numpy库的一些解释
Numpy库介绍
NumPy是一个的Python库,主要用于对多维数组执行计算。 NumPy这个词来源于两个单词-- Numerical [njuːˈmerɪkl] (数值;数值法;数值的;数字的)和 Python。主要用来进行数值计算。
有以下几个特点:
1.numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算。
2.Numpy底层使用C语言编写,其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码。
3.有一个强大的N维数组对象Array [əˈreɪ] (数组:相同数据类型的集合。可以简单理解为一种类似于列表的东西,只不过这个列表里的元素类型是相同的)。
4.实用的线性代数、傅里叶变换和随机数生成函数。
与列表功能的异同
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
Python列表可以存储一维数组,通过列表的嵌套可以实现多维数组。
两者都是数据容器,索引都是从0开始,那么为什么还需要使用Numpy呢?
Numpy对数组的操作和运算进行了优化,数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,Numpy的优势就越明显。通常Numpy数组中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以在通用性能方面Numpy数组不及Python列表。
Numpy优化:例如在科学计算中,Numpy数组可以省掉很多循环语句,代码使用方面比Python列表简单的多。
将相同长度的数组与列表内的每个元素都进行平方,查看两者所需时间。
import numpy as np
import time
#获得程序执行 前 的时间戳
t1=time.time()
a=[]
for x in range(1000000):
a.append(x)
#获得程序执行 后 的时间戳
t2=time.time()
#得到程序运行的时间
print(t2-t1) #>>> 0.37305760383605957
t3=time.time()
#数组是可以直接进行向量运算的,省掉很多循环语句
b=np.arange(1000000)**2
t4=time.time()
print(t4-t3) #>>> 0.004000186920166016
python 所有的库都是围绕者对象来进行操作的,numpy 也不例外,接下我们来依据numpy库 的重要对象 Ndarray来进行学习。
Ndarray对象的创建
方法一:调用 array() 方法。array [əˈreɪ] 数组
array ( object , dtype = None, copy =True, ndmin = 0 order= ‘None’, subok = False )
object :元素类型相同的一组数据,例如嵌套的数列。
dtype : 数组元素的数据类型。
copy :对象是否需要复制。
ndmin :指定数组的最小秩,即最小维度。
order :数组样式。
subok :是否返回一个与基类类型一致的数组。
方法二:arange(),等差数组
arange ( [start,] stop[, step,], dtype=None )
根据开始,结束与步长生成一个 ndarray数组对象。
start :起始值,默认为 0。
stop :结束值,所生成的数组并不包含这个值。
step :步长,默认为 1。
dtype:数据类型。
这个方法与python函数 range () ,用法完全一致,只不过前者返回的是一个 range对象,后者返回一个数组。
方法三:随机数组,numpy.random 模块
这是别人写的,很全面,我就不写了。
这也是别人写的。
方法四:一些特别的数组
1.numpy.zeros (shape, dtype=float, order=‘C’, *, like=None)
**返回具有给定形状、数据类型和顺序的零数组。
numpy.ones (shape, dtype=float, order=‘C’, *, like=None)
**返回具有给定形状、数据类型和顺序的 1 数组。
numpy.ones .full(shape, fill_value, dtype=None, order=‘C’)
**返回具有给定形状、填充值、数据类型和顺序的数组。
numpy.eye (N:int)
**返回单位矩阵(矩阵是二维数组)。
- shape:正整数,或者由正整数组成的元组。
- fill_value:填充数组的值,类型是个标量:scalar
[ˈskeɪlə]。 - dtype:数据类型。
- order :数组样式。
Ndarray对象的属性和方法。
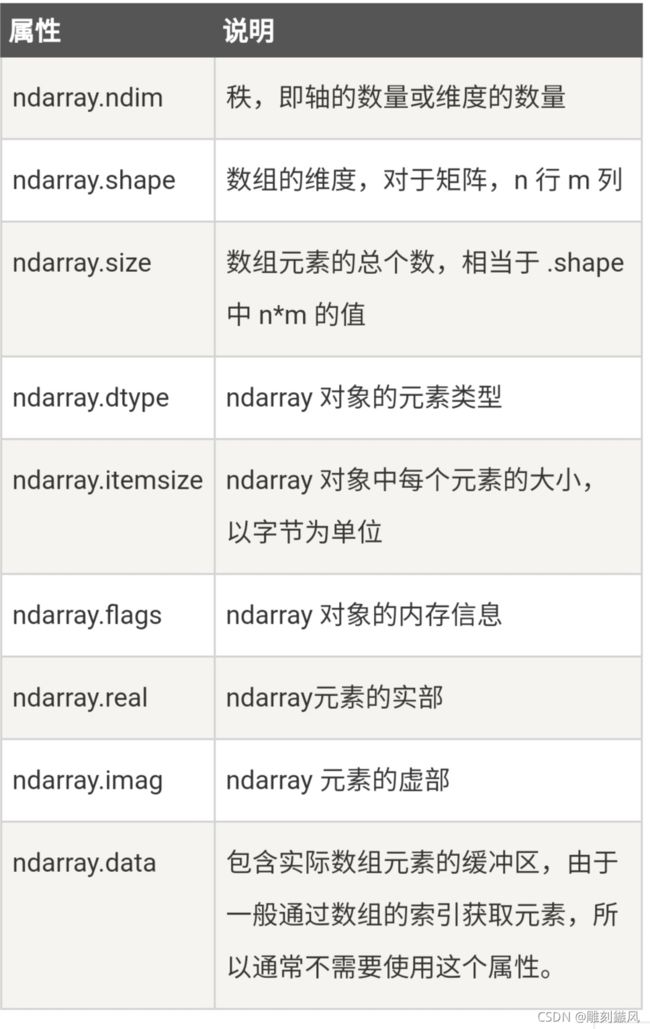
Ndarray对象的五个常见属性:
import numpy as np
a=np.array([[1,2,3],[4,5,6]],dtype='int8')
print(f'秩,即轴的数量或维度的数量: {a.ndim}')
print(f'ndarray对象的尺度,也就是几行几列: {a.shape}')
print(f'ndarray对象中的元素个数: {a.size}')
print(f'ndarray对象中元素的类型: {a.dtype}')
print(f'ndarray对象中元素的大小:{a.itemsize}')
print(f'对象内容:\n{a}',f'什么类型:{type(a)}',sep='\n')

