GhostNet解析以及Tensorflow2中实现Ghost模块
GhostNet解析以及Tensorflow2中实现Ghost模块
笔者从事嵌入式图像开发相关工作,希望能在ZYNQ上实现目标检测任务,故把更多的注意力放在轻量级网络上。
现阶段较为流行的轻量级网络有:MobileNetv1,v2,v3,ShuffleNet,EfficientNet和本文介绍的GhostNet。可能因为GhostNet是华为的成就或单纯的喜欢“Ghost"这个名字,笔者首先介绍GhostNet,其余网络结构将在后续文章中介绍。
GhostNet源于华为诺亚方舟实验室,可在同样的精度下,速度和计算量都小于SOTA算法。
该论文提供了一个全新的Ghost模块,旨在通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列线性变换,以很小的代价生成许多能从原始特征发掘所需信息的“幻影”特征图(Ghost feature maps)。该Ghost模块即插即用,通过堆叠Ghost模块得出Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。在ImageNet分类任务,GhostNet在相似计算量情况下Top-1正确率达75.7%,高于MobileNetV3的75.2%。
笔者更注重算法的实现部分,因此和之前博文一样,原理部分不做详细解释,如有需要可参考(https://zhuanlan.zhihu.com/p/109325275)
GhostNet_tensorflow2.0+实现源码参考:https://blog.csdn.net/qq_36758914/article/details/107511908
GhostNet核心思想:
首先,从全局的角度看一下GhostNet的模型结构:

注:exp表示扩展的尺寸,out表示输出的维度,SE表示使用SE模块,Stride表示步长。
可以看到,整个网络结构用了大量的G-bneck模块。在G-bneck模块中使用了SE模块。
Ghost Module是整个网络的核心,也是论文的精髓。接下来简单介绍下Ghost Module 的原理。

论文中使用上图来向大家介绍,相同颜色的框可以通过线性变换得到。基于这个理论,作者提出:将用于获得这张特征图的卷积核数量减少一半(则得到的特征图的通道数会减少一半),然后将得到的特征图进行线性运算(在下图中用扳手表示),得到缺少的另一半特征图,最后将这两部分特征图合并,得到和原来特征图相同的尺寸。如下图所示:

可以这样理解这个算法,使用正常的卷积生成原有特征层的一半,再对得到的这些特征层进行线性运算,类似(WX+b),只不过这里我们用的是卷积来实现线性运算,最后得出与原有特种层一样的特征层个数。这样子操作的好处可以大大降低速度和参数量。
使用Ghost模块升级普陀卷积的理论加速比为: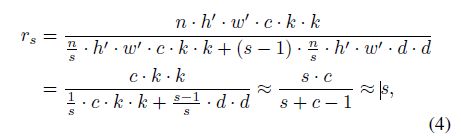
同样,理论压缩比可以计算为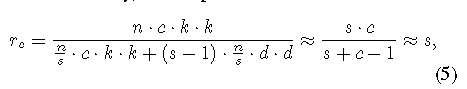
Ghost模块实现:
Ghost模块中包含了SE模块,因此在介绍Ghost模块之前先介绍SE模块相关知识。第一次接触到SE模块是在MobileNet中,个人对SE模块的理解是通过池化,线性操作获取每个网络特征层的权重,然后根据权重将特征层进行重现排布。如下图所示:
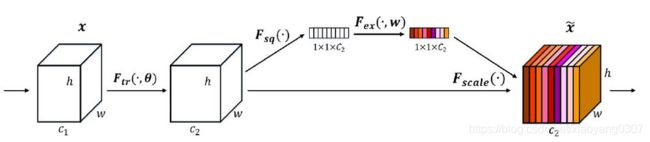
增加特征权重后等同于增加注意注意力机制,且消耗参数与运算力均可以接收。SE代码如下:
class SEModule(Layer):
def __init__(self, filters, ratio):
super(SEModule, self).__init__()
self.pooling = GlobalAveragePooling2D()
self.conv1 = Conv2D(int(filters / ratio), (1, 1), strides=(1, 1), padding='same',
use_bias=False, activation='relu')
self.conv2 = Conv2D(int(filters), (1, 1), strides=(1, 1), padding='same',
use_bias=False, activation=None)
self.relu = Activation('relu')
self.hard_sigmoid = Activation('hard_sigmoid')
def call(self, inputs):
x = self.pooling(inputs)
x = Reshape((1, 1, int(x.shape[1])))(x)
x = self.relu(self.conv1(x))
excitation = self.hard_sigmoid(self.conv2(x))
x = inputs * excitation
return xSE的实现分为两部分实现,第一部分负责压缩(Squeeze),第二部分负责激励(Excitation)。如下图所示(图片来源:https://blog.csdn.net/qq_42617455/article/details/108165206):

