Quadtree attention for vision transformers_四叉树注意力
论文 代码 相关
Quadtrees的概念, quadtrees通常用于递归地将二维空间细分为4个象限或区域。
Jupyter Notebook介绍、安装及使用教程 ——本人还不懂这个的使用,,,,
读这篇文章的之前,老生常谈了:
- Transformer
- 好呀,好在它能建立远距离依赖,因为attention
- 不好嘛,就是它的二次复杂度,计算量大。这个二次复杂是因为啥呢?因为attention
- attention attention attention !!!这东西太不省心了,它不仅关注自己,还要管别人家的事,管着管着就知道别人家的事啦,那不远距离就建立起来了嘛,但是管的多,它也就记得多,这复杂度也是杠杠滴!
单纯个人拟化娱乐一下,attention太不让人省心了。这部这篇文章就来治治它了~~~
核心:
文章主要对attention进行处理,提出了QuadTree Attention,实现了将二次复杂度降低到线性复杂度。具体而言:利用QuadTree Attention建立了一个token金字塔,并以一种从粗到细的方式计算注意力。在每一个level中,选择注意力最关注的patchs,在下一个level,就只计算和这些patchs对应的相关区域的注意力进行评估。
- image→patch→token:这里的patch和token只不过是flatten转换了下,感觉和之前看的文章表示还是一样的。
作者证明了QuadTree Attention在各种视觉任务中达到了最先进的性能,例如ScanNet的特征匹配性能提高了2.7%,FLOPs减少了约50%,ImageNet分类的Top-1准确率提高了0.6-1.4%,COCO目标检测FLOPs降低了30%,精度提高了1.3-1.6%。
介绍:
在视觉任务中,许多工作将Transformer用来选择在低分辨率或稀疏Token。
- ViT使用16×16像素的粗图像块来限制Token的数量。
- DPT将ViT的低分辨率结果提升到高分辨率特征图,以实现密集任务的预测。
- SuperGlue将Transformer应用于稀疏图像关键点。
- Germain和Li等人专注于通信和立体匹配应用,也将Transformer应用于低分辨率特征图。
但是,高分辨率Transformer的效果对于众多任务来说更重要。而高分辨率所带来的就是计算复杂度的上升,由此引发众多学者研究设计高效的Transformer以降低计算复杂度。
- 线性近似Transformer使用线性方法近似标准的注意力计算。然而,实证研究表明,线性Transformer在视觉任务方面较差。
- PVT使用下采样的key和value,降低计算成本,但是降低了捕获像素级细节。
- Swin Transformer将局部窗口中的注意力限制在一个注意力块中,这破坏了Transformer建立远距离依赖的优势。
本文设计了一个高效的视觉Transformer,它可以捕捉精细的图像细节和建立远距离依赖关系。在观察到大多数图像区域是不相关的启发下,构建了Token pyramids,并以从粗到细的方式计算注意力。这样,当对应的粗粒度区域没有前景时,可以快速跳过细粒度的不相关区域。

如图所示:
- 在level-1,用B中的所有patch计算A中的蓝色patch的注意力,并选择top-K个patch(这里K=2),这也是用蓝色高亮显示的;——注意力最关注的地方标蓝
- 在level-2中,对于A图中4个Patches内的sub-patch(即level-1的蓝色patch对应的sub-patch),这里只使用level-1 B图中top-K个patch对应的sub-patch来计算它们的注意力。所有其他的阴影sub-patch被跳过以减少计算。这里用黄色和绿色标出A图中的2个sub-patch。B图中对应的top-K个patch也用同样的颜色高亮显示。——蓝色区域进一步关注
- 这个过程在level-3进行迭代,在level-3中,只显示与level-1的绿色sub-patch相对应的sub-sub-patch。
简单来说就是,关注的的地方不断去确认最关注的地方,不相关的就此停止关注。
因此,该方法既能获得精细的规模注意力,又能保持远距离的联系。最重要的是,在整个过程中只有稀疏的注意力被评估,具有较低的内存和计算成本。
在实验中,证明了QuadTree Transformer在需要cross attention的任务(如特征匹配和立体视觉)和只使用Self-Attention的任务(如图像分类和目标检测)中的有效性。
