Prime Sample Attention in Object Detection
1.abstract
目标检测时需要用anchor从整张图片中获得样本,这些样本对改善网络模型的表现的重要性是不同的。所以,我们需要从所有的样本中采样。
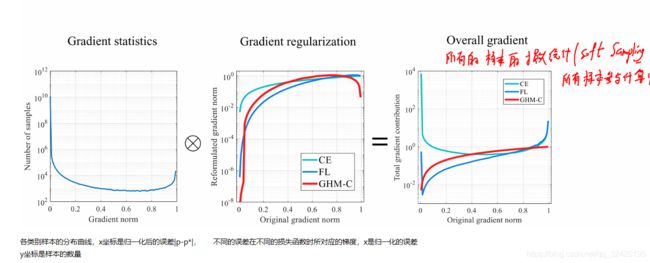
GHM中,样本对模型改善的作用可以从梯度体现。该类别样本的梯度越大,对模型的影响越大。
本文从常用的模型评估指标mAp的定义出发,指出了什么样的样本对提高模型的mAP比较重要。并提出了prime sample 的概念,并根据样本的重要性 指定该样本的损失的权重。 本文进一步在回归损失中加入了分类损失,回归质量好的,其分类损失也比较低,进一步强化了prime sample在优化模型时的作用。
2.introduction
目标检测器采样时,各个样本间并不是独立的,也不是平等重要的。OHEM倾向于采集困难样本(损失大的样本),但是OHEM中所采集到的样本的重要性时相同的。 一般来说,我们希望与ground_truth的IOU大的样本,应该分值较大(score:为正样本的概率),而不应该是所有的正样本(与ground_truth的IOU大于阈值的样本)的得分值相同(为正样本的概率相同)。
In general, it is more advisable for a detector to yield high scores on one bounding box around each object while ensuring all objects of interest are sufficiently covered, instead of trying to produce high scores for all positive samples, i.e. those that substantially overlap with objects
我们在正样本采样时,要采集IOU大的样本。
定位定的好的样本,我们希望它的置信度也更高。In particular, well located samples need to be well classified with high confidences
因此,本本文提出PISA软采样策略。 Prime samples:对改善网络的表现重要的样本。我们通过分析map的定义得到哪些样本时prime samples.
2 Related Work
在采集正样本时,OHEM和Focal loss更倾向困难样本(损失大的样本),但是有些IOU比较低的正样本损失大是合理的。而PISA根据IOU采样正样本,IOU大的样本对优化网络起到更大的作用。
IOU大(其为正样本的概率按理应该更大),但是损失大的样本,表明它们既是prime samples,又是hard samples,我们就一定要采样它们。
3 Prime Samples(什么样的样本叫做prime samples,什么样的样本会对改善map起到更大的作用 )
map的定义:
ap就是ROC曲线下的面积。在绘制ROC曲线时,检测框的置信度决定了该检测框是否被保留,该检测框与标注框的IOU决定了该检测框是否对应了真实目标,这两个方面都影响了TP,FP和Recall,Precision和ap.
根据map的定义,哪些正样本比较重要?关注IOU
在所有检测到的检测框中,和实际标注框的IOU最大的检测框最重要,因为它的IOU会直接影响recall(注意:NMS去掉多于的检测框是根据置信度来操作的);
The way that mAP works reveals two criteria on which positive samples are more important for an object detector. (1) Among all bounding boxes that overlap with a groundtruth object, the one with the highest IoU is the most important as its IoU value directly influences the recall. (2) Across all highest-IoU bounding boxes for different objects, the ones with higher IoUs are more important, as they are the last ones that fall below the IoU threshold θ as θ increases and thus have great impact on the overall precision.
