Elasticsearch:使用反向地理编码在地图上显示自定义区域统计数据
在实际的许多应用中,我们可能并不一定按照行政区来进行划分区域,比如我们常说江浙一代,我们可以理解江苏和浙江这两个省合在一起,而不是把它们分开。我们有时也说长江三角区,它可能是跨几个省市的一个区域,而不是单纯的一个行政区。又或者,我们常说中原城市群这样的一个概念,它其实是指的在中原的一些城市一起加起来的一个区域。那么我们该如何对这些区域进行统计呢?
Elastic 地图应用带有预定义的区域,使你可以按指标快速可视化区域。比如你可以显示每个省,市,区的统计数据。Elastic 地图还提供绘制你自己的区域地图的功能。 你可以使用你喜欢的任何区域数据,只要你的源数据包含相应区域的标识符即可。
但是,当你的源数据不包含区域标识符时,你如何映射区域呢? 这就是反向地理编码(reverse gecoding)的用武之地。 反向地理编码是根据要素的位置将区域标识符分配给要素的过程。
在本教程中,你将使用反向地理编码按 Web 流量可视化美国人口普查局联合统计区 (CSA) 区域。你将学到:
- 上传自定义区域。
- 使用 Elasticsearch enrich 处理器进行反向地理编码。
- 创建地图并通过网络流量可视化 CSA 区域
当我们完成了本教程,你将看到如下的一个地图:
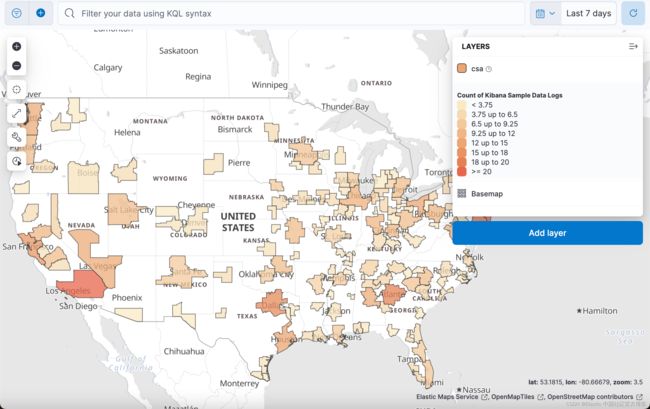
很显然在上面的地图中,所显示的 CSA 的各个区域和州的边界是不重合的,但是我们可以显示它们的统计数据。
在如下的展示中,我将使用最新的 Elastic Stack 8.5.2 来进行展示。
使用反向地理编码在地图上显示自定义区域统计数据
索引网络流量数据
GeoIP 是将 IP 地址转换为经度和纬度的常用方法。 GeoIP 在全球城市层面和选定国家/地区的社区层面大致准确。 它不如手机中的实际 GPS 位置好,但它比国家、州或省精确得多。
在今天的教程中,我们将使用 Kibana 自带的 web logs sample data set 来做练习。网络日志样本数据集有经度和纬度。 如果你的网络日志数据不包含经度和纬度,请使用 GeoIP 处理器将 IP 地址转换为 geo_point 字段。
我们按照如下的步骤来安装 sample data set:

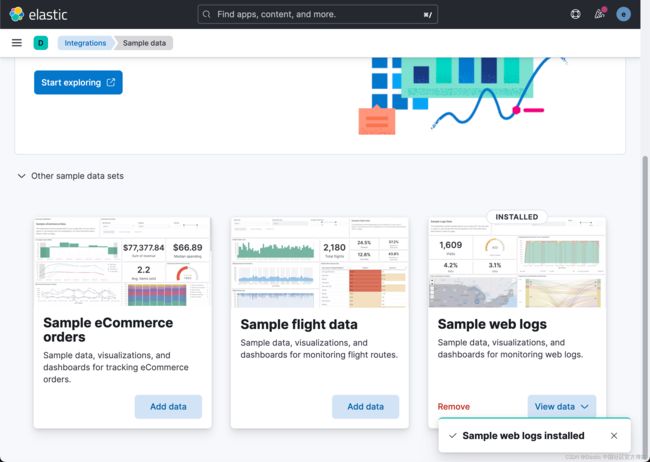
这样我们的 Sample web logs 已经被安装好了。它在 Elasticsearch 中生成一个叫做 kibana_sample_data_logs 的索引。
索引联合统计区域 (CSA) 区域
GeoIP 的详细程度对于推动决策制定非常有用。 例如,假设你想根据用户的位置开展营销活动,或者向高管利益相关者展示哪些都市区正在经历流量上升。美国的这种规模通常被人口普查局称为联合统计区 (CSA)。 CSA大致相当于人们如何直观地想到自己居住在哪个城区。 它不一定与州或城市边界重合。CSA 通常共享相同的电信提供商和广告网络。 新的快餐特许经营权扩展到 CSA,而不是特定的城市或自治市。 基本上,同一个 CSA 的人在同一个宜家购物。
要获取 CSA 边界数据,我们必须访问网站 Census Bureau’s website。然后在该网站下载 cb_2018_us_csa_500k.zip文件。