- 与相关的Efficient Transformer相比,QuadTree Transformer实现了最先进的性能,显著减少了计算量。
- 在特征匹配方面,在ScanNet中实现了60.3 AUC@20,比线性Transformer高2.7,但FLOPs类似。
- 在立体匹配中,实现了与标准Transformer相似的端点误差,但减少了约50%的FLOPs和40%的内存。
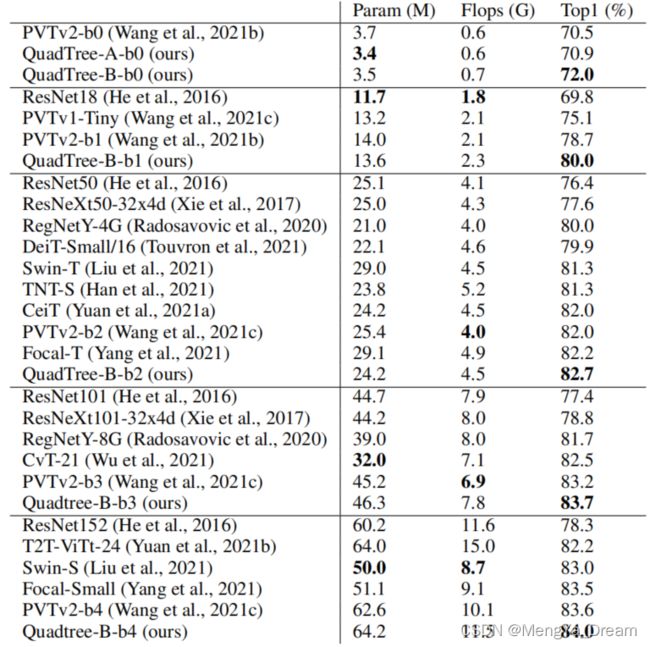
- 在图像分类方面,在ImageNet中获得了82.6%的top-1准确率,比ResNet高6.2%,比Swin Transformer-T高1.3%,且参数更少,FLOPs数更少。
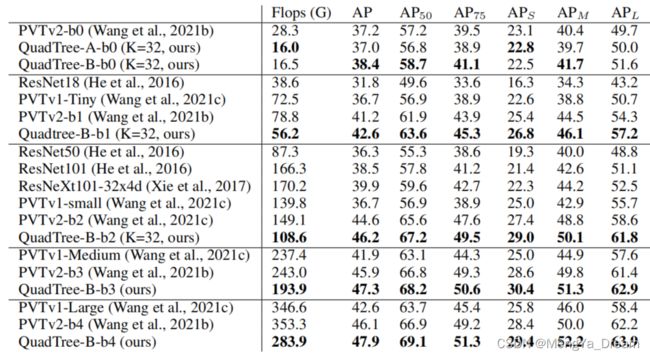
- 在目标检测方面,QuadTree Attention+RetinaNet在COCO中获得了46.2 AP,比PVTv2 Backbone高1.6,但FLOPs降低了约35%。
相关工作:
1 Efficient Transformer
由于二次型计算的复杂性,在处理长序列token时无法进行充分注意的计算。因此,许多工作都在设计高效的transformer,以降低计算复杂度。Efficient Transformers可分为3类:
-
Linear approximate attention:通过对softmax注意力进行线性化来近似全注意矩阵,通过先计算key和value的乘积来加速计算;
-
Point-Based Linear Transformers:使用学习过的固定大小的诱导点对输入符号进行关注,从而将计算量降低到线性复杂度。然而,在不同的工作条件下,这些线性Transformer的性能都不如标准Transformer。
-
Sparse attention:包括Longformer、Big Bird等,每个query token都是针对key和value token的一部分,而不是整个序列。
2 Vision Transformer
Transformers在许多视觉任务中都表现出了非凡的表现。
- ViT将Transformers应用于图像识别,证明了Transformers在大规模图像分类方面的优越性。然而,由于Softmax注意力的计算复杂度,在密集的预测任务中,如目标检测、语义分割等,很难应用Transformers。为了解决这个问题:
- Swin Transformer限制了局部窗口中的注意力计算。
- Focal Transformers使用2层窗口来提高捕获远程连接的能力,以实现局部注意力方法。
- 金字塔视觉Transformers(PVT)通过下采样key和value token来减少全局注意力方法的计算量。
- 尽管这些方法在各种任务中都显示出了改进,但它们在捕获长期依赖或精细水平注意力方面都存在缺陷。与这些方法不同的是,QuadTree Attention通过在单个块中计算出从全图像级别到最优token级别的注意力,同时捕获局部和全局注意力。此外,K-NN Transformers从与最相似的top-K个token中聚合信息,但KNN计算所有对query token和key token之间的注意力得分,因此仍然具有二次复杂度。
除了Self-Attention,许多任务在很大程度上都能从Cross Attention中受益。
- Superglue过程检测具有Self-Attention和Cross Attention的局部描述符,并在特征匹配方面显示出显著的改进。标准Transformer可以应用于SuperGlue,因为只考虑稀疏的关键点。
- SGMNet通过seeded matches进一步减少了计算量。
- LoFTR在低分辨率特征图上利用线性Transformer生成密集匹配。
- 对于立体匹配,STTR沿着极线应用Self-Attention和Cross Attention,并通过梯度检查点减少了内存消耗。
- 然而,由于需要处理大量的点,这些工作要么使用有损性能的线性Transformer,要么使用有损效率的标准Transformer。
相比之下,QuadTree Transformer与线性Transformer相比具有显著的性能提升,或与标准Transformer相比效率提高。此外,它还可以应用于Self-Attention和Cross Attention。