根据map的定义,哪些负样本比较重要?关注得分
在负样本中,因为很多的负样本会通过NMS而去掉。所以,如果一个负样本旁边有个得分更高的样本,那么这个负样本就不重要,因为它会被NMS去掉。
. (1) among all negative samples within a local region, the one with the highest score is the most important. (2) Across all highest-score samples in different regions, the ones with higher scores are more important, because they are the first ones that decrease the precision
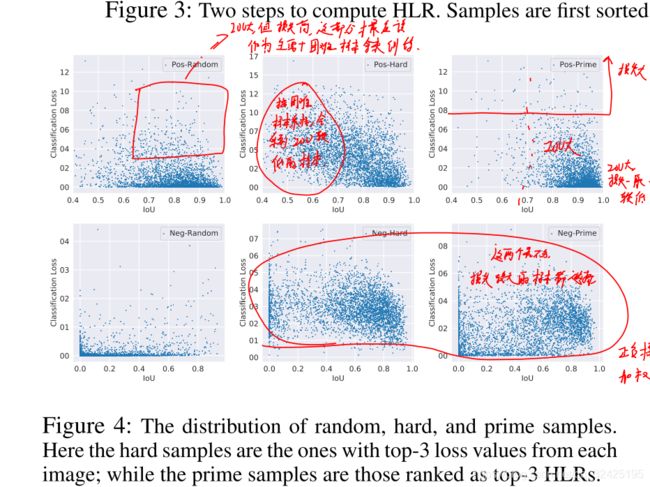
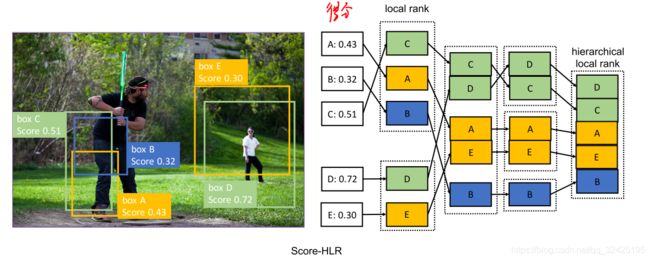
根据样本的重要性将样本分为各个级别Hierarchical Local Rank (HLR).:
正样本的分级方法是基于IOU的,所以成为IoU Hierarchical Local Rank (IoU-HLR)。负样本的分级方法是基于Score的,所以叫做Score Hierarchical Local Rank (Score-HLR)。
将正样本按IOU排序的步骤:IoU Hierarchical Local Rank (IoU-HLR)
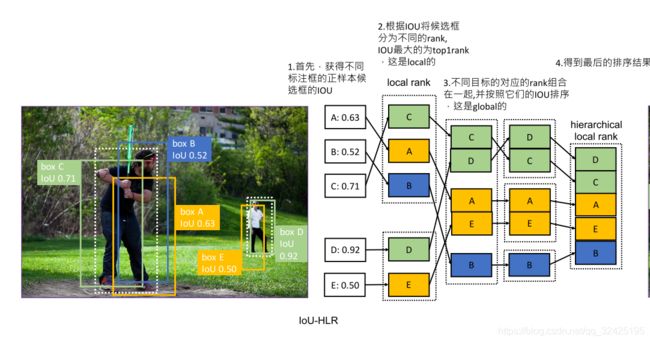
这样排序的原因:满足了上面的两个原则,同一目标,IOU最大的最重要;不同目标,IOU大的更重要
IoU-HLR遵循上述两个准则。首先,它将那些局部排序较高的样本放在前面,这些样本对于每一个单独的gt目标来说是最重要的。其次,在每个局部组内,根据IoU对样本进行重新排序,这符合第二个准则。
负样本按照score排序的步骤是类似的:

4.如何给prime samples更大的损失权重,让其主导模型的优化方向
(1)用IOU-HLR作为正样本重要性的评价,见上面。将样本的重要性量化
同一个rank中不同类别的样本有着相同的重要性

然后将样本的重要性体现在损失函数的权重上:
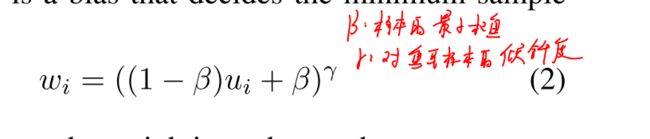
这样,修正后的损失函数变为
