【论文阅读-3】生成模型——变分自编码器(Variational Auto-Encoder,VAE)
【论文阅读】生成模型——变分自编码器
- 1. VAE设计思路:从PCA到VAE
-
- 1.1 PCA
- 1.2 自编码器(Auto-Encoder, AE)
- 1.3 从AE到VAE
- 2. VAE模型框架
-
- 2.1 问题描述
- 2.2 变分下限
- 2.3 SGVB估计和AEVB算法
- 2.4 重参数化技巧(The reparameterization trick)
- 3. 变分自编码器(VAE)
-
- 3.1 VAE 基本流程
- 3.2 VAE 的对抗
- 4. 代码示例
-
- 4.1 编码器
- 4.2 解码器
- 4.3 整体待训练模型
- 4.4 训练
- 4.5 生成测试
- 参考:
1. VAE设计思路:从PCA到VAE
VAE最想解决的问题是如何构造编码器和解码器,使得图片能够编码成易于表示的形态,并且这一形态能够尽可能无损地解码回原真实图像。
1.1 PCA
这似乎听起来与PCA(主成分分析)有些相似,而PCA本身是用来做矩阵降维的:

如图:
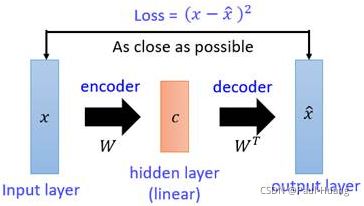
- X X X本身是一个矩阵,通过一个变换 W W W变成了一个低维矩阵 c c c;
- 因为这一过程是线性的,所以再通过一个 W ^ \hat{W} W^变换就能还原出一个 X ^ \hat{X} X^;
- 现在找到一种变换 W W W,使得矩阵 X X X与能够尽可能地一致,这就是PCA做的事情。
在PCA中找这个变换 W W W用到的方法是 S V D ( 奇 异 值 分 解 ) 算 法 \color{blue}SVD(奇异值分解)算法 SVD(奇异值分解)算法,在VAE/AE中不再需要使用SVD,直接用神经网络代替。
1.2 自编码器(Auto-Encoder, AE)
- PCA与想要构造的自编码器(AE)的相似之处是:如果把矩阵 X X X视作输入图像, W W W视作一个编码器,低维矩阵 c c c视作图像的编码,然后 W ^ \hat{W} W^和 X ^ \hat{X} X^分别视作解码器和生成图像,PCA就变成了一个自编码器(AE)网络模型的雏形。
- 对这一雏形进行改进。用神经网络代替 W W W变换和 W ^ \hat{W} W^变换,就得到了如下Deep Auto-Encoder模型:
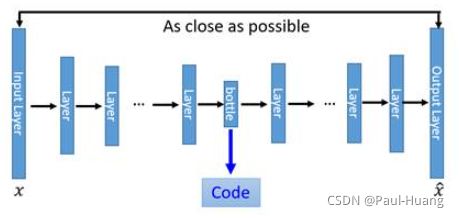
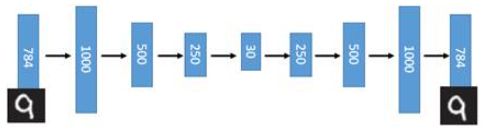
引入了神经网络强大的拟合能力,使得编码(Code)的维度能够比原始图像( X X X)的维度低非常多。在一个手写数字图像的生成模型中,Deep Auto-Encoder能够把一个784维的向量(28*28图像)压缩到只有30维,并且解码回的图像具备清楚的辨认度(如下图)。
1.3 从AE到VAE
- AE的缺陷
对于一个生成模型而言,解码器部分应该是单独能够提取出来的,并且对于在规定维度下 任 意 采 样 的 一 个 编 码 , 都 应 该 能 通 过 解 码 器 产 生 一 张 清 晰 且 真 实 的 图 片 \color{red}任意采样的一个编码,都应该能通过解码器产生一张清晰且真实的图片 任意采样的一个编码,都应该能通过解码器产生一张清晰且真实的图片。如下图,AE模型无法实现:

如上图所示,假设有两张训练图片,一张是全月图,一张是半月图,经过训练我们的自编码器模型已经能无损地还原这两张图片。接下来,我们在code空间上,两张图片的编码点中间处取一点,然后将这一点交给解码器,我们希望新的生成图片是一张清晰的图片(类似3/4全月的样子)。但是,实际的结果是,生成图片是模糊且无法辨认的乱码图。一个比较合理的解释是,因为编码和解码的过程使用了深度神经网络,这是一个非线性的变换过程,所以 在 c o d e 空 间 上 点 与 点 之 间 的 迁 移 是 非 常 没 有 规 律 \color{red}在code空间上点与点之间的迁移是非常没有规律 在code空间上点与点之间的迁移是非常没有规律。
- VAE的引入
如何解决上述问题呢?我们引入噪声,使得图片的编码区域得到扩大,从而掩盖掉失真的空白编码点。
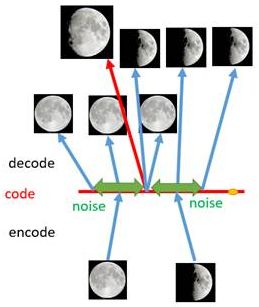
- 如上图所示,给两张图片编码的时候加上一点噪音,使得每张图片的编码点出现在 绿 色 箭 头 \color{green}绿色箭头 绿色箭头所示范围内,于是在训练模型的时候,绿色箭头范围内的点都有可能被采样到,这样解码器在训练时会把绿色范围内的点都尽可能还原成和原图相似的图片。
- 之前关注的失真点,现在它处于全月图和半月图编码的交界上,于是解码器希望它既要尽量相似于全月图,又要尽量相似于半月图,于是它的还原结果就是两种图的折中(3/4全月图)。
- 给编码器增添一些噪音,可以有效覆盖失真区域。不过这还并不充分,因为在上图的距离训练区域很远的 黄 色 点 处 \color{Chocolate}黄色点处 黄色点处,它依然不会被覆盖到,仍是个失真点。
- 为了解决上述问题,试图把噪音无限拉长,使得对于每一个样本,它的编码会 覆 盖 整 个 编 码 空 间 \color{red}覆盖整个编码空间 覆盖整个编码空间,不过我们得保证,在 原 编 码 附 近 编 码 的 概 率 最 高 , 离 原 编 码 点 越 远 , 编 码 概 率 越 低 \color{red}原编码附近编码的概率最高,离原编码点越远,编码概率越低 原编码附近编码的概率最高,离原编码点越远,编码概率越低。在这种情况下,图像的编码就由原先离散的编码点变成了一条 连 续 的 编 码 分 布 曲 线 \color{red}连续的编码分布曲线 连续的编码分布曲线,如下图所示。
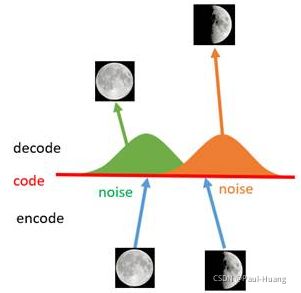
上述的这种 将 图 像 编 码 由 离 散 变 为 连 续 的 方 法 \color{red}将图像编码由离散变为连续的方法 将图像编码由离散变为连续的方法,就是 变 分 自 编 码 的 核 心 思 想 \color{red}变分自编码的核心思想 变分自编码的核心思想。
| 降维方法 | 线性 | 非线性 |
|---|---|---|
| 生成式 | 概率PCA | VAE |
| 非生成式 | PCA | AE |
2. VAE模型框架
2.1 问题描述
-
情况介绍
观测数据集 X = { x ( i ) } i = 1 N i . i . d X=\left\{ \mathtt{x}^{(i)} \right\}^N_{i=1} i.i.d X={x(i)}i=1Ni.i.d( X X X本身可能是连续分布或者离散分布),假设 X X X由隐变量 z \mathtt{z} z(unobserved continuous random variable)生成。此过程包含2个步骤:- 先 验 分 布 p θ ∗ ( z ) 生 成 一 个 z ( i ) \color{red}先验分布p_{\theta^*}(\mathtt{z})生成一个\mathtt{z}^{(i)} 先验分布pθ∗(z)生成一个z(i);
- 条 件 分 布 p θ ∗ ( x ∣ z ) 生 成 一 个 x ( i ) \color{red}条件分布p_{\theta^*}(\mathtt{x|z})生成一个\mathtt{x}^{(i)} 条件分布pθ∗(x∣z)生成一个x(i)。
假设 p θ ∗ ( z ) , p θ ∗ ( x ∣ z ) p_{\theta^*}(\mathtt{z}) ,p_{\theta^*}(\mathtt{x|z}) pθ∗(z),pθ∗(x∣z)来自 p θ ( z ) , p θ ( x ∣ z ) p_{\theta}(\mathtt{z}) ,p_{\theta}(\mathtt{x|z}) pθ(z),pθ(x∣z)函数族,并且它们的概率密度函数(PDF)几乎在 θ \theta θ和 z z z的任何地方都是可微的。这个过程中 真 正 的 参 数 θ ∗ \color{green}真正的参数\theta^* 真正的参数θ∗和 隐 变 量 z ( i ) \color{green}隐变量z^{(i)} 隐变量z(i)的值都是 未 知 的 \color{green}未知的 未知的。
-
存在问题
- 难处理性:
边际似然函数的积分 p θ ( x ) = ∫ p θ ( z ) p θ ( x ∣ z ) d z \color{blue}p_\theta {(\mathtt{x})}=\int_{}^{}{ p_\theta {(\mathtt{z})}p_\theta {(\mathtt{x|z})} dz} pθ(x)=∫pθ(z)pθ(x∣z)dz难以计算(没办法估计边际似然分布,因为其中的后验分布 p θ ( z ∣ x ) = p θ ( x ∣ z ) p θ ( z ) p θ ( x ) \color{blue}p_{\theta}(\mathtt{z|x})=\frac{p_{\theta}(\mathtt{x|z})p_{\theta}(\mathtt{z})}{p_{\theta}(\mathtt{x})} pθ(z∣x)=pθ(x)pθ(x∣z)pθ(z)难以计算,所以不能用EM算法)。mean-field所需要计算的积分也是难以处理的。 - A large dataset:
