2022/11/14-11/19周报
周报内容:
1.《工业缺陷检测深度学习方法综述》精读
2.复现《ChangChip》
3.复现《Gaussian Anomaly Detection》
4.下周工作计划
学习产出:
一、《工业缺陷检测深度学习方法综述》精读并结合前面复现内容

工业缺陷检测更关注像素层面的检出任务。
在像素层面上, 异常与正常模式的差别更加细微, 检测难度也大幅增加, 工业缺陷往往出现在图像中的小部分区域, 显著程度更低, 且语义概念模糊. 因而, 工业缺陷检测更关注于检测图像中的异常像素.
工业视觉缺陷检测任务一般包括分类和定位。
对于一个待测图像实例, 分类任务首先将其二分类为正常样本或缺陷样本; 当缺陷类型已知时, 还可进一步对缺陷类型进行判别。
定位任务的目标是找到缺陷在图像中的具体区域, 根据缺陷区域的描述方式可分为检测 (检测框) 与分割 (像素级).
在实际的工业缺陷定位任务中, 研究者们更关注缺陷分割方法.。
1.有监督方法:如YOLOE+
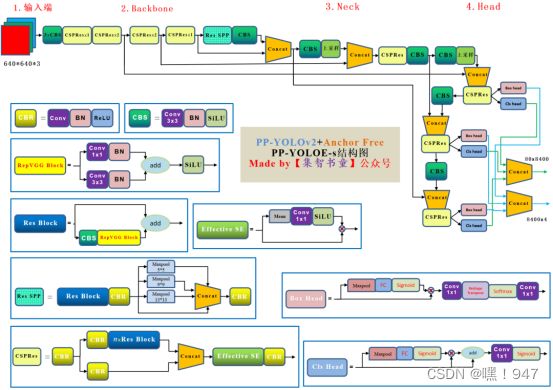
对模型的调整主要在于两个思路:引入轻量化网络提升检测速度; 利用多尺度融合与数据增强等方法来提升检测精度
但在实际情况中, 含有缺陷的样本极难获取. 面对缺陷的未知性与无规则性, 基于缺陷先验知识的方法存在较大的局限性. 因此, 无监督的设置已经引起了广泛重视.
2.无监督方法
缺陷被定义为正常范围之外的模式.
此时定位结果的输出一般是像素级的分割结果
(1)基于图像重建的方法:
仅在正常样本上训练模型, 使其学习到足以用来重建出正常样本的分布特征. 如:Draem
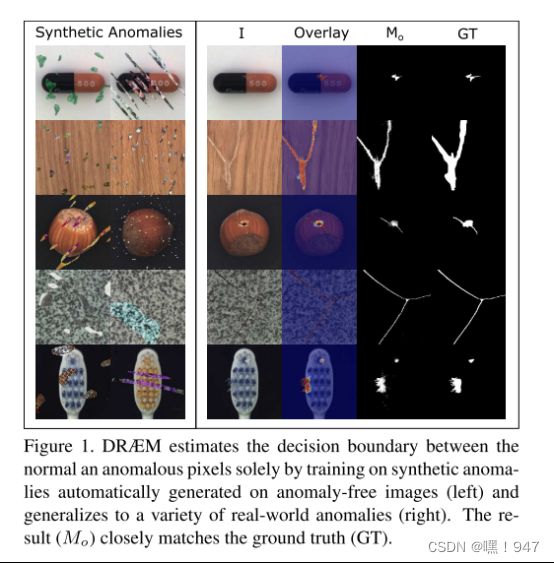
但重建图像的像素可能未与输入图像对齐, 重建过程还可能同时改变图像的风格, 这些偏
差都会导致检测错误, 限制了检测的性能.
(2)基于特征相似度的方法:
借助深度神经网络的特征提取能力, 此类方法的核心目的是找到具有区分性的特征嵌入, 并减少无关特征的干扰。.如:ChangChip

但ChangChip对参照图和测试图要求较高,对于可活动范围区域容易产生误检
(3)基于特征距离度量的方法
如:《Gaussian Anomaly Detection by Modeling the Distribution of Normal Data in Pretrained Deep Features》和《Modeling the distribution of normal data in pre-trained deep features for anomaly detection.》(下周可以看看这篇论文)
二、复现《ChangChip》
测试图(有缺陷):

参考图(无缺陷):

差异图:


mse:
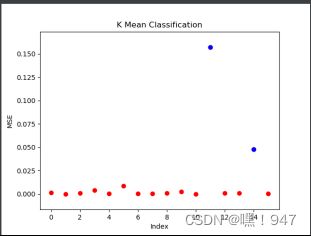
使用我们的数据集:
测试图和参考图:


差异图:


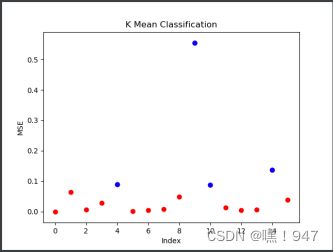
结果分析:可以判断出四个缺陷的位置,但同时,也会因为光照和元器件摆放位置而造成误检
三、复现《Gaussian Anomaly Detection》
调试代码,使用MvTec AD数据集进行实验:

性能良好。
由于测试集需要异常样本,及其缺陷位置的掩膜。
利用labelimg标注生成的.xml文件,生成相应的掩膜图(虽然要求的是生成像素级别的掩膜图--有缺陷轮廓的,但是整了半天还是不会弄,只好利用现成的标注文件了,先试试效果怎么样):

四、下周工作计划
1.将制作好的数据集加入多元高斯模型查看效果
2.多尝试数据集分类方法,提升聚类质量
在工业场景中,元器件的位置会有微小的变动,而我们的缺陷对于整个图像来说,也只是微小的变化,那么特征点是否能从中分离出来呢?
尤其是可活动范围区域,对多元高斯和Changechip两者方法都影响较大。
初步想法:
1.Changechip:人工打标,遮蔽住可活动范围区域,对其他区域进行对比检测
2.多元高斯:想一种分块方法,对可活动区域进行额外分析。 (先对其组件识别? --但是元器件种类会不会一直迭代,后续要添加新类别)