左图实现图像压缩,也就是用一个全局池化层。实现代码为GlobalAveragePooling2D()。
激励部分使用两次1*1卷积提取特征(也就是权值),这里需要注意的是,SERadic参数。SERadic为了减少全连接层的计算量设定的超参数。表示为原有特征层的1/radic分之一。通过1*1卷积和relu激活函数可以实现非线性运算,提取的特征权重更加丰富。
介绍完Ghost模块的组成部分SE后,接下来详细介绍Ghost部分的实现。
Ghostneck部分是由Ghost module和DW卷积组成。我们先看下最小组成单元——Ghostmodule的代码
class GhostModule(Layer):
"""
The main Ghost module
"""
def __init__(self, out, ratio, convkernel, dwkernel):
super(GhostModule, self).__init__()
self.ratio = ratio
self.out = out
self.conv_out_channel = ceil(self.out * 1.0 / ratio)
self.conv = Conv2D(int(self.conv_out_channel), (convkernel, convkernel), use_bias=False,
strides=(1, 1), padding='same', activation=None)
self.depthconv = DepthwiseConv2D(dwkernel, 1, padding='same', use_bias=False,
depth_multiplier=ratio-1, activation=None)
self.slice = Lambda(self._return_slices, arguments={'channel': int(self.out - self.conv_out_channel)})
self.concat = Concatenate()
@staticmethod
def _return_slices(x, channel):
return x[:, :, :, :channel]
def call(self, inputs):
x = self.conv(inputs)
if self.ratio == 1:
return x
dw = self.depthconv(x)
dw = self.slice(dw)
output = self.concat([x, dw])
return output上面这段代码通过类的方式定义GHOST模块。代码语法上没有特别复杂的。其中out表示输出维度,ratio表示原始特征图数量(默认为2),convkerel表示针对输入图像卷积核大小,dwkernel表示对原始特征线性变化时用的卷积核大小。
实现步骤:
1.利用convkernel对原始图像卷积,获取输出特征图维度的1/2。
2.利用dwkernel对原始图像DW卷积,获取输出特征图维度的1/2。
3.去除多余特征层
4.对两组特征图进行拼接。
这里简单介绍下DW卷积——DepthwiseConv2D(详细接下来MobileNet介绍)。DW卷积将特征通道数分离后,对每个特征层进行卷积。输出的特征层数与原有特征层数相同。
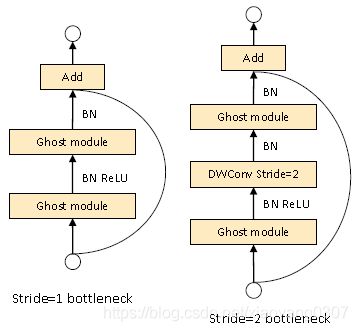
介绍完GHOST模块后,接下来介绍GhostNeck。GhostNet由多个GhostNeck组成,也是整个网络最核心的组成部分。GhostNeck有两种形式,如上图所示。他们通过改变strides修改特征图的大小。值得注意的是:只有在第一次Ghostmodul后加了RELU激活,之后均只用了BN。这点也是收到MobileNet的启发,增加relu激活会减少整体结构的表达能力。实现代码如下:
class GBNeck(Layer):
def __init__(self, dwkernel, strides, exp, out, ratio, use_se):
super(GBNeck, self).__init__()
self.strides = strides
self.use_se = use_se
self.conv = Conv2D(out, (1, 1), strides=(1, 1), padding='same',
activation=None, use_bias=False)
self.relu = Activation('relu')
self.depthconv1 = DepthwiseConv2D(dwkernel, strides, padding='same', depth_multiplier=ratio - 1,
activation=None, use_bias=False)
self.depthconv2 = DepthwiseConv2D(dwkernel, strides, padding='same', depth_multiplier=ratio - 1,
activation=None, use_bias=False)
for i in range(5):
setattr(self, f"batchnorm{i + 1}", BatchNormalization())
self.ghost1 = GhostModule(exp, ratio, 1, 3)
self.ghost2 = GhostModule(out, ratio, 1, 3)
self.se = SEModule(exp, ratio)
def call(self, inputs):
x = self.batchnorm1(self.depthconv1(inputs))
x = self.batchnorm2(self.conv(x))
y = self.relu(self.batchnorm3(self.ghost1(inputs)))
if self.strides > 1:
y = self.relu(self.batchnorm4(self.depthconv2(y)))
if self.use_se:
y = self.se(y)
y = self.batchnorm5(self.ghost2(y))
return add([x, y])
实现步骤如下:
1.经过DW卷积和BN。
2.经过普通卷积卷积和BN。(这里输出维度与最后需要输出的维度相同)
3.经过ghost module 和BN+RELU(这里输出维度是exp层特征)
4.判断strides,如果>1,进行第二次DW卷积+BN+RELU。(这里是为了减少特征图尺寸)
5.判断是否使用SE模块
5.经过第二次Ghost module+BN(这里没有RELU,同时,这里输入维度是ex扩展后的维度,输出维度是最终维度)
6.将第二步的特征层与最终结果相加,类似于resnet的用法。
总结:
分析GhostNet可以看出,该篇论文作者在提出“影子”特征的同时大量参考了MobileNet,SE net的核心思想。加入了SE模块,DW卷积以及Relu使用方法等思想。另外还有两个ghostmodule先升维再降维的用法有别于1*1先降维+3*3卷积+1*1卷积升维的方法。
GhostNet结合了百家之长,又有独特的创新点在其中。