Ndarray对象中元素的类型
与列表对象中元素可以是六种标准数据类型不同,Ndarray对象中元素的类型必须是数字类型,而且一个Ndarray对象中只能出现同一种数字类型,常见的可分为四种:布尔:bool,整型:int,浮点:float,无符号整型:uint。

Ndarray对象常见方法 - - -切片与索引
-
索引作用:根据索引条件,获取数组中特定的元素。
-
切片作用:获取数组元素的子集,切片可以看作索引的一种,所以这里把切片当作索引来讲。
-
索引符号: [ ],中括号内可以放整数,切片,布尔值等等。
-
对于一维数组而言,它的切片与索引和列表是完全一致的。
-
对于多维数组而言,它的索引分为以下几类:
整数索引:
从0开始,用逗号隔开不同维度。注意不得超过数组的尺度。
例如 a [1,2,3 ]表示在三维数组的第一维度中取索引为1的元素,进而在改元素中取索引为2的元素,再在其中取索引为3的元素。
import numpy as np
a=np.arange(12).reshape(3,2,2)
print(a)
print('*'*15)
print(a[2,1,0])
print(a[2,1])

切片索引:
通过冒号分隔切片参数 start:stop:step 来进行切片操作,冒号的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
import numpy as np
a=np.arange(12).reshape(3,4)
print(a)
print('*'*15)
print('冒号代表者在该维度取所有值。')
print('取所有行和第一列:')
print(a[:,1])
print('取所有行和第一,二列:')
print(a[:,1:3])
 整数数组索引
整数数组索引
import numpy as np
a=np.arange(1,7).reshape(3,2)
print(a)
print('获取数组中(0,0),(1,1)和(2,0)位置处的元素:')
print(a[[0,1,2],[0,1,0]])
b=np.arange(12).reshape(4,3)
print('*'*15)
print(b)
c='''获取二维数组 4X3 数组中的四个角的元素。
行索引是 [0,0] 和 [3,3],
列索引是 [0,2] 和 [0,2]
'''
print(c)
rows=np.array([[0,0],[3,3]])
cols=np.array([[0,2],[0,2]])
print(b[rows,cols])