例如Monte Carlo EM算法,需要遍历所有数据进行采样,这样的代价过于高昂。
- 难处理性:
-
解决方法
可以有以下方法进行求解:- 对参数 θ \theta θ进行有效的ML或MAP近似;
- 给定观测值 x x x并选择一个参数 ϕ \phi ϕ,有效近似后验推断隐变量 z z z;
- 利用边际推断高效逼近 x x x。
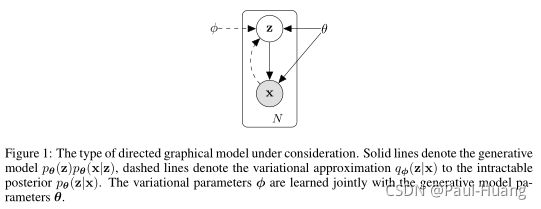
选择引入一个 生 成 模 型 q ϕ ( z ∣ x ) 来 逼 近 真 正 的 后 验 分 布 p θ ( z ∣ x ) \color{red}生成模型q_{\phi}(\mathtt{z}|\mathtt{x})来逼近真正的后验分布\color{red}p_{\theta}(\mathtt{z}|\mathtt{x}) 生成模型qϕ(z∣x)来逼近真正的后验分布pθ(z∣x),则:
- 将 q ϕ ( z ∣ x ) \color{red}q_{\phi}(\mathtt{z}|\mathtt{x}) qϕ(z∣x)看做 编 码 器 ( e n c o d e r ) \color{red}编码器(encoder) 编码器(encoder),编码器将产生一个高斯分布, z \mathtt{z} z可能的值可以覆盖 x \mathtt{x} x所有范围;
- 将 p θ ( x ∣ z ) \color{red}p_{\theta}(\mathtt{x}|\mathtt{z}) pθ(x∣z)看做 解 码 器 ( d e c o d e r ) \color{red}解码器(decoder) 解码器(decoder), z \mathtt{z} z将产生一个关于分布 x \mathtt{x} x的值的可能性的分布。
VAE的核心在于 使 用 一 个 q ϕ ( z ∣ x ) 来 对 真 实 的 后 验 概 率 分 布 p θ ( x ∣ z ) 进 行 估 计 \color{red}使用一个q_{\phi}(\mathtt{z}|\mathtt{x})来对真实的后验概率分布p_{\theta}(\mathtt{x}|\mathtt{z})进行估计 使用一个qϕ(z∣x)来对真实的后验概率分布pθ(x∣z)进行估计。
2.2 变分下限
变分推断中常用的方法是求观察量 x x x的似然函数:
log p θ ( x ( 1 ) , x ( 2 ) , . . . , x ( N ) ) = ∑ i = 1 N log p θ ( x ( i ) ) (2.2.1) \log p_\theta(\mathtt{x}^{(1)},\mathtt{x}^{(2)},...,\mathtt{x}^{(N)})=\sum_{i=1}^{N}{\log p_{\theta}(\mathtt{x}^{(i)}})\tag{2.2.1} logpθ(x(1),x(2),...,x(N))=i=1∑Nlogpθ(x(i))(2.2.1)
每个 x ( i ) \mathtt{x}^{(i)} x(i)可以写成:
log p θ ( x ( i ) ) = log p θ ( x ( i ) , z ) − log p θ ( z ∣ x ( i ) ) = log p θ ( x ( i ) , z ) q ϕ ( z ∣ x ( i ) ) − log p θ ( z ∣ x ( i ) ) q ϕ ( z ∣ x ( i ) ) ( q ϕ ( z ∣ x ( i ) ) ≠ 0 ) . (2.2.2) \begin{aligned}\log\; p_{\theta}(\mathtt{x}^{(i)} )&=\log\; p_{\theta }(\mathtt{x}^{(i)},\mathtt{z})- \log\; p_{\theta }(\mathtt{z}|\mathtt{x}^{(i)})\\ &=\log\; \frac{p_{\theta }(\mathtt{x}^{(i)},\mathtt{z})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}-\log\; \frac{p_{\theta }(\mathtt{z}|\mathtt{x}^{(i)})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}\; \; (q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})\neq 0).\end{aligned}\tag{2.2.2} logpθ(x(i))=logpθ(x(i),z)−logpθ(z∣x(i))=logqϕ(z∣x(i))pθ(x(i),z)−logqϕ(z∣x(i))pθ(z∣x(i))(qϕ(z∣x(i))=0).(2.2.2)
(2.2.2)式两边对 q ϕ ( z ∣ x ( i ) ) q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)}) qϕ(z∣x(i))求期望得:
log p θ ( x ( i ) ) = D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ∣ x ( i ) ) ) + L ( θ , ϕ ; x ( i ) ) (2.2.3) \log p_\theta(\mathtt{x}^{(i)})=D_{KL}{(q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})||p_{\theta }(\mathtt{z}|\mathtt{x}^{(i)}))}+\mathcal{L}(\theta,\phi;\mathtt{x}^{(i)})\tag{2.2.3} logpθ(x(i))=DKL(qϕ(z∣x(i))∣∣pθ(z∣x(i)))+L(θ,ϕ;x(i))(2.2.3)
其中:
{ L ( θ , ϕ ; x ( i ) ) = ∫ z q ϕ ( z ∣ x ( i ) ) log p θ ( z , x ( i ) ) q ϕ ( z ∣ x ( i ) ) d z D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ∣ x ( i ) ) ) = − ∫ z q ϕ ( z ∣ x ( i ) ) log p θ ( z ∣ x ( i ) ) q ϕ ( z ∣ x ( i ) ) d z \color{blue}\{ \begin{aligned} \mathcal{L}(\theta,\phi;\mathtt{x}^{(i)})&=\int_z q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)}) \log\ \frac{p_{\theta }(\mathtt{z},\mathtt{x}^{(i)})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}dz\\ D_{KL}{(q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})||p_{\theta }(\mathtt{z}|\mathtt{x}^{(i)}))}&= - \int_z q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})\log\ \frac{p_{\theta }(\mathtt{z}|\mathtt{x}^{(i)})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}dz \end{aligned} {L(θ,ϕ;x(i))DKL(qϕ(z∣x(i))∣∣pθ(z∣x(i)))=∫zqϕ(z∣x(i))log qϕ(z∣x(i))pθ(z,x(i))dz=−∫zqϕ(z∣x(i))log qϕ(z∣x(i))pθ(z∣x(i))dz
公式(2.2.3)可以描述成:
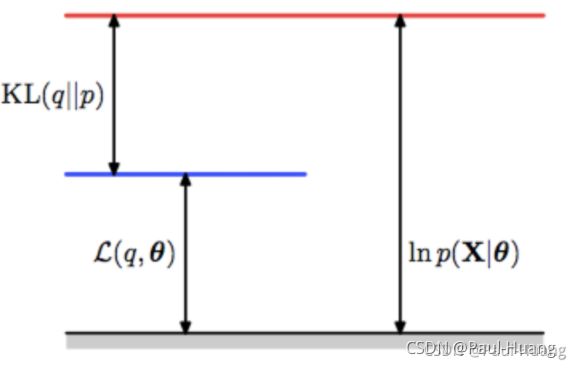
根据KL散度的定义, D K L ≥ 0 D_{KL}\geq 0 DKL≥0( L ( θ , ϕ ; x ( i ) ) \mathcal{L}(\theta,\phi;\mathtt{x}^{(i)}) L(θ,ϕ;x(i))成为lower bound),因此:
log p θ ( x ( i ) ) ≥ L ( θ , ϕ ; x ( i ) ) = E q ϕ ( z ∣ x ( i ) ) [ − log q ϕ ( z ∣ x ( i ) ) + log p θ ( x ( i ) , z ) ] (2.2.4) \color{red}\log p_\theta(\mathtt{x}^{(i)})\geq \mathcal{L}(\theta,\phi;\mathtt{x}^{(i)}) = \mathbb{E}_{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}[-\log q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})+\log p_{\theta }(\mathtt{x}^{(i)},\mathtt{z})]\tag{2.2.4} logpθ(x(i))≥L(θ,ϕ;x(i))=Eqϕ(z∣x(i))[−logqϕ(z∣x(i))+logpθ(x(i),z)](2.2.4)
公式(2.2.4)还能写成:
L ( θ , ϕ ; x ( i ) ) = ∑ z q ϕ ( z ∣ x ( i ) ) log ( p θ ( z , x ( i ) ) q ϕ ( z ∣ x ( i ) ) ) = ∑ z q ϕ ( z ∣ x ( i ) ) log ( p θ ( x ( i ) ∣ z ) p θ ( z ) q ϕ ( z ∣ x ( i ) ) ) = ∑ z q ϕ ( z ∣ x ( i ) ) [ log ( p θ ( x ( i ) ∣ z ) ) + log ( p θ ( z ) q ϕ ( z ∣ x ( i ) ) ) ] = − D K L ( q ϕ ( z ∣ x ( i ) ) ∣ ∣ p θ ( z ) ) + E q ϕ ( z ∣ x ( i ) ) [ log p θ ( x ( i ) ∣ z ) ] (2.2.5) \begin{aligned}\color{red}\mathcal{L}(\theta,\phi;\mathtt{x}^{(i)}) &=\sum_{\mathbf{z}} q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)}) \log \left(\frac{p_{\theta}(\mathbf{z},\mathbf{x}^{(i)})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}\right)=\sum_{\mathtt{z}} q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)}) \log \left(\frac{p_{\theta}(\mathtt{x}^{(i)}| \mathtt{z}) p_{\theta}(\mathtt{z})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}\right) \\ &=\sum_{\mathbf{z}} q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})\left[\log \left(p_{\theta }(\mathtt{x}^{(i)}|\mathtt{z})\right)+\log \left(\frac{p_{\theta}(\mathbf{z})}{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}\right)\right] \\ &\color{red}= -D_{KL}(q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})||p_{\theta}(\mathtt{z}))+ \mathbb{E}_{q_{\phi}(\mathtt{z}|\mathtt{x}^{(i)})}[\log p_{\theta }(\mathtt{x}^{(i)}|\mathtt{z})]\end{aligned}\tag{2.2.5} L(θ,ϕ;x(i))=z∑qϕ(z∣x(i))log(qϕ(z∣x(i))pθ(z,x(i)))=z∑qϕ(z∣x(i))log(qϕ(z∣x(i))pθ(x(i)∣z)pθ(z))=z∑qϕ(z∣x(i))[log(pθ(x(i)∣z))+log(qϕ(z∣x(i))pθ(z))]=−DKL(qϕ(z∣x(i))∣∣pθ(z))+Eqϕ(z∣x(i))[logpθ(x(i)∣z)](2.2.5)
-
对带有变分参数 ϕ \phi ϕ和生成参数 θ \theta θ的 L ( θ , ϕ ; x ( i ) ) \mathcal{L}(\theta,\phi;\mathtt{x}^{(i)}) L(θ,ϕ;x(i))求导,就是对公式(2.2.5)求导,来优化 L ( θ , ϕ ; x ( i ) ) \mathcal{L}(\theta,\phi;\mathtt{x}^{(i)}) L(θ,ϕ;x(i)),从而达到求解 log p θ ( x ( i ) ) \log p_\theta(\mathtt{x}^{(i)}) logpθ(x(i));
-
但是计算 L ( θ , ϕ ; x ( i ) ) \mathcal{L}(\theta,\phi;\mathtt{x}^{(i)}) L(θ,ϕ;x(i))的梯度十分困难,若用 蒙 特 卡 洛 方 法 来 估 计 \color{red}蒙特卡洛方法来估计 蒙特卡洛方法来估计(令公式(2.2.4)或公式(2.2.5)中中括号里面的函数为 f ( z ) f(\mathbf{z}) f(z)),其形式如下:
∇ ϕ E q ϕ ( z ) [ f ( z ) ] = E q ϕ ( z ) [ f ( z ) ∇ q ϕ ( z ) log q ϕ ( z ) ] ≃ 1 L ∑ l = 1 L f ( z ) ∇ q ϕ ( z ( l ) ) log q ϕ ( z ( l ) ) w h e r e z ( l ) ∼ q ϕ ( z ∣ x ( i ) ) (2.2.6) \begin{aligned}\nabla_{\phi} \mathbb{E}_{q_{\phi}(\mathbf{z})}[f(\mathbf{z})]&=\mathbb{E}_{q_{\phi}(\mathbf{z})}\left[f(\mathbf{z}) \nabla_{q_{\phi}(\mathbf{z})} \log q_{\phi}(\mathbf{z})\right] \simeq \frac{1}{L} \sum_{l=1}^{L} f(\mathbf{z}) \nabla_{q_{\phi}\left(\mathbf{z}^{(l)}\right)} \log q_{\phi}\left(\mathbf{z}^{(l)}\right)\\ &where\;\; \mathbf{z}^{(l)}\sim q_{\phi}\left(\mathbf{z}| \mathbf{x}^{(i)}\right) \end{aligned}\tag{2.2.6} ∇ϕEqϕ(z)[f(z)]=Eqϕ(z)[f(z)∇qϕ(z)logqϕ(z)]≃L1l=1∑Lf(z)∇qϕ(z(l))logqϕ(z(l))wherez(l)∼qϕ(z∣x(i))(2.2.6)
L L L为蒙塔卡罗方法的采样个数。推导过程参考:https://arxiv.org/abs/1906.10652
此 方 法 计 算 方 差 特 别 大 , 对 目 的 求 解 是 不 合 适 \color{red}此方法计算方差特别大,对目的求解是不合适 此方法计算方差特别大,对目的求解是不合适。
2.3 SGVB估计和AEVB算法
-
重参数化技巧
∇ ϕ E q ϕ ( z ) [ f ( z ) ] \nabla_{\phi} \mathbb{E}_{q_{\phi}(\mathbf{z})}[f(\mathbf{z})] ∇ϕEqϕ(z)[f(z)]难以计算梯度(公式(2.2.6))的主要原因是:
公 式 ( 2.2.4 ) 中 q ϕ ( z ) 中 ϕ 是 未 知 数 , 也 需 要 求 导 , 使 得 很 难 计 算 。 因 此 , 此 处 我 们 使 用 重 参 数 化 技 巧 ( r e p a r a m e t e r i z a t i o n t r i c k ) ! \color{red}公式(2.2.4)中q_{\phi}(\mathbf{z})中\phi 是未知数,也需要求导,使得很难计算。\\因此,此处我们使用重参数化技巧(reparameterization\;trick)! 公式(2.2.4)中qϕ(z)中ϕ是未知数,也需要求导,使得很难计算。因此,此处我们使用重参数化技巧(reparameterizationtrick)!
