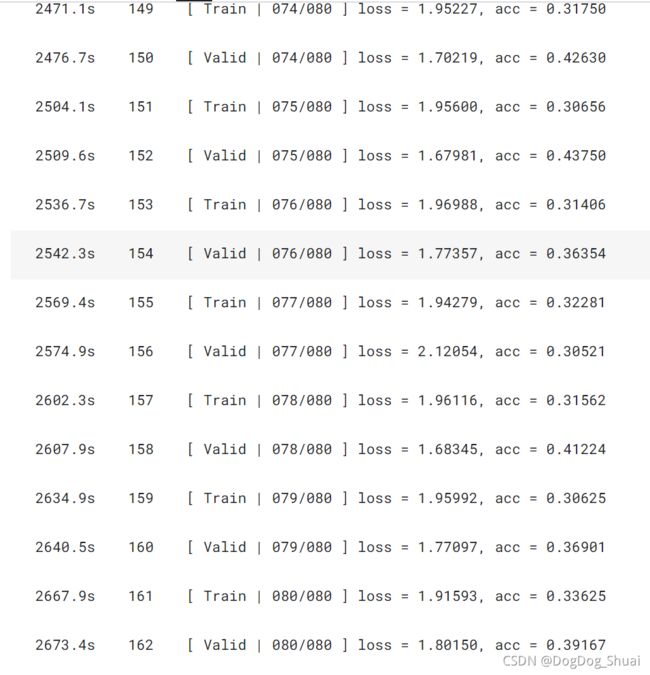
Kaggle得分:0.37597,0.38709 (结果相对于256有显著提升)
思考:本数据集图片较少,可能大的batchsize训练不好。
2.5 半监督
操作:加入半监督训练,同时为了训练速度快点,减少了epoch到20
结果: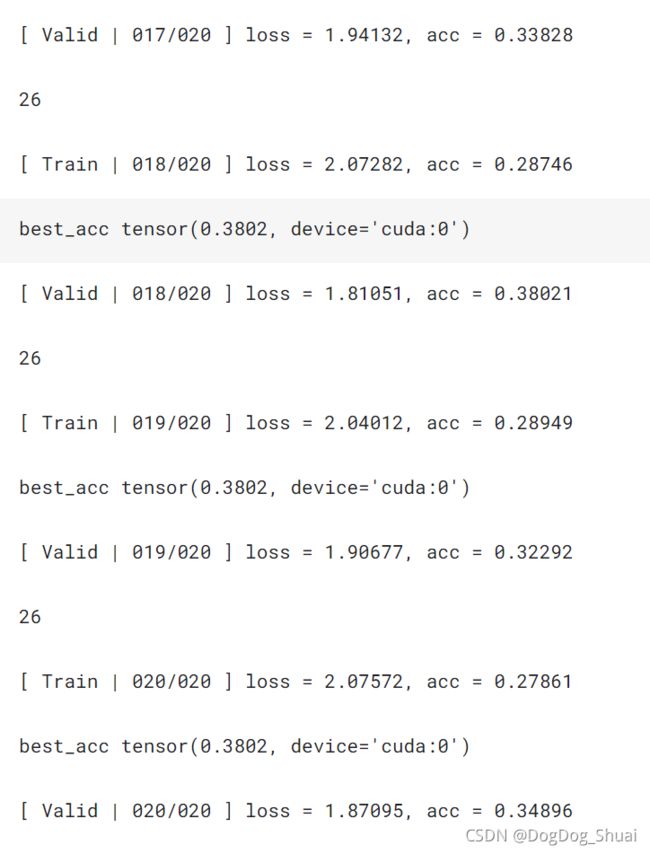
kaggle结果:0.27196,0.26583
三、总结
由于时间有限,也就不再继续实验了。欢迎小伙伴拿我的版本进行改进。
Optimizer
使用Adam
激活函数
用ReLU,效果比sigmioid好得多。
数据增强
数据增强不一定能使训练效果变好。
network架构
- 对于小样本数据集,batch size不能太大
- 加上dropout,虽然batch normalization一定程度上可以替代dropout的效果,但还是有使
- CNN的模型有一定上限,如果想改进训练效果,最好使用新的模型,比如ResNet,VGG等。
epoch太多不一定好,如果不保存最优模型的话,最终结果可能严重的过拟合。
代码链接:
https://github.com/Wangdaoshuai/LHYML2021-Spring