布尔索引
通过一个布尔数组来索引目标数组。
在中括号内放入布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
Ndarray对象常见方法 - - -数组形态变化
修改数组形状:
1 . ndarray.reshape ( newshape , order=‘C’)
2 . ndarray.resize ( newshape , order=‘C’)
- newshape:整数或者整数数组,新形状应当兼容原有形状。
- order:新数组元素排列样式,‘C’ - - 按行排列,‘F’ – 按列排列,‘A’ – 原顺序 ,‘K’ --按元素在内存中出现的顺序。
import numpy as np
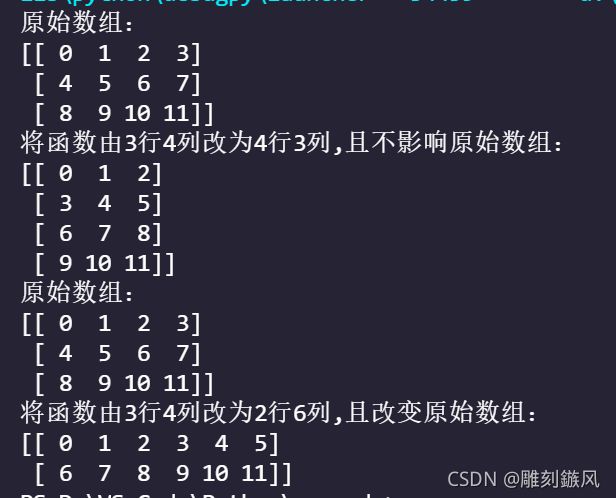
a=np.array([[ 0,1,2,3],[4,5,6,7],[8,9,10,11]])
print(f'原始数组:\n{a}')
b=a.reshape(4,3,order='c')
print(f'将函数由3行4列改为4行3列,且不影响原始数组:\n{b}')
print(f'原始数组:\n{a}')
a.resize(2,6)
print(f'将函数由3行4列改为2行6列,且改变原始数组:\n{a}')
reshape()方法和resize()方法都是重新定义形状的。但是reshape不会修改数组本身 而是将修改后的结果返回回去,而resize是直接修该数组本身的,且没有返回值。
- ndarray.flatten ( order=‘C’ )
- ndarray.ravel ( order=‘C’ )
- order:新数组元素排列样式,‘C’ - - 按行排列,‘F’ – 按列排列,‘A’ – 原顺序 ,‘K’ --按元素在内存中出现的顺序。
import numpy as np
a=np.array([[ 0,1,2,3],[4,5,6,7],[8,9,10,11]])
print(f'原始数组:\n{a}')
b=a.flatten(order='f')
print(f'按列展开:{b}')
print('修改用方法flatten展开数组,并不影响原始数组。')
b[3]=100
print(f'原始数组:\n{a}')
c=a.ravel(order='c')
print(f'按行展开:{c}')
print('修改用方法ravel展开数组,改变了原始数组。')
c[3]=100
print(f'原始数组:\n{a}')

flatten和ravel都是用来将数组展开,变成一维数组的,并且他们都不会对原类数组造成修改,但是flatten返回的是一个拷贝,所以对flatten的返回值的修改不会影响到原来数组,而ravel返回的是一个视图View,那么对返回值的修改会影响到原来数组的值。
翻转数组
Ndarray.transpose ()
import numpy as np
a=np.array([[ 0,1,2,3],[4,5,6,7],[8,9,10,11]])
print(f'原始数组:\n{a}')
print(f'对换数组的维度:\n{a.transpose()}')
print('翻转后并不改变原始数组。')
print(f'原始数组:\n{a}')