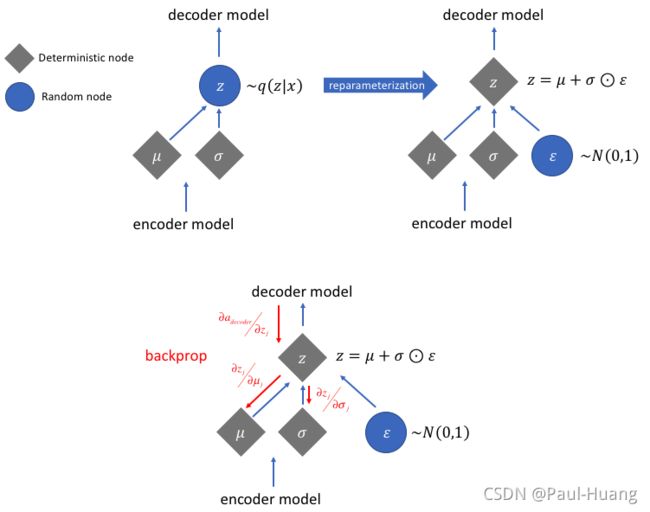
引入 噪 声 变 量 ( 一 般 符 合 高 斯 分 布 ) ϵ \color{green}噪声变量(一般符合高斯分布)\epsilon 噪声变量(一般符合高斯分布)ϵ和 分 布 转 换 函 数 g ϕ ( ϵ , x ) \color{green}分布转换函数g_{\phi}(\mathbf{\epsilon},\mathbf{x}) 分布转换函数gϕ(ϵ,x)重写 z \color{green}\mathbf{z} z这个隐藏变量 z ~ ∼ q ϕ ( z ∣ x ) \color{green}\tilde{\mathbf{z}}\sim q_{\phi}(\mathbf{z}|\mathbf{x}) z~∼qϕ(z∣x):
z ~ = g ϕ ( ϵ , x ) w i t h ϵ ∼ p ( ϵ ) (2.3.1) \color{red}\tilde{\mathbf{z}}=g_\phi(\epsilon,\mathbf{x}) \; with \; \epsilon\sim p(\epsilon)\tag{2.3.1} z~=gϕ(ϵ,x)withϵ∼p(ϵ)(2.3.1)下图给出了重参数技巧的作用:
在下一节(2.4节)会具体说重参数化技巧(如何选择一个合适的分布 p ( ϵ ) p(\epsilon) p(ϵ)和函数 g ϕ ( ϵ , x ) g_{\phi}(\epsilon, x) gϕ(ϵ,x))。现在 用 蒙 特 卡 洛 估 计 重 写 E q ϕ ( z ∣ x ( i ) ) [ f ( z ) ] \color{blue}用蒙特卡洛估计重写\mathbb{E}_{q_{\phi}(\mathbf{z}|\mathbf{x}^{(i)})}[f(\mathbf{z})] 用蒙特卡洛估计重写Eqϕ(z∣x(i))[f(z)](其中 f ( z ) f(\mathbf{z}) f(z)代指一些特殊的函数,例如 q ϕ ( z ∣ x ) q_{\phi}(\mathbf{z}|\mathbf{x}) qϕ(z∣x),等式最右边可以理解为分成 L L L分然后进行采样):
E q ϕ ( z ∣ x ( i ) ) [ f ( z ) ] = E p ( ϵ ) [ f ( g ϕ ( ϵ , x ( i ) ) ) ] ≃ 1 L ∑ l = 1 L f ( g ϕ ( ϵ ( l ) , x ( i ) ) ) where ϵ ( l ) ∼ p ( ϵ ) (2.3.2) \color{blue}\begin{aligned}\mathbb{E}_{q_{\phi}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right)}[f(\mathbf{z})]=&\mathbb{E}_{p(\epsilon)}\left[f\left(g_{\phi}\left(\boldsymbol{\epsilon}, \mathbf{x}^{(i)}\right)\right)\right] \simeq \frac{1}{L} \sum_{l=1}^{L} f\left(g_{\phi}\left(\boldsymbol{\epsilon}^{(l)}, \mathbf{x}^{(i)}\right)\right) \\ &\text { where } \quad \epsilon^{(l)} \sim p(\boldsymbol{\epsilon})\end{aligned}\tag{2.3.2} Eqϕ(z∣x(i))[f(z)]=Ep(ϵ)[f(gϕ(ϵ,x(i)))]≃L1l=1∑Lf(gϕ(ϵ(l),x(i))) where ϵ(l)∼p(ϵ)(2.3.2) -
第一种形式随机梯度变分贝叶斯(SGVB)
利用公式(2.3.2)求解 公 式 ( 2.2.4 ) \color{green}公式(2.2.4) 公式(2.2.4)得 L ~ A ( θ , ϕ ; x ( i ) ) ≃ L ( θ , ϕ ; x ( i ) ) \color{red}\widetilde{\mathcal{L}}^{A}\left(\boldsymbol{\theta}, \phi ; \mathbf{x}^{(i)}\right) \simeq \mathcal{L}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) L A(θ,ϕ;x(i))≃L(θ,ϕ;x(i)),其中:
L ~ A ( θ , ϕ ; x ( i ) ) = 1 L ∑ l = 1 L log p θ ( x ( i ) , z ( i , l ) ) − log q ϕ ( z ( i , l ) ∣ x ( i ) ) where z ( i , l ) = g ϕ ( ϵ ( i , l ) , x ( i ) ) and ϵ ( l ) ∼ p ( ϵ ) (2.3.3) \color{red}\begin{aligned} &\widetilde{\mathcal{L}}^{A}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right)=\frac{1}{L} \sum_{l=1}^{L} \log p_{\theta}\left(\mathbf{x}^{(i)}, \mathbf{z}^{(i, l)}\right)-\log q_{\phi}\left(\mathbf{z}^{(i, l)} \mid \mathbf{x}^{(i)}\right) \\ &\text { where } \quad \mathbf{z}^{(i, l)}=g_{\phi}\left(\boldsymbol{\epsilon}^{(i, l)}, \mathbf{x}^{(i)}\right) \quad \text { and } \quad \boldsymbol{\epsilon}^{(l)} \sim p(\boldsymbol{\epsilon}) \end{aligned}\tag{2.3.3} L A(θ,ϕ;x(i))=L1l=1∑Llogpθ(x(i),z(i,l))−logqϕ(z(i,l)∣x(i)) where z(i,l)=gϕ(ϵ(i,l),x(i)) and ϵ(l)∼p(ϵ)(2.3.3)i i i表示数据 X X X的第 i i i个样本, l l l表示蒙特卡洛采样总是 L L L的第 l l l个采样点。
-
第二种形式随机梯度变分贝叶斯(SGVB)
利用公式(2.3.2)求解 公 式 ( 2.2.5 ) \color{green}公式(2.2.5) 公式(2.2.5)得 L ~ B ( θ , ϕ ; x ( i ) ) ≃ L ( θ , ϕ ; x ( i ) ) \color{red}\widetilde{\mathcal{L}}^{B}\left(\boldsymbol{\theta}, \phi ; \mathbf{x}^{(i)}\right) \simeq \mathcal{L}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) L B(θ,ϕ;x(i))≃L(θ,ϕ;x(i)),其中:
L ~ B ( θ , ϕ ; x ( i ) ) = − D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) ⏟ R e g u l a r i z a t i o n L o s s + 1 L ∑ l = 1 L ( log p θ ( x ( i ) ∣ z ( i , l ) ) ) ⏟ R e c o n s t r u c t i o n L o s s w h e r e z ( i , l ) = g ϕ ( ϵ ( i , l ) , x ( i ) ) a n d ϵ ( l ) ∼ p ( ϵ ) (2.3.4) \color{red}\begin{aligned}&\widetilde{\mathcal{L}}^{B}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right)=\underbrace{-D_{K L}\left(q_{\phi}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right) \| p_{\boldsymbol{\theta}}(\mathbf{z})\right)}_{Regularization\;Loss}+\underbrace{\frac{1}{L} \sum_{l=1}^{L}\left(\log p_{\boldsymbol{\theta}}\left(\mathbf{x}^{(i)} \mid \mathbf{z}^{(i, l)}\right)\right)}_{Reconstruction\;Loss}\\ &where \quad \mathbf{z}^{(i, l)}=g_{\phi}\left(\boldsymbol{\epsilon}^{(i, l)}, \mathbf{x}^{(i)}\right) \quad and \quad \boldsymbol{\epsilon}^{(l)} \sim p(\boldsymbol{\epsilon})\end{aligned}\tag{2.3.4} L B(θ,ϕ;x(i))=RegularizationLoss −DKL(qϕ(z∣x(i))∥pθ(z))+ReconstructionLoss L1l=1∑L(logpθ(x(i)∣z(i,l)))wherez(i,l)=gϕ(ϵ(i,l),x(i))andϵ(l)∼p(ϵ)(2.3.4)对于公式(2.3.4):
- 第一项( z 先验分布 \color{green}z\text{先验分布} z先验分布和 给 定 x 的 z 的 后 验 分 布 \color{green}给定x的z的后验分布 给定x的z的后验分布的 K L 散 度 \color{green}KL散度 KL散度)充当 正 则 项 \color{blue}正则项 正则项,第二项是 自 动 编 码 的 期 望 重 构 误 差 的 负 数 \color{blue}自动编码的期望重构误差的负数 自动编码的期望重构误差的负数。
