手撕VGG卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。
大家经常在评论区问我如果学习Python,如何锻炼 自己的Python编程能力,这里给大家推荐一个我经常练习Python的网站:牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
里面还包含很多大厂笔试的Python题目,大家可以跟我一起刷题,从本周起我会陆续在博客分享我的刷题心得,欢迎大家跟我一起学习,有问题可以在评论区指出来,大家一起讨论。
Alexnet网络详解代码:手撕Alexnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客_alexnet神经网络代码
VGG网络详解代码: 手撕VGG卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客
Resnet网络详解代码: 手撕Resnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客
Googlenet网络详解代码:手撕Googlenet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客_cnn测试集准确率低
集成学习模型融合网络详解代码:
集成学习-模型融合(Lenet,Alexnet,Vgg)三个模型进行融合-附源代码-宇宙的尽头一定是融合模型而不是单个模型。_小馨馨的小翟的博客-CSDN博客_torch模型融合
深度学习常用数据增强,数据扩充代码数据缩放代码:
深度学习数据增强方法-内含(亮度增强,对比度增强,旋转图图像,翻转图像,仿射变化扩充图像,错切变化扩充图像,HSV数据增强)七种方式进行增强-每种扩充一张实现7倍扩)+ 图像缩放代码-批量_小馨馨的小翟的博客-CSDN博客_训练数据增强
VGG”代表了牛津大学的Oxford Visual Geometry Group,VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果。”对于网上很多的VGG的代码写的不够详细,比如没有详细的写出同时画出训练集的loss accuracy 和测试集的loss和accuracy的折线图,因此这些详细的使用pytorch框架复现了一下VGG代码,并且对于我们需要的loss和accuracy的折线图用matplotlib进行了绘制。
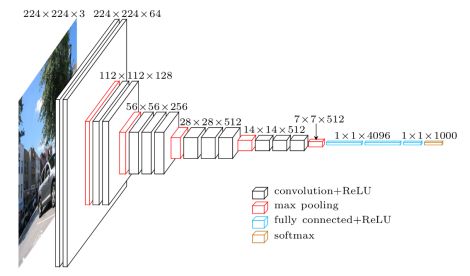
VGG网络结构图如下:
导入库导入库:
import torch
import torchvision
import torchvision.models
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms图像预处理方法:
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), #这种预处理的地方尽量别修改,修改意味着需要修改网络结构的参数,如果新手的话请勿修改
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}数据导入方法: 导入自己的数据,自己的数据放在跟代码相同的文件夹下新建一个data文件夹,data文件夹里的新建一个train文件夹用于放置训练集的图片。同理新建一个val文件夹用于放置测试集的图片。
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset= train_data , batch_size= 32 , shuffle= True , num_workers=0 )
# test_data = torchvision.datasets.CIFAR10(root = "./data" , train = False ,download = False,
# transform = trans)
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data)#求出训练集的长度
test_size = len(test_data) #求出测试集的长度
print(train_size) #输出训练集的长度
print(test_size) #输出测试集的长度
testdata = DataLoader(dataset = test_data , batch_size= 32 , shuffle= True , num_workers=0 )#windows系统下,num_workers设置为0,linux系统下可以设置多进程设置调用GPU,如果有GPU就调用GPU,如果没有GPU则调用CPU训练模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))VGG卷积神经网络
class VGG(nn.Module):
def __init__(self, features, num_classes=7, init_weights=False):#自己是几种就把这个7改成几
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(4608, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights() #参数初始化
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): #遍历各个层进行参数初始化
if isinstance(m, nn.Conv2d): #如果是卷积层的话 进行下方初始化
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) #正态分布初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) #如果偏置不是0 将偏置置成0 相当于对偏置进行初始化
elif isinstance(m, nn.Linear): #如果是全连接层
nn.init.xavier_uniform_(m.weight) #也进行正态分布初始化
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0) #将所有偏执置为0
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
VGGnet = vgg(num_classes=7, init_weights=True) #将模型命名为#自己是几种就把这个7改成几
VGGnet.to(device)
print(VGGnet.to(device)) #输出模型结构启动模型,将模型放入GPU,且进行测试
test1 = torch.ones(64, 3, 120, 120) # 测试一下输出的形状大小 输入一个64,3,120,120的向量
test1 = VGGnet(test1.to(device)) #将向量打入神经网络进行测试
print(test1.shape) #查看输出的结果
设置训练需要的参数,epoch,学习率learning 优化器。损失函数。
epoch = 10#这里是训练的轮数
learning = 0.0001 #学习率
optimizer = torch.optim.Adam(VGGnet.parameters(), lr = learning)#优化器
loss = nn.CrossEntropyLoss()#损失函数设置四个空数组,用来存放训练集的loss和accuracy 测试集的loss和 accuracy
train_loss_all = []
train_accur_all = []
test_loss_all = []
test_accur_all = []开始训练:
for i in range(epoch): #开始迭代
train_loss = 0 #训练集的损失初始设为0
train_num = 0.0 #
train_accuracy = 0.0 #训练集的准确率初始设为0
VGGnet.train() #将模型设置成 训练模式
train_bar = tqdm(traindata) #用于进度条显示,没啥实际用处