连接数组
- ndarray.concatenate ( (a1,a2,—),axis=0)
将相同形状的数组沿指定轴进行连接。
- a1,a2,—:与ndarray相同类型的数组
- axis:连接数组的轴,默认为0,
1表示横轴,方向从左到右;0表示纵轴,方向从上到下;-1表示最后一个轴。
当axis=1时,数组的变化是横向的,而体现出来的是列的增加或者减少。
当axis=0时,数组的变化是纵向的,而体现出来的是行的增加或者减少。
import numpy as np
from numpy.core.fromnumeric import reshape
a=np.arange(4).reshape(2,2)
b=np.arange(5,9).reshape(2,2)
print(a,b,sep='\n')
print('沿第一个维度连接两个数组:')
c=np.concatenate((a,b),axis=0)
print(c)
print('沿第二个维度连接两个数组:')
d=np.concatenate((a,b),axis=1)
print(d)

分割数组
这是numpy的内置函数,不是Ndarray的方法。
- numpy.split (ndarray, indices_or_sections, axis=0) -> list of ndarrays
- ndarray:被分割的数组
- indices_or_sections:如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)
- axis:设置沿着哪个方向进行切分。
import numpy as np
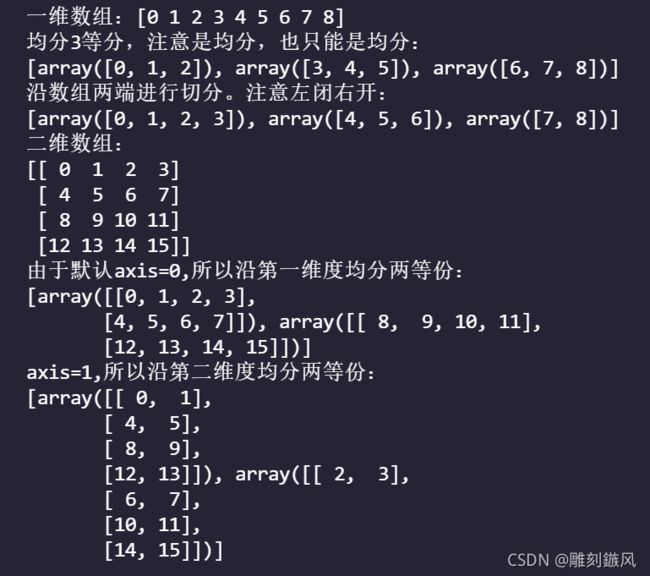
a=np.arange(9)
print(f'一维数组:{a}')
print('均分3等分,注意是均分,也只能是均分:')
b=np.split(a,3)
print(b)
print('沿数组两端进行切分。注意左闭右开:')
c=np.split(a,[4,7])
print(c)
a1=np.arange(16).reshape((4,4))
print(f'二维数组:\n{a1}')
print('由于默认axis=0,所以沿第一维度均分两等份:')
print(np.split(a1,2))
print('axis=1,所以沿第二维度均分两等份:')
print(np.split(a1,2,axis=1))
数组元素的添加与删除
末尾添加
- numpy.append ( arr,values,axis=None)
- arr:输入数组
- values:要向arr添加的值,需要和arr形状相同(除了要添加的轴)
- axis:默认为None。
当axis无定义,也就是为None时,是数组一维展开,返回总是为一维数组!
当axis有定义的时候,为0时,数组纵向变化,列数要相同;为1时,数组是横向变化,加在右边,行数要相同。
import numpy as np
a=np.arange(1,7).reshape(2,3)
print(a)
print('默认为None,是横向加成,返回总是为一维数组!')
print(np.append(a,[7,8,9]))
print('axis=0时,列数要相同')
print(np.append(a,[[7,8,9]],axis=0))
print('axis=1 时,行数要相同')
print(np.append(a,[[7,8,9],[5,5,5]],axis=1))

指定位置添加
- numpy.insert ( arr , obj , values , axis=None) ->ndarray
- arr:输入数组
- obi:在其之前插入值的索引
- values:要插入的值
- axis:沿着它插入的轴,如果未提供,则输入数组会被展开
import numpy as np
a = np.array([[1,2],[3,4],[5,6]])
print('第一个数组:')
print(a)
print('*'*15)
print('未传递Axis参数。在插入之前输入数组会被展开。')
print (np.insert(a,3,[11,12]))
print('*'*15)
print('传递了 Axis参数。会广播值数组来配输入数组。')
print('沿轴0广播,也就是第一个维度:')
print (np.insert(a,1,[11,12],axis = 0))
print('可以插入一个整数也可以插入一个数组')
print (np.insert(a,1,11,axis = 0))
print('*'*15)
print('沿轴1广播,也就是第二个维度:')
print(np.insert(a,1,[11,12,13],axis=1))
print('可以插入一个整数也可以插入一个数组')
print(np.insert(a,1,11,axis=1))