- 函数 g ϕ ( . ) \color{green}g_\phi(.) gϕ(.)是事先选择使得他能够映射数据集 x ( i ) \color{green}\mathbf{x}^{(i)} x(i)和随机噪声 ϵ \color{green}\epsilon ϵ到 z \color{green}\mathbf{z} z的后验分布(也就是 z ( i , l ) ∼ q ϕ ( z ∣ x ) \mathbf{z}^{(i,l)}\sim q_{\phi}(\mathbf{z}|\mathbf{x}) z(i,l)∼qϕ(z∣x))的一次采样,即:
z ( i , l ) = g ϕ ( ϵ ( l ) , x ( i ) ) \color{blue}{\mathbf{z}}^{(i,l)}=g_\phi(\epsilon^{(l)},\mathbf{x}^{(i)}) z(i,l)=gϕ(ϵ(l),x(i)) - 然后, z ( i , l ) \color{green}{\mathbf{z}}^{(i,l)} z(i,l)带入 log p ( x ( i ) ∣ z ( i , l ) ) \color{green}\log p(\mathbf{x}^{(i)}|\mathbf{z}^{(i,l)}) logp(x(i)∣z(i,l)) ,也就是该生成模型的 x ( i ) 的 似 然 函 数 \color{blue}\mathbf{x}^{(i)}的似然函数 x(i)的似然函数,这一项也是自动编码的重构误差的负数。
数据集 X \mathbf{X} X(一共 N \color{green}N N个),如果采用minibatch(一个batch M \color{green}M M个数据),可以通过下面的方式进行估计:
L ( θ , ϕ ; X ) ≃ L ~ M ( θ , ϕ ; X M ) = N M ∑ i = 1 M L ~ ( θ , ϕ ; x ( i ) ) (2.3.5) \color{red}\mathcal{L}(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{X}) \simeq \widetilde{\mathcal{L}}^{M}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{X}^{M}\right)=\frac{N}{M} \sum_{i=1}^{M} \widetilde{\mathcal{L}}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right)\tag{2.3.5} L(θ,ϕ;X)≃L M(θ,ϕ;XM)=MNi=1∑ML (θ,ϕ;x(i))(2.3.5)- 作者的实验证明:如果minibatch足够大(例如 M = 100 \color{blue}M=100 M=100),那么公式(2.3.4)中的 L ~ B ( θ , ϕ ; x ( i ) ) \color{red}\widetilde{\mathcal{L}}^{B}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) L B(θ,ϕ;x(i))函数当中的第二项 L \color{red}L L可以取 1 \color{red}1 1。
- L ~ ( θ , ϕ ; x ( i ) ) \color{blue}\widetilde{\mathcal{L}}(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}) L (θ,ϕ;x(i))可以取 L ~ A ( θ , ϕ ; x ( i ) ) \color{blue}\widetilde{\mathcal{L}}^{A}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) L A(θ,ϕ;x(i))(公式(2.3.3))或者 L ~ B ( θ , ϕ ; x ( i ) ) \color{blue}\widetilde{\mathcal{L}}^{B}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) L B(θ,ϕ;x(i))(公式(2.3.4))。
-
SGVB算法的一般流程

2.4 重参数化技巧(The reparameterization trick)
-
重参数化技巧的目的是: 将 随 机 变 量 中 的 随 机 性 与 数 据 正 式 信 息 解 耦 \color{red}将随机变量中的随机性与数据正式信息解耦 将随机变量中的随机性与数据正式信息解耦。
-
在上一节(2.3节)中,我们使用:
ϵ ∼ p ( ϵ ) ( R 1 ) z = g ϕ ( ϵ , x ) ( R 2 ) ⇒ E p ϕ ( z ) [ f ( z ( i ) ) ] = E p ( ϵ ) [ f ( g ϕ ( ϵ , x ( i ) ) ) ] ( R 3 ) ⇒ ∇ ϕ E p ϕ ( z ) [ f ( z ( i ) ) ] = ∇ ϕ E p ( ϵ ) [ f ( g ϕ ( ϵ , x ( i ) ) ) ] ( a ) = E p ( ϵ ) [ ∇ ϕ f ( g ϕ ( ϵ , x ( i ) ) ) ] ( b ) ≈ 1 L ∑ l = 1 L ∇ ϕ f ( g ϕ ( ϵ ( l ) , x ( i ) ) ) ( c ) \begin{aligned} \boldsymbol{\epsilon} \sim p(\boldsymbol{\epsilon})&\;\;\;(R1)\\ \boldsymbol{z} =g_{\phi}(\boldsymbol{\epsilon}, \boldsymbol{x})&\;\;\;(R2)\\ \Rightarrow \mathbb{E}_{p_{\phi}(z)}\left[f\left(\boldsymbol{z}^{(i)}\right)\right] =\mathbb{E}_{p(\epsilon)}\left[f\left(g_{\phi}\left(\boldsymbol{\epsilon}, \boldsymbol{x}^{(i)}\right)\right)\right]&\;\;\;(R3)\\ \Rightarrow \nabla_{\phi} \mathbb{E}_{p_{\phi}(z)}\left[f\left(\boldsymbol{z}^{(i)}\right)\right] =\nabla_{\phi} \mathbb{E}_{p(\epsilon)}\left[f\left(g_{\phi}\left(\boldsymbol{\epsilon}, \boldsymbol{x}^{(i)}\right)\right)\right]&\;\;\;(a)\\ =\mathbb{E}_{p(\epsilon)}\left[\nabla_{\phi} f\left(g_{\phi}\left(\boldsymbol{\epsilon}, \boldsymbol{x}^{(i)}\right)\right)\right]&\;\;\;(b)\\ \approx \frac{1}{L} \sum_{l=1}^{L} \nabla_{\phi} f\left(g_{\phi}\left(\boldsymbol{\epsilon}^{(l)}, \boldsymbol{x}^{(i)}\right)\right)&\;\;\;(c) \end{aligned} ϵ∼p(ϵ)z=gϕ(ϵ,x)⇒Epϕ(z)[f(z(i))]=Ep(ϵ)[f(gϕ(ϵ,x(i)))]⇒∇ϕEpϕ(z)[f(z(i))]=∇ϕEp(ϵ)[f(gϕ(ϵ,x(i)))]=Ep(ϵ)[∇ϕf(gϕ(ϵ,x(i)))]≈L1l=1∑L∇ϕf(gϕ(ϵ(l),x(i)))(R1)(R2)(R3)(a)(b)(c)
其中:- R1和R2是重参数化技巧的通用步骤: 将 随 机 变 量 z 中 的 随 机 性 与 数 据 正 式 信 息 解 耦 \color{blue}将随机变量z中的随机性与数据正式信息解耦 将随机变量z中的随机性与数据正式信息解耦。
- R3的话是将R2代入原先无法求梯度的期望后的结果,核心点在于 期 望 对 象 的 变 化 \color{blue}期望对象的变化 期望对象的变化。
- 通过a/b/c步运算以后,我们可以将期望的梯度,转换成梯度的期望,并使用Monte Carlo方法进行近似求解。
-
重参数技巧:
- 易处理累积分布函数(CDF)的逆;例如:Exponential, Cauchy, Logistic, Rayleigh, Pareto, Weibull, Reciprocal,Gompertz, Gumbel and Erlang distributions.
- 对于任何“位置-尺度”分布族,都可以选择标准分布(位置= 0,尺度= 1)作为辅助变量 ϵ \epsilon ϵ, 让 g ( . ) = location + scale ⋅ ϵ g(.) =\text{location}+\text{scale}\cdot \epsilon g(.)=location+scale⋅ϵ。例如:Laplace, Elliptical, Student’s t, Logistic,Uniform, Triangular and Gaussian distributions.
- 通常可以将随机变量表示为辅助变量的不同变换。例如:Log-Normal (exponentiation of normally distributed variable), Gamma (a sum over exponentially distributed variables), Dirichlet (weighted sum of Gamma variates), Beta, Chi-Squared, and F distributions.