下载完后,我们对它进行解压缩:
$ pwd
/Users/liuxg/data/custom_regions
$ tree -L 2
.
├── cb_2018_us_csa_500k
│ ├── cb_2018_us_csa_500k.cpg
│ ├── cb_2018_us_csa_500k.dbf
│ ├── cb_2018_us_csa_500k.prj
│ ├── cb_2018_us_csa_500k.shp
│ ├── cb_2018_us_csa_500k.shp.ea.iso.xml
│ ├── cb_2018_us_csa_500k.shp.iso.xml
│ └── cb_2018_us_csa_500k.shx
└── cb_2018_us_csa_500k.zip我们接下来创建一个 Map:



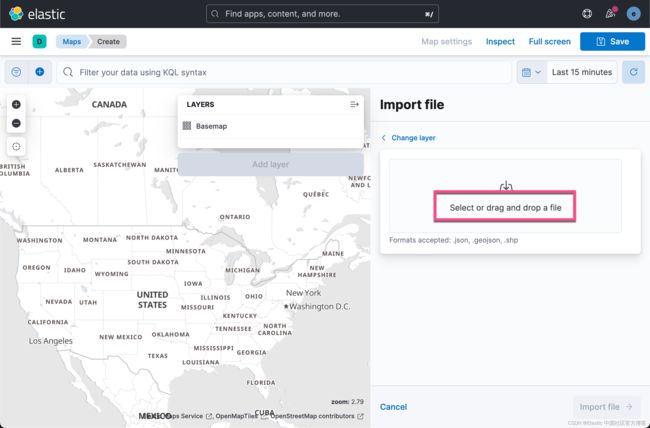

我们依次按照要求把上面解压缩的文件选择进来,并完成数据的上传:


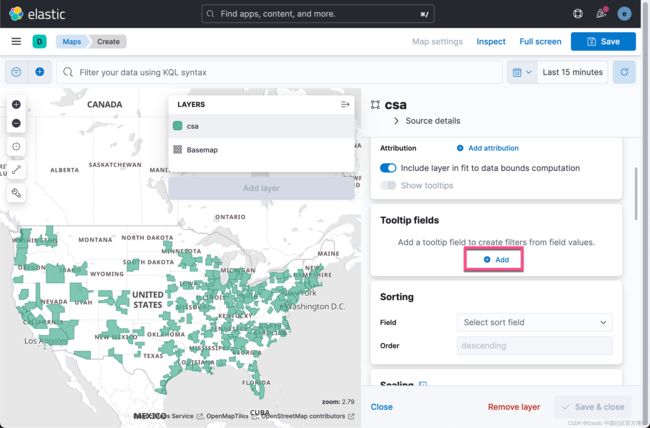
我们接下来为地图添加一下 Tooltips 字段:
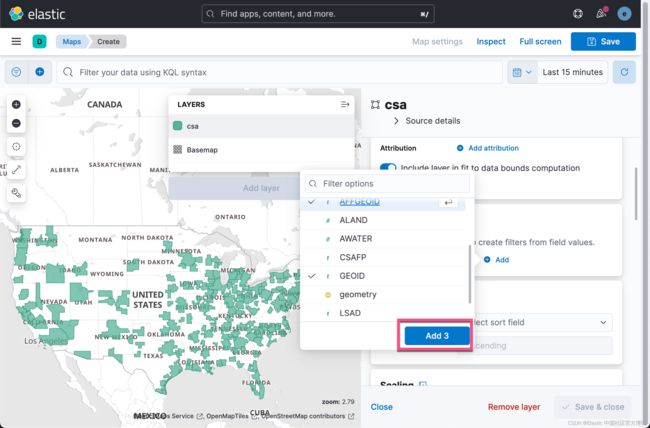
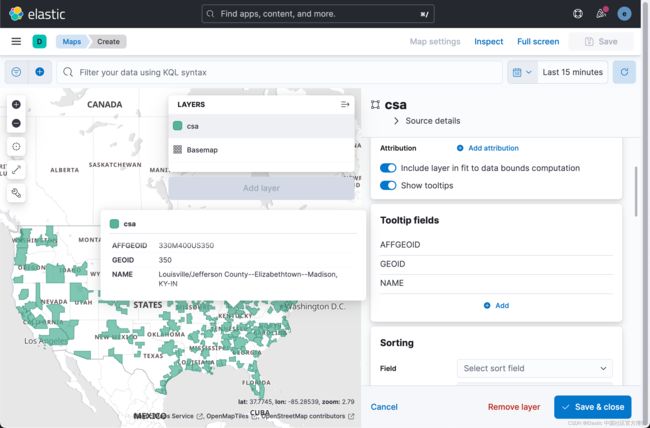
这样当我们把鼠标放到数据上时,我们可以看到它的 GEOID,AFFGEOID 及 NAME 信息。点击上面的 Save & close 按钮:

查看地图,你可以了解人口普查局眼中的都市区是什么。它显然和自然州的边界是不一样的。
反向地理编码
要通过 Web 日志流量可视化 CSA 区域,Web 日志流量必须包含 CSA 区域标识符。 你将使用 Elasticsearch enrich 处理器将 CSA 区域标识符添加到 Web 日志示例数据集中。 如果你的源数据已包含区域标识符,则可以跳过此步骤。
在控制台中,创建一个 geo_match 丰富策略:
PUT /_enrich/policy/csa_lookup
{
"geo_match": {
"indices": "csa",
"match_field": "geometry",
"enrich_fields": [ "GEOID", "NAME"]
}
}这个意思其实就是通过匹配 geometry 这个字段,如果地理位置落在 geometry 所定义的范围,那么就从 csa 索引中提取 GEOID 及 NAME 两个字段并添加到自己的索引中。
要初始化策略,请运行:
POST /_enrich/policy/csa_lookup/_execute要创建摄取管道,请运行:
PUT _ingest/pipeline/lonlat-to-csa
{
"description": "Reverse geocode longitude-latitude to combined statistical area",
"processors": [
{
"enrich": {
"field": "geo.coordinates",
"policy_name": "csa_lookup",
"target_field": "csa",
"ignore_missing": true,
"ignore_failure": true,
"description": "Lookup the csa identifier"
}
},
{
"remove": {
"field": "csa.geometry",
"ignore_missing": true,
"ignore_failure": true,
"description": "Remove the shape field"
}
}
]
}要更新现有数据,请运行:
POST kibana_sample_data_logs/_update_by_query?pipeline=lonlat-to-csa要在摄取时对新文档运行管道,请运行:
PUT kibana_sample_data_logs/_settings
{
"index": {
"default_pipeline": "lonlat-to-csa"
}
}针对我们的情况,我们不需要运行上面的这个命令。我们只需要运行上面的 _update_by_query 这个命令即可。运行完后,我们可以在 Discover 中重新查看索引 kibana_sample_data_logs:

我们可以在索引的文档中看到新增加的 csa.GEOID 及 csa.NAME 两个字段。 我们甚至可以把当前的显示调整为:
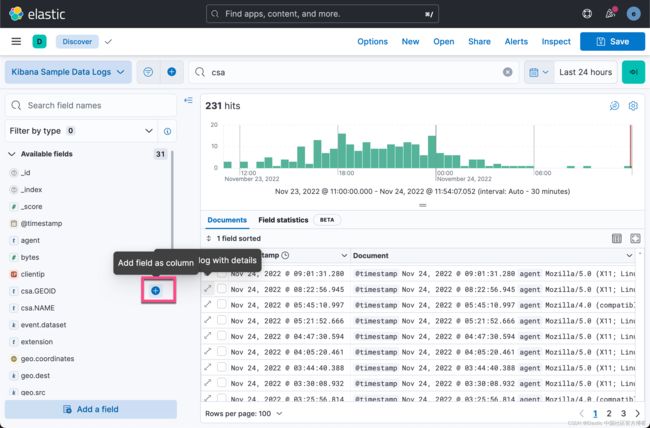
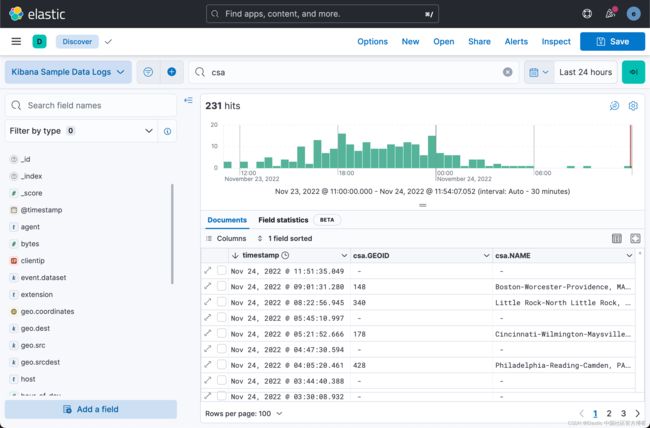
我们可以看到有些文档没有相应的 GEOID 及 csa.NAME。它们表明它们不在 CSA 所覆盖的范围里。
按 Web 流量可视化组合统计区域 (CSA) 区域
现在我们的网络流量包含 CSA 区域标识符,你将按网络流量可视化 CSA 区域。我们进行如下的操作:




点击上面的 Add layer 按钮:
这样我们就能看出来 Web logs 在各个 CSA 区域里的情况了。