删除指定数组的子集
- numpy. ( arr , obj , axis )->ndarray
- arr:输入数组
- obj:可以是切片,整数,整数数组,表明要从arr中删除的子数组。
- axis:沿着它删除给定子数组的轴,若为默人值,则只是将数组展开成一维数组。
用法
import numpy as np
a = np.arange(12).reshape(3,4)
print ('第一个数组:')
print (a)
print ('未传递 Axis 参数。 在插入之前输入数组会被展开。')
print (np.delete(a,5))
print ('输入一个整数,删除对应的行或者列:')
print (np.delete(a,1,axis = 1))
print ('包含从数组中删除的替代值的切片:')
a = np.array([1,2,3,4,5,6,7,8,9,10])
print (np.delete(a, np.s_[::2]))
print (np.delete(a, a[::2]))

去重
- numpy.unique(arr, return_index, return_inverse, return_counts)–>tuple
- arr:输入数组,如果不是一维数组则会展开
- return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储
- return_inverse:如果为true,返回旧列表元素在新列表中的位置(下标),并以列表形式储
- return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数
import numpy as np
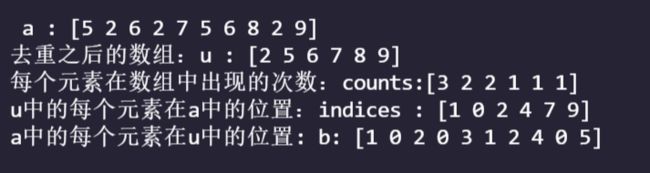
a=np.array([5,2,6,2,7,5,6,8,2,9])
u,indices,b,counts=np.unique(a,return_index=True,return_inverse=True,return_counts=True)
print(f' a : {a}')
print(f'去重之后的数组:u : {u}')
print(f'每个元素在数组中出现的次数:counts:{counts}')
print(f'u中的每个元素在a中的位置:indices : {indices}')
print(f'a中的每个元素在u中的位置: b: {b}')
Numpy库内置函数—排序
- numpy. sort ( arr, axis = -1, Kind = None, order = None ) - - - >sorted_array
- arr :array_like 类数组的
要排序的数组. - axis = -1: int或None,可选
axis = 1为横向,方向从左到右;axis = 0为纵向,方向从上到下。axis的重点在于方向,而不是行和列
axis =- 1,代表就是按照数组最后一个轴来排序;
axis = None,代表以扁平化的方式作为一个向量进行排序; - Kind = None :排序算法。默认值为’quicksort’:“快速排序”
‘quicksort’:快速排序, ‘mergesort’ :合并排序
‘heapsort’ :堆排序 ,‘stable’ :稳定 - order = None :str或str列表,可选
import numpy as np
arr=np.random.randint(0,12,(3,4))
print(arr)
print('axis=-1')
print(np.sort(arr,axis=-1))
print('axis=None')
print(np.sort(arr,axis=None))
print('axis=0')
print(np.sort(arr,axis=0))
print('axis=1')
print(np.sort(arr,axis=1))
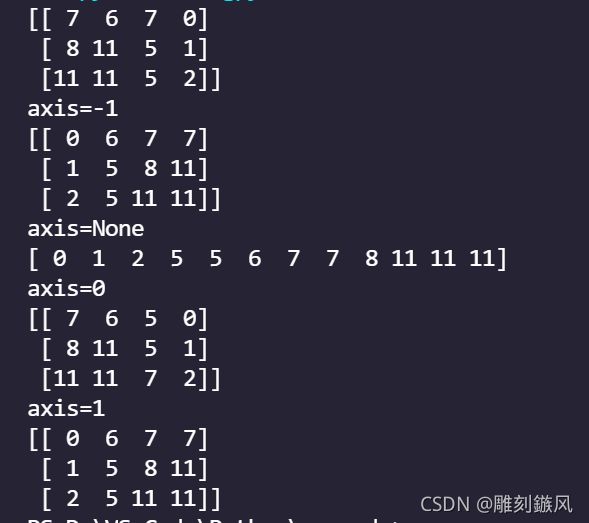
- Ndarray. sort(axis=-1, kind=None, order=None)
Ndarray对象方法与上述函数的用法与一样,且两者都是升序,不同之处在于后者没有返回值会直接影响原来数组,而前者会返回一个排序之后的新数组,不影响原数组。
降序
- 使用负号:
- numpy. sort ( - Ndarray )- 使用 numpy 内置函数,argsort ( ) 和 take ( )
indexes = numpy. argsort ( -arr )
numpy. take ( arr , indexes )
numpy. argsort ( a, axis = -1, kind = None, order = None ) - - - >索引数组 [ index_array ] : ndarray, int
- a : array_like , 类数组的
要排序的数组 - axis = -1 :整数或None 可选 ['æksɪs] 坐标轴
axis = 1为横向,方向从左到右;
axis = 0为纵向,方向从上到下。
axis =- 1,代表就是按照数组最后一个轴来排序;
axis = None,代表以扁平化的方式作为一个向量进行排序;
axis的中中文是坐标轴的意思,所以 axis 重点在于方向,而不是行和列
作用:函数返回的是数组值从小到大的索引数组。
numpy. take ( a , indices , axis = None, out = None, mode=‘raise’) - - - >ndarray
- a :原数组;
- indices :由要提取的值的索引所构成的数组
作用 :把数组 indices 中的整数当作索引在 a 中提取值。
import numpy as np
arr=np.random.randint(0,12,(3,4))
print(f'原始数组:\n{arr}')
print('使用两次负号进行降序:')
print(-np.sort(-arr))
print('*'*20)
b=np.argsort(arr)
print(f'数组 arr 从小到大的的索引数组:\n{b}')
print(np.take(arr,b))