当这三种方法都失败时,逆CDF的良好逼近需要与PDF相当的时间复杂度的计算。
3. 变分自编码器(VAE)
3.1 VAE 基本流程
本部分用神经网络对概率编码器 q ϕ ( z ∣ x ) q_{\phi}(\mathbf{z}|\mathbf{x}) qϕ(z∣x)和利用AEVB优化参数 ϕ \phi ϕ和 θ \theta θ.
-
设隐变量的分布为 p θ ( z ) = N ( z ; 0 , I ) \color{green}p_{\theta}(\mathbf{z})=\mathcal{N}(\mathbf{z};\mathbf{0},\mathbf{I}) pθ(z)=N(z;0,I),则变分近似后验具有对角协方差结构的多元高斯:
log q ϕ ( z ∣ x ( i ) ) = log N ( z ; μ ( i ) , σ 2 ( i ) I ) (3.1.1) \color{red}\log q_{\phi}(\boldsymbol{z}|\boldsymbol{x}^{(i)}) = \log \mathcal{N}(\boldsymbol{z} ;\boldsymbol{\mu}^{(i)},\boldsymbol{\sigma}^{2(i)}\boldsymbol{I})\tag{3.1.1} logqϕ(z∣x(i))=logN(z;μ(i),σ2(i)I)(3.1.1)
则 先 验 概 率 p θ ( z ) 和 q ϕ ( z ∣ x ) 都 是 高 斯 分 布 \color{red}先验概率p_{\theta}(\mathbf{z})和q_{\phi}(\mathbf{z}|\mathbf{x})都是高斯分布 先验概率pθ(z)和qϕ(z∣x)都是高斯分布。上述公式可知:每一个 x ( i ) \boldsymbol{x}^{(i)} x(i)都配上了一个专属的正态分布。正态分布有两组参数:均值 μ ( i ) \boldsymbol{\mu}^{(i)} μ(i)和方差 σ ( i ) 2 \boldsymbol{\sigma^{(i)}}^2 σ(i)2(多元的话,它们都是向量),用神经网络来拟合出来! -
根据重参数化技巧:引入 噪 声 变 量 ( 一 般 符 合 高 斯 分 布 ) ϵ \color{green}噪声变量(一般符合高斯分布)\epsilon 噪声变量(一般符合高斯分布)ϵ和 分 布 转 换 函 数 g ϕ ( ϵ , x ) \color{green}分布转换函数g_{\phi}(\mathbf{\epsilon},\mathbf{x}) 分布转换函数gϕ(ϵ,x)重写 z \color{green}\mathbf{z} z这个隐藏变量 z ( i , l ) ∼ q ϕ ( z ∣ x ( i ) ) \color{green}{\mathbf{z}^{(i,l)}}\sim q_{\phi}(\mathbf{z}|\mathbf{x}^{(i)}) z(i,l)∼qϕ(z∣x(i)):
z ( i , l ) = g ϕ ( x ( i ) , ϵ ( l ) ) = μ ( i ) + σ ( i ) ⊙ ϵ ( l ) w i t h ϵ ∼ N ( 0 , I ) (3.1.2) \color{red}\begin{aligned}\mathbf{z}^{(i,l)}=&g_\phi(\mathbf{x}^{(i)},\epsilon^{(l)})=\boldsymbol{\mu}^{(i)} + \boldsymbol{\sigma^{(i)}}\odot \epsilon^{(l)}\\ & \; with \; \epsilon\sim \mathcal{N}(\mathbf{0},\mathbf{I})\end{aligned}\tag{3.1.2} z(i,l)=gϕ(x(i),ϵ(l))=μ(i)+σ(i)⊙ϵ(l)withϵ∼N(0,I)(3.1.2)
⊙ \odot ⊙表示元素的乘积。如下图所示: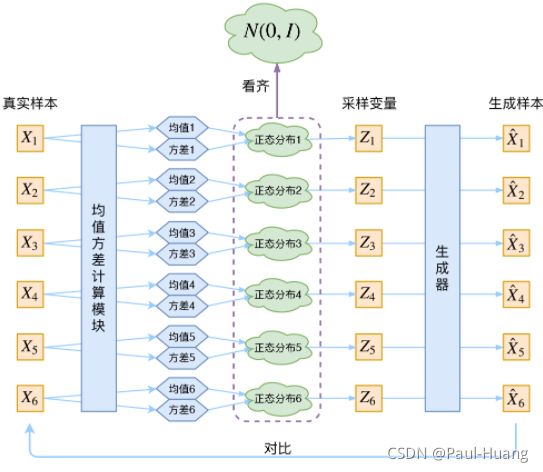
-
根据公式(3.1.1)和公式(3.1.2)对 公 式 ( 2.3.4 ) \color{green}公式(2.3.4) 公式(2.3.4)进行化简得 − D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) -D_{K L}\left(q_{\phi}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right) \| p_{\boldsymbol{\theta}}(\mathbf{z})\right) −DKL(qϕ(z∣x(i))∥pθ(z)):
∫ q θ ( z ) log p ( z ) d z = ∫ N ( z ; μ , σ 2 ) log N ( z ; 0 , I ) d z = − J 2 log ( 2 π ) − 1 2 ∑ j = 1 J ( μ j 2 + σ j 2 ) (3.1.3) \begin{aligned} \int q_{\boldsymbol{\theta}}(\mathbf{z}) \log p(\mathbf{z}) d \mathbf{z} &=\int \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2}\right) \log \mathcal{N}(\mathbf{z} ; \mathbf{0}, \mathbf{I}) d \mathbf{z} \\ &=-\frac{J}{2} \log (2 \pi)-\frac{1}{2} \sum_{j=1}^{J}\left(\mu_{j}^{2}+\sigma_{j}^{2}\right) \end{aligned}\tag{3.1.3} ∫qθ(z)logp(z)dz=∫N(z;μ,σ2)logN(z;0,I)dz=−2Jlog(2π)−21j=1∑J(μj2+σj2)(3.1.3)
∫ q θ ( z ) log q θ ( z ) d z = ∫ N ( z ; μ , σ 2 ) log N ( z ; μ , σ 2 ) d z = − J 2 log ( 2 π ) − 1 2 ∑ j = 1 J ( 1 + log σ j 2 ) (3.1.4) \begin{aligned} \int q_{\theta}(\mathbf{z}) \log q_{\boldsymbol{\theta}}(\mathbf{z}) d \mathbf{z} &=\int \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2}\right) \log \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2}\right) d \mathbf{z} \\ &=-\frac{J}{2} \log (2 \pi)-\frac{1}{2} \sum_{j=1}^{J}\left(1+\log \sigma_{j}^{2}\right) \end{aligned}\tag{3.1.4} ∫qθ(z)logqθ(z)dz=∫N(z;μ,σ2)logN(z;μ,σ2)dz=−2Jlog(2π)−21j=1∑J(1+logσj2)(3.1.4)
具体推导见论文附录。因此:
− D K L ( q ϕ ( z ∣ x ( i ) ) ∥ p θ ( z ) ) = ∫ q θ ( z ) ( log p θ ( z ) − log q θ ( z ) ) d z = 1 2 ∑ j = 1 J ( 1 + log ( ( σ j ( i ) ) 2 ) − ( μ j ( i ) ) 2 − ( σ j ( i ) ) 2 ) (3.1.5) \color{red}\begin{aligned} -D_{K L}\left(q_{\phi}\left(\mathbf{z} \mid \mathbf{x}^{(i)}\right) \| p_{\boldsymbol{\theta}}(\mathbf{z})\right)&=\int q_{\theta}(\mathbf{z})\left(\log p_{\boldsymbol{\theta}}(\mathbf{z})-\log q_{\boldsymbol{\theta}}(\mathbf{z})\right) d \mathbf{z} \\ &=\frac{1}{2} \sum_{j=1}^{J}\left(1+\log \left(\left(\sigma_{j}^{(i)}\right)^{2}\right)-\left(\mu_{j}^{(i)}\right)^{2}-\left(\sigma_{j}^{(i)}\right)^{2}\right)\end{aligned}\tag{3.1.5} −DKL(qϕ(z∣x(i))∥pθ(z))=∫qθ(z)(logpθ(z)−logqθ(z))dz=21j=1∑J(1+log((σj(i))2)−(μj(i))2−(σj(i))2)(3.1.5)