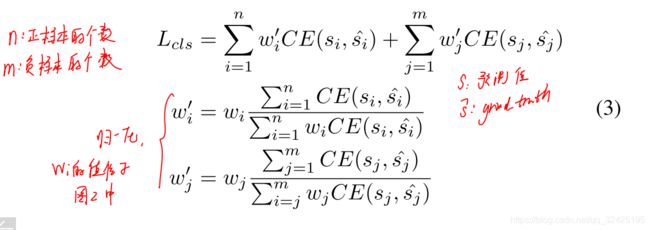
CARL(Classification-Aware Regression Loss):
Classification-Aware Regression Loss
受到分类和定位是相关的,由此受到启发,作者提出了另一种方法来关注主要样本。作者提出使用分类感知的回归损失(CARL)来联合优化分类和回归两个分支。CARL可以提升主要样本的分数,同时抑制其他样本的分数。回归质量决定了样本的重要性,我们期望分类器对重要样本输出更高的分数。两个分支的优化应该是相互关联的,而不是相互独立的。
参考https://zhuanlan.zhihu.com/p/63954517
总结
Focal Loss认为正负样本的不平衡,本质上是因为难易样本的不平衡,于是通过修改交叉熵,使得训练过程更加关注那些困难样本,而GHM在Focal Loss的基础上继续研究,发现难易样本的不平衡本质上是因为梯度范数分布的不平衡,和Focal Loss的最大区别是GHM认为最困难的那些样本应当认为是异常样本,让检测器强行去拟合异常样本对训练过程是没有帮助的。PISA则是跳出了Focal Loss的思路,认为采样策略应当从mAP这个指标出发,通过IoU Hierarchical Local Rank (IoU-HLR),对样本进行排序并权值重标定,从而使得recall和precision都能够提升。
我认为PISA的方法有一个问题,就是只考虑了IoU的排序,但是没有考虑到即使是相同IoU的样本的重要程度也是不相同的,比如有两个相同IoU的样本,一个位于目标的内部(如下图1),另一个没有在目标的内部(如下图2),显然第一个样本应当比第二个样本重要,如果后面要对PISA方法进行改进的话,可能需要引入一个有效主要样本的概念。
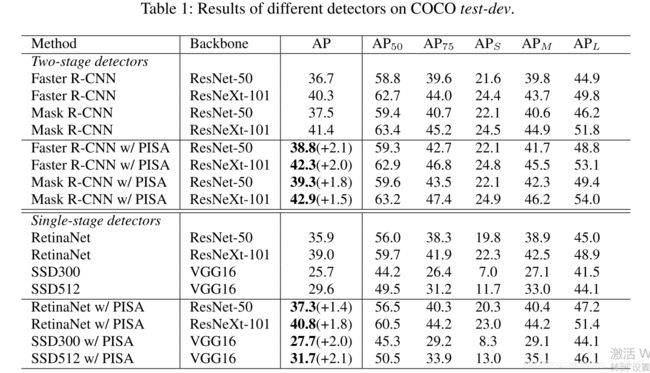
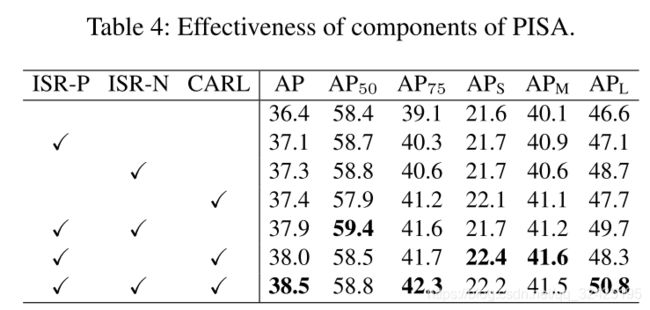
5.结果
使用PISA的软采样方法,会让结果提升,无伤涨点。
消融实验表明,ISP-P,ISP-A,CARL都有作用
6.实验分析
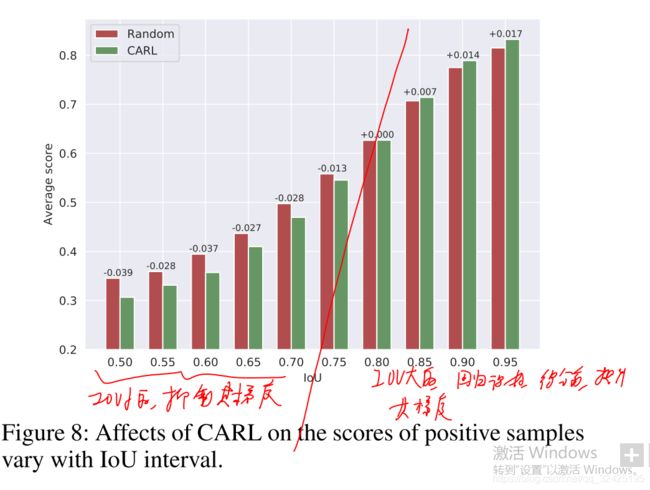
(1)正样本中,top rank的权重值变大,表明对模型的优化方向有更大的作用
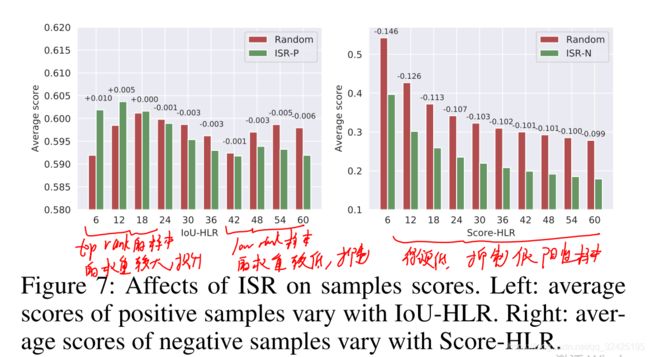
(2)CARL的作用:IOU大的样本对优化模型的作用提升