筛选
- numpy.argmax ( arr, axis = None) - - ->index_array
- numpy.argmin ( arr, axis = None) - - ->index_array
- a : array_like , 类数组的
要排序的数组 - axis = None :整数或None 可选 ['æksɪs] 坐标轴
axis = 1为横向,方向从左到右;
axis = 0为纵向,方向从上到下。
axis =- 1,代表就是按照数组最后一个轴来排序;
axis = None,代表以扁平化的方式作为一个向量进行排序;
axis的中中文是坐标轴的意思,所以 axis 重点在于方向,而不是行和列
作用:沿指定坐标轴,返回最大和最小元素的索引数组。
- numpy. nonzero ( arr) - - - tuple_of_arrays : tuple
返回输入数组 arr 中非零元素的索引。
import numpy as np
arr=np.random.randint(0,12,(3,4))
print(f'原始数组:\n{arr}')
index_arr=np.nonzero(arr)
print(f'原始数组中非零值的索引:\n{index_arr}')
print(f'其中{index_arr[0]}表示非零值索引的横坐标;')
print(f'其中{index_arr[1]}表示非零值索引的纵坐标。')

- numpy. where ( condition, [ x = None, y = None ]) -> tuple
- numpy. extract.(condition, arr)
numpy. extract()的作用:在 arr 中抓取符合 condition 条件的元素值,并以一维数组的形式返回。
import numpy as np
arr=np.random.randint(0,12,(3,4))
print(f'原始数组:\n{arr}')
condition_1=np.where(arr>6)
print('单纯输入条件时,返回的是一个由数组构成的元组:')
print(condition_1)
print('通过条件索引进行筛选:')
print(arr[condition_1])
condition_2=np.where(arr>6,7,5)
print('后面加入值时,返回的是一个替换后的数组')
print(condition_2)
arr_6=np.extract(arr>6,arr)
print('extract()函数直接根据进行筛选:')
print(arr_6)