J J J为 z \mathbf{z} z的维数, μ \boldsymbol{\mu} μ和 σ \boldsymbol{\sigma} σ表示第 i i i个数据 x ( i ) \mathbf{x}^{(i)} x(i)的均值和方差, μ j \boldsymbol{\mu}_j μj和 σ j \boldsymbol{\sigma}_j σj表示均值和方差的第 j j j项。 -
对于数据 x ( i ) \mathbf{x}^{(i)} x(i)的最终模型为:
L ~ B ( θ , ϕ ; x ( i ) ) ≃ 1 2 ∑ j = 1 J ( 1 + log ( ( σ j ( i ) ) 2 ) − ( μ j ( i ) ) 2 − ( σ j ( i ) ) 2 ) ⏟ R e g u l a r i z a t i o n L o s s + 1 L ∑ l = 1 L ( log p θ ( x ( i ) ∣ z ( i , l ) ) ) ⏟ R e c o n s t r u c t i o n L o s s w h e r e z ( i , l ) = g ϕ ( x ( i ) , ϵ ( l ) ) = μ ( i ) + σ ( i ) ⊙ ϵ ( l ) a n d ϵ ( l ) ∼ N ( 0 , I ) (3.1.6) \color{red}\begin{aligned}&\widetilde{\mathcal{L}}^{B}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right)\simeq \underbrace{\frac{1}{2} \sum_{j=1}^{J}\left(1+\log \left(\left(\sigma_{j}^{(i)}\right)^{2}\right)-\left(\mu_{j}^{(i)}\right)^{2}-\left(\sigma_{j}^{(i)}\right)^{2}\right)}_{Regularization\;Loss}+\underbrace{\frac{1}{L} \sum_{l=1}^{L}\left(\log p_{\boldsymbol{\theta}}\left(\mathbf{x}^{(i)} \mid \mathbf{z}^{(i, l)}\right)\right)}_{Reconstruction\;Loss}\\ &where \quad\mathbf{z}^{(i,l)}=g_\phi(\mathbf{x}^{(i)},\epsilon^{(l)})=\boldsymbol{\mu}^{(i)} + \boldsymbol{\sigma^{(i)}}\odot \epsilon^{(l)} \quad and \quad \boldsymbol{\epsilon}^{(l)} \sim \mathcal{N}(\mathbf{0},\mathbf{I})\end{aligned}\tag{3.1.6} L B(θ,ϕ;x(i))≃RegularizationLoss 21j=1∑J(1+log((σj(i))2)−(μj(i))2−(σj(i))2)+ReconstructionLoss L1l=1∑L(logpθ(x(i)∣z(i,l)))wherez(i,l)=gϕ(x(i),ϵ(l))=μ(i)+σ(i)⊙ϵ(l)andϵ(l)∼N(0,I)(3.1.6)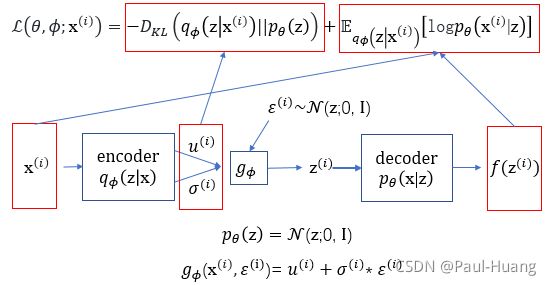
-
VAE整体流程:
L ~ B ( θ , ϕ ; x ( i ) ) = − D K L [ q ϕ ( z ∣ x ( i ) ) ⏞ Encoder ∥ p θ ( z ) ⏞ Fixed ] + 1 L ∑ l = 1 L log p θ ( x ( i ) ∣ z ( l ) ) ⏞ Decoder (3.1.7) \widetilde{\mathcal{L}}^{B}\left(\boldsymbol{\theta}, \boldsymbol{\phi} ; \mathbf{x}^{(i)}\right) = - D_{K L}[\overbrace{q_{\phi}(\textbf{z} \mid \textbf{x}^{(i)})}^{\text{Encoder}} \lVert \overbrace{p_{\theta}(\textbf{z})}^{\text{Fixed}}] + \frac{1}{L} \sum_{l=1}^{L} \log \overbrace{p_{\boldsymbol{\theta}}(\textbf{x}^{(i)} \mid \textbf{z}^{(l)})}^{\text{Decoder}}\tag{3.1.7} L B(θ,ϕ;x(i))=−DKL[qϕ(z∣x(i)) Encoder∥pθ(z) Fixed]+L1l=1∑Llogpθ(x(i)∣z(l)) Decoder(3.1.7)
具体来说,当先验和近似后验是高斯时,这是一次遍历计算图:
μ x , σ x = M ( x ) , Σ ( x ) Push x through encoder ϵ ∼ N ( 0 , 1 ) Sample noise z = ϵ σ x + μ x Reparameterize x r = p θ ( x ∣ z ) Push z through decoder recon. loss = MSE ( x , x r ) Compute reconstruction loss var. loss = − KL [ N ( μ x , σ x ) ∥ N ( 0 , I ) ] Compute variational loss L = recon. loss + var. loss Combine losses \begin{aligned} \boldsymbol{\mu}_x, \boldsymbol{\sigma}_x = M(\textbf{x}), \Sigma(\textbf{x})& \;\;\; \text{Push $\textbf{x}$ through encoder}\\ \boldsymbol{\epsilon} \sim \mathcal{N}(0, 1)&\;\;\; \text{Sample noise}\\ \textbf{z} = \boldsymbol{\epsilon} \boldsymbol{\sigma}_x + \boldsymbol{\mu}_x &\;\;\; \text{Reparameterize}\\ \textbf{x}_r = p_{\boldsymbol{\theta}}(\textbf{x} \mid \textbf{z})& \;\;\; \text{Push $\textbf{z}$ through decoder}\\ \text{recon. loss} = \text{MSE}(\textbf{x}, \textbf{x}_r) &\;\;\;\text{Compute reconstruction loss}\\ \text{var. loss} = -\text{KL}[\mathcal{N}(\boldsymbol{\mu}_x, \boldsymbol{\sigma}_x) \lVert \mathcal{N}(0, I)] &\;\;\; \text{Compute variational loss}\\ \text{L} = \text{recon. loss} + \text{var. loss}&\;\;\; \text{Combine losses} \end{aligned} μx,σx=M(x),Σ(x)ϵ∼N(0,1)z=ϵσx+μxxr=pθ(x∣z)recon. loss=MSE(x,xr)var. loss=−KL[N(μx,σx)∥N(0,I)]L=recon. loss+var. lossPush x through encoderSample noiseReparameterizePush z through decoderCompute reconstruction lossCompute variational lossCombine losses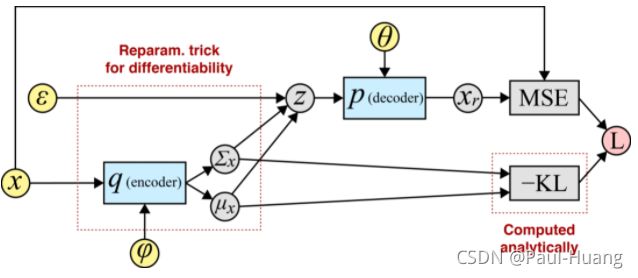
其中黄色代表输入。
3.2 VAE 的对抗
- 如上图, 重 构 的 过 程 是 希 望 没 噪 声 的 , 而 K L l o s s 则 希 望 有 高 斯 噪 声 的 , 两 者 是 对 立 的 \color{red}重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的 重构的过程是希望没噪声的,而KLloss则希望有高斯噪声的,两者是对立的。所以, V A E 跟 G A N 一 样 , 内 部 其 实 是 包 含 了 一 个 对 抗 的 过 程 , 只 不 过 它 们 两 者 是 混 合 起 来 , 共 同 进 化 的 \color{red}VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的 VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。
4. 代码示例
4.1 编码器
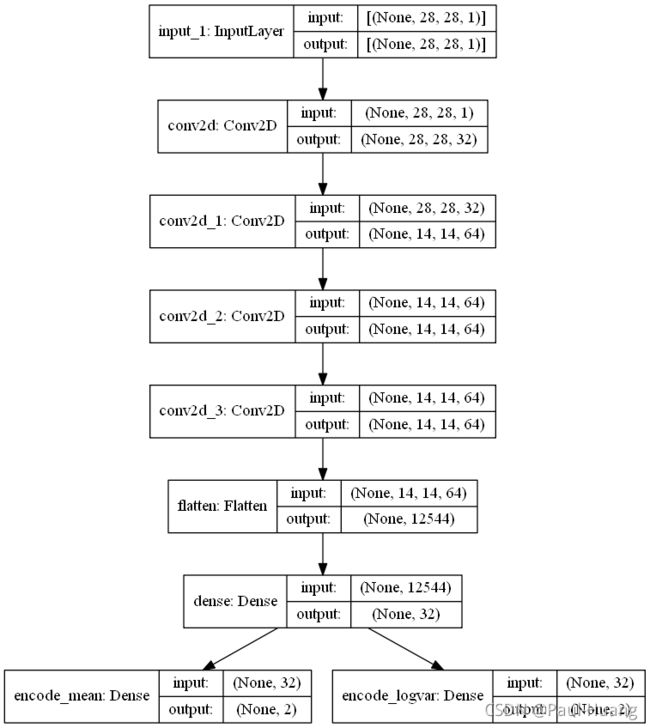
利用简单堆叠卷积层与全连接层将MNIST的数字图像转换为2维的正态分布均值与对数方差:
import keras
from keras import layers,Model,models,utils
from keras import backend as K
from keras.datasets import mnist
from scipy.stats import norm
from keras.utils.vis_utils import plot_model
import numpy as np
import matplotlib.pyplot as plt
img_shape = (28, 28, 1)
latent_dim = 2
input_img = layers.Input(shape=img_shape)
x = layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(input_img) # 28*28*1
x = layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu', strides=2)(x) # 28*28*32
x = layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu')(x) # 14*14*64
x = layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu')(x) # 14*14*64
inter_shape = K.int_shape(x) # int_shape是返回张量或变量的shape,作为int或None条目的元组。
x = layers.Flatten()(x)
x = layers.Dense(32, activation='relu')(x)
encode_mean = layers.Dense(2, name='encode_mean')(x) # 分布均值
encode_log_var = layers.Dense(2, name='encode_logvar')(x) # 分布对数方差
encoder = Model(input_img, [encode_mean,encode_log_var], name='encoder')
plot_model(encoder, to_file='encoder.png', show_shapes=True)
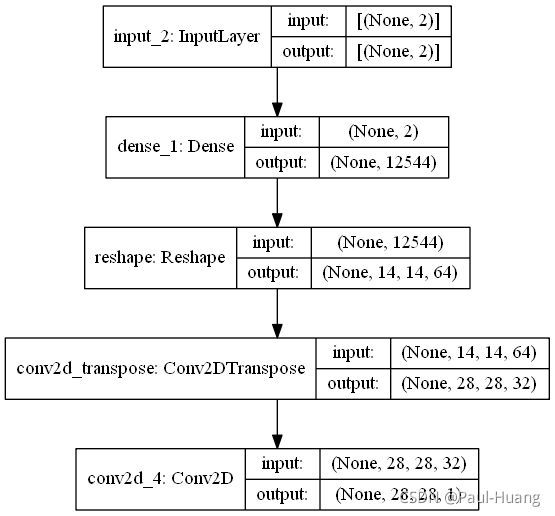
4.2 解码器
利用简单的堆叠卷积层、逆卷积层与全连接层将解码器接受2维向量,将这个向量“解码”为图像:
#%%解码器
input_code = layers.Input(shape=[2]) # [(None, 2)]
x = layers.Dense(np.prod(inter_shape[1:]), activation='relu')(input_code) # (None, 12544)
x = layers.Reshape(target_shape=inter_shape[1:])(x) # (None, 14, 14, 64)
x = layers.Conv2DTranspose(filters=32, kernel_size=3, padding='same', activation='relu', strides=2)(x) # (28, 28, 32)
x = layers.Conv2D(filters=1, kernel_size=3, padding='same', activation='sigmoid')(x) # (28, 28, 1)
decoder = Model(input_code, x, name='decoder')
plot_model(decoder, to_file='decoder.png', show_shapes=True)
4.3 整体待训练模型
-
整体待训练模型包括编码器、抽样层、解码器。
- 中 间 的 抽 样 操 作 \color{green}中间的抽样操作 中间的抽样操作在获取编码器传出的均值与方差后,通过一个自定义的lambda层来实现。这个抽样是先从标准正态分布中抽样,再通过乘生成分布的标准差,加上均值来获得。因此这个操作并不会把反向传播中断,可以将编码器与解码器的张量流连接起来。
-
定义好模型后是损失的定义,如前面所说,最终损失(目标函数)是生成图像与原图像之间的二元交叉熵和生成分布的正则化的平均值。使用add_loss方法来添加模型的损失。
# %%整体待训练模型
# 定义lambda要执行的函数
def sampling(arg):
mean = arg[0]
logvar = arg[1]
epsilon = K.random_normal(shape=K.shape(mean), mean=0., stddev=1.) # 从标准正态分布中抽样
return mean + K.exp(0.5 * logvar) * epsilon # 获取生成分布的抽样
# 使用lambda表达式,对函数进行传参
input_img = layers.Input(shape=img_shape, name='img_input')
code_mean, code_log_var = encoder(input_img) # 获取生成分布的均值与方差
x = layers.Lambda(sampling, name='sampling')([code_mean, code_log_var])
x = decoder(x)
training_model = Model(input_img, x, name='training_model')
decode_loss = keras.metrics.binary_crossentropy(K.flatten(input_img), K.flatten(x))
kl_loss = -5e-4 * K.mean(1 + code_log_var - K.square(code_mean) - K.exp(code_log_var))
training_model.add_loss(K.mean(decode_loss + kl_loss)) # 新出的方法,方便得很
training_model.compile(optimizer='rmsprop')
training_model.summary()
4.4 训练
因为损失函数并没有定义真实数据与预测数据直接的损失,因此fit方法只需传入输入即可(不用输出)。
# %%读取数据集训练
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255
x_train = x_train[:, :, :, np.newaxis]
training_model.fit(
x_train,
batch_size=512,
epochs=100,
validation_data=(x_train[:2], None))
4.5 生成测试
-
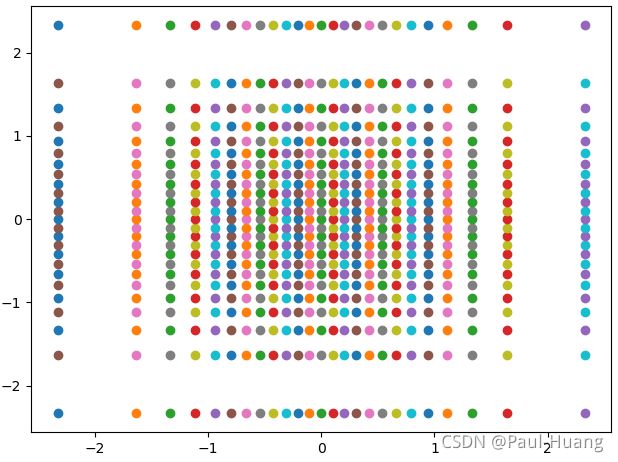
使用scipy.stats中的norm.ppf方法在概率区间(0.01,0.99)内生成20*20个解码器输入,这个方法类似在标准正态分布中抽样,但并不是随机的,是正态分布下的等概率。生成的二维点分布如下图:
-
这样抽样而不均匀抽样为了和编码器的生成分布契合,因为编码器正则化后生成的分布是靠近标准正态分布的。然后用解码器生成图片:
n = 25 x = y = norm.ppf(np.linspace(0.01, 0.99, n)) # 生成标准正态分布数 X, Y = np.meshgrid(x, y) # 形成网格 X = X.reshape([-1, 1]) # 数组展平 Y = Y.reshape([-1, 1]) input_points = np.concatenate([X, Y], axis=-1) # 连接为输入 for i in input_points: plt.scatter(i[0], i[1]) plt.show() img_size = 28 predict_img = decoder.predict(input_points) pic = np.empty([img_size*n, img_size*n, 1]) for i in range(n): for j in range(n): pic[img_size*i:img_size*(i+1), img_size*j:img_size*(j+1)] = predict_img[i*n+j] plt.figure(figsize=(10, 10)) plt.axis('off') pic = np.squeeze(pic) plt.imshow(pic, cmap='bone') plt.show()
参考:
- 【学习笔记】生成模型——变分自编码器
- 变分自编码器(一):原来是这么一回事
- VAE中的重参数化技巧-reparameterization trick
- VAE论文阅读
- 变分自编码器VAE
- 《A Deep Generative Framework for Paraphrase Generation》论文笔记
- VAE变分自编码器Keras实现