for step, data in enumerate(train_bar): #开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img, target = data #将data 分位 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs = VGGnet(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
loss1 = loss(outputs, target.to(device)) # 计算神经网络输出的结果outputs与图片真实标签target的差别-这就是我们通常情况下称为的损失
outputs = torch.argmax(outputs, 1) #会输出10个值,最大的值就是我们预测的结果 求最大值
loss1.backward() #神经网络反向传播
optimizer.step() #梯度优化 用上面的abam优化
train_loss += abs(loss1.item()) * img.size(0) #将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) #outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy #求训练集的准确率
train_num += img.size(0) #
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i + 1, train_loss / train_num, #输出训练情况
train_accuracy / train_num))
train_loss_all.append(train_loss / train_num) #将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item() / train_num)#训练集的准确率开始测试:
test_loss = 0 #同上 测试损失
test_accuracy = 0.0 #测试准确率
test_num = 0
VGGnet.eval() #将模型调整为测试模型
with torch.no_grad(): #清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img, target = data
outputs = VGGnet(img.to(device))
loss2 = loss(outputs, target.to(device))
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + abs(loss2.item()) * img.size(0)
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss / test_num)
test_accur_all.append(test_accuracy.double().item() / test_num)
绘制训练集loss和accuracy图 和测试集的loss和accuracy图
plt.figure(figsize=(12,4))
plt.subplot(1 , 2 , 1)
plt.plot(range(epoch) , train_loss_all,
"ro-",label = "Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-",label = "test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch) , train_accur_all,
"ro-",label = "Train accur")
plt.plot(range(epoch) , test_accur_all,
"bs-",label = "test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(alexnet1.state_dict(), "alexnet.pth")
print("模型已保存")全部train训练代码:
import torch
import torchvision
import torchvision.models
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
train_data = torchvision.datasets.ImageFolder(root = "./玉米data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset=train_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行训练
test_data = torchvision.datasets.ImageFolder(root = "./玉米data/val" , transform = data_transform["val"])
train_size = len(train_data) # 训练集的长度
test_size = len(test_data) # 测试集的长度
print(train_size) #输出训练集长度看一下,相当于看看有几张图片
print(test_size) #输出测试集长度看一下,相当于看看有几张图片
testdata = DataLoader(dataset=test_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行测试
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
class VGG(nn.Module):
def __init__(self, features, num_classes=7, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(4608, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights() #参数初始化
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): #遍历各个层进行参数初始化
if isinstance(m, nn.Conv2d): #如果是卷积层的话 进行下方初始化
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) #正态分布初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) #如果偏置不是0 将偏置置成0 相当于对偏置进行初始化
elif isinstance(m, nn.Linear): #如果是全连接层
nn.init.xavier_uniform_(m.weight) #也进行正态分布初始化
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0) #将所有偏执置为0
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
VGGnet = vgg(num_classes=7, init_weights=True) #将模型命名为alexnet1
VGGnet.to(device)
print(VGGnet.to(device)) #输出模型结构
test1 = torch.ones(64, 3, 120, 120) # 测试一下输出的形状大小 输入一个64,3,120,120的向量
test1 = VGGnet(test1.to(device)) #将向量打入神经网络进行测试
print(test1.shape) #查看输出的结果
epoch = 15 # 迭代次数即训练次数
learning = 0.001 # 学习率
optimizer = torch.optim.Adam(VGGnet.parameters(), lr=learning) # 使用Adam优化器-写论文的话可以具体查一下这个优化器的原理
loss = nn.CrossEntropyLoss() # 损失计算方式,交叉熵损失函数
train_loss_all = [] # 存放训练集损失的数组
train_accur_all = [] # 存放训练集准确率的数组
test_loss_all = [] # 存放测试集损失的数组
test_accur_all = [] # 存放测试集准确率的数组