数组的迭代
numpy. nditer ( op, flags=None, op_flags=None, op_dtypes=None, order = ‘K’, casting=‘safe’, op_axes=None, itershape=None, buffersize=0)
- op:要迭代的数组
- order:新数组元素排列样式,‘C’ - - 按行排列,‘F’ – 按列排列,‘A’ – 原顺序 ,‘K’ --按元素在内存中出现的顺序。
迭代器对象numpy. nditer ( )可以对数组中的每一个元素进行访问(一般结合 for 循环。)
运算
数组与标量的运算
相当于向量与标量的运算。
一元函数
import numpy as np
arr=np.random.uniform(-10,10,(3,4))
print(f'生成一个从-10到10呈正态分布的二维数组:\n{arr}')
print(f'数组的一元函数:操作时只需传入一个数组即可。')
print(f'求其绝对值:\n{np.abs(arr)}')
print(f'开跟,其中负数值开方变成 nan :\n{np.sqrt(arr)}')
print(f'平方:\n{np.square(arr)}')
print(f'朝着正无穷大的方向取整:\n{np.ceil(arr)}')
print(f'朝着负无穷大的方向取整:\n{np.floor(arr)}')
print(f'四舍五入:\n{np.round(arr)}')
decimals,integers=np.modf(arr)

二元函数

聚合函数
聚合函数对一组值执行计算并返回单一的值。
布尔运算
其它函数
- numpy. apply_along_axis(func1d, axis, arr, *args, **kwargs) - - - - - - - >ndarray
- *args, **kwargs:函数func1d的附加参数。
作用:沿着指定轴 axis 将函数应用于一维切片。
- numpy. (start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0) -> (tuple[Any, Any | float] | Any)
返回在[start,stop]间隔内计算的等距采样数。
可以选择排除间隔的端点。
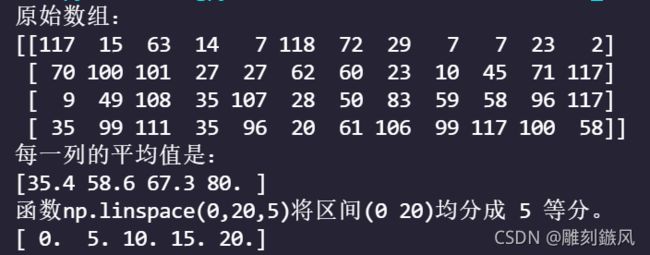
import numpy as np
arr=np.random.randint(0,120,(4,12))
print(f'原始数组:\n{arr}')
fun=lambda x:x[(x!=x.max()) & (x!=x.min())].mean()
avg=np.apply_along_axis(fun,axis=1,arr=arr)
print(f'每一列的平均值是:\n{avg}')
print(f'函数np.linspace(0,20,5)将区间(0 20)均分成 5 等分。')
print(np.linspace(0,20,5))
存取
数组读取与保存:
np. savetxt ( fname , X, fmt=’%.18e’ , delimiter=’ ’ , newline=’\n’,
header=’’, footer=’’, comments=’# ', encoding=None)
- fname:文件名称;
- X:数组名称;
- fmt:写入文件的格式;
- delimiter [dɪ’lɪmɪtə] :分隔符,默认空格
- header :数组的每列字段名称;
np. loadtxt ( fname, dtype=
, comments=’#’, delimiter = None , converters = None, skiprows = 0, usecols = None, unpack = False, ndmin = 0, encoding =‘bytes’, max_rows = None)
- dtype :以何种数据类型读取数据;
- frame:文件、字符串或产生器,可以是gz或bz2的压缩文件。
- dtype: 以何种数据类型读取数据;可选。
- delimiter:分割字符串,默认是任何空格。
- skiprows:跳过前面x行。
- usecols:读取指定的列,用元组组合。
- unpack:如果True,读取出来的数组是转置后的。
np独有的存储解决方案:
numpy中还有一种独有的存储解决方案。文件名是以npy或者npz结尾的。以下是存储和加载的函数。
1.存储: np.save(fname,array)或np.savez(fnamearray)。其中,前者函数的扩展名是npy ,后者的扩展名是npz,后者是经过压缩的。
2.加载: np.load(fname)。
总结:
- np.savetxt和np.loadtxt一般用来操作csv文件,他可以设置header,但是不能存储3维以上的数组。
- np.save和np.load一般用来存储非文本类型的文件,他不可以设置header,但是可以存储3维以上的数组
未完待续!!!