for i in range(epoch): #开始迭代
train_loss = 0 #训练集的损失初始设为0
train_num = 0.0 #
train_accuracy = 0.0 #训练集的准确率初始设为0
VGGnet.train() #将模型设置成 训练模式
train_bar = tqdm(traindata) #用于进度条显示,没啥实际用处
for step, data in enumerate(train_bar): #开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img, target = data #将data 分位 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs = VGGnet(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
loss1 = loss(outputs, target.to(device)) # 计算神经网络输出的结果outputs与图片真实标签target的差别-这就是我们通常情况下称为的损失
outputs = torch.argmax(outputs, 1) #会输出10个值,最大的值就是我们预测的结果 求最大值
loss1.backward() #神经网络反向传播
optimizer.step() #梯度优化 用上面的abam优化
train_loss += abs(loss1.item()) * img.size(0) #将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) #outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy #求训练集的准确率
train_num += img.size(0) #
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i + 1, train_loss / train_num, #输出训练情况
train_accuracy / train_num))
train_loss_all.append(train_loss / train_num) #将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item() / train_num)#训练集的准确率
test_loss = 0 #同上 测试损失
test_accuracy = 0.0 #测试准确率
test_num = 0
VGGnet.eval() #将模型调整为测试模型
with torch.no_grad(): #清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img, target = data
outputs = VGGnet(img.to(device))
loss2 = loss(outputs, target.to(device))
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + abs(loss2.item()) * img.size(0)
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss / test_num)
test_accur_all.append(test_accuracy.double().item() / test_num)
#下面的是画图过程,将上述存放的列表 画出来即可
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(epoch), train_loss_all,
"ro-", label="Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-", label="test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch), train_accur_all,
"ro-", label="Train accur")
plt.plot(range(epoch), test_accur_all,
"bs-", label="test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(VGGnet, "VGG.pth")
print("模型已保存")
全部predict代码:
import torch
from PIL import Image
from torch import nn
from torchvision.transforms import transforms
image_path = "1.png"#相对路径 导入图片
trans = transforms.Compose([transforms.Resize((120 , 120)),
transforms.ToTensor()]) #将图片缩放为跟训练集图片的大小一样 方便预测,且将图片转换为张量
image = Image.open(image_path) #打开图片
print(image) #输出图片 看看图片格式
image = image.convert("RGB") #将图片转换为RGB格式
image = trans(image) #上述的缩放和转张量操作在这里实现
print(image) #查看转换后的样子
image = torch.unsqueeze(image, dim=0) #将图片维度扩展一维
classes = ["1" , "2" , "3" , "4" , "5" , "6" , "7" ] #预测种类
class VGG(nn.Module):
def __init__(self, features, num_classes=10, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(4608, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights() #参数初始化
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): #遍历各个层进行参数初始化
if isinstance(m, nn.Conv2d): #如果是卷积层的话 进行下方初始化
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) #正态分布初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) #如果偏置不是0 将偏置置成0 相当于对偏置进行初始化
elif isinstance(m, nn.Linear): #如果是全连接层
nn.init.xavier_uniform_(m.weight) #也进行正态分布初始化
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0) #将所有偏执置为0
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
#以上是神经网络结构,因为读取了模型之后代码还得知道神经网络的结构才能进行预测
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #将代码放入GPU进行训练
print("using {} device.".format(device))
model = torch.load("VGG.pth") #读取模型
model.eval() #关闭梯度,将模型调整为测试模式
with torch.no_grad(): #梯度清零
outputs = model(image.to(device)) #将图片打入神经网络进行测试
print(model) #输出模型结构
print(outputs) #输出预测的张量数组
ans = (outputs.argmax(1)).item() #最大的值即为预测结果,找出最大值在数组中的序号,
# 对应找其在种类中的序号即可然后输出即为其种类
print(classes[ans])代码下载链接:https://pan.baidu.com/s/1q4FyGHWvF9odirZAbWWCIw
提取码:iled
有用的话麻烦点一下关注,博主后续会开源更多代码,非常感谢支持!