方法-QuadTree Transformer:
1 Attention in Transformer
Vision Transformers在许多任务中都取得了巨大的成功。Transformer的核心是注意力模块,它可以捕获特征嵌入之间的远程信息。给定2个图像嵌入点 和
和 ,注意力模块在它们之间传递信息。自注意力机制是指和相同时的情况,而Cross Attention则是指和不同时更普遍的情况。详细的计算都是标准啦,文章也有详细介绍,大家可以自行了解哦。
,注意力模块在它们之间传递信息。自注意力机制是指和相同时的情况,而Cross Attention则是指和不同时更普遍的情况。详细的计算都是标准啦,文章也有详细介绍,大家可以自行了解哦。
2 QuadTree Attention
为了降低Vision Transformer的计算成本,本文提出了QuadTree Attention。顾名思义,借用了 quadtrees的概念, quadtrees通常用于递归地将二维空间细分为4个象限或区域。
QuadTree Attention以粗到细的方式计算注意力。根据粗级的结果,在细级快速跳过不相关的图像区域。这种设计在保持高效率的同时,减少了信息损失。与常规Transformer一样,首先将和线性投影到query、key和value token上。为了方便快速的注意力计算,本文通过下采样特征映射构造L-level金字塔用于query Q、key K和value V token。
- 对于query和key token,使用平均池层;
- 对于value token,如果是交叉注意力任务则使用平均池化,如果时Self-Attention任务,则使用stride为2的Conv-BN-ReLU。
如前图所示,在计算了粗粒度的注意力分数后,对于每个query token,选择注意力分数最高的top-K个key token。在细粒度上,query sub token只需要用那些对应于粗粒度上所选K个key token之一的key sub token来计算。这个过程不断重复,直到达到最好的水平。在计算了注意力分数之后,在所有粒度上聚合信息,这里设计了2个架构,称为QuadTree-A和QuadTree-B。

QuadTree-A
考虑到最佳级别的第i个query token  ,需要从所有key token计算其收到的消息
,需要从所有key token计算其收到的消息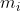 。该设计通过收集不同金字塔层次的部分信息来组装完整的信息。
。该设计通过收集不同金字塔层次的部分信息来组装完整的信息。
如b所示,message 是由不同图像区域不同区域颜色的3个partial message生成的,共同覆盖整个图像空间。绿色区域表示最相关的区域,在最精细的level上评价和计算,而红色区域是最不相关的区域,在最粗的level上进行评价和计算。
对于QuadTree-A,使用平均池化层对所有query、key和value token进行下采样。
QuadTree-B
QuadTree-A中从所有层次上递归计算的注意力分数,这使得在更精细的层次上的分数变小,并减少了精细图像特征的贡献。此外,精细水平的得分也在很大程度上受到粗水平的不准确性的影响。因此,设计了一个不同的方案,称为QuadTree-B来解决这个问题。
QuadTree-A和QuadTree-B都只涉及稀疏注意力评价。因此,该方法大大降低了计算复杂度。QuadTree Attention的计算复杂度与Token的数量是线性的。
Multiscale position encoding
注意力的计算对token来说是排列不变的,因此会丢失位置信息。为了解决这个问题,在每个层次上采用局部增强的位置编码(LePE) 来设计一个多尺度的位置编码。具体来说,对于level-l,对value token ![]() 应用非共享深度卷积层来编码位置信息。
应用非共享深度卷积层来编码位置信息。
实验:
1 Cross attention tasks
-
Feature matching

-
S tereo matching

2 Sels-attention task
- Image classification
- Object detection
3 Comparison with other attention mechanisms
与其他注意力机制进行公平的比较,在相同的backbone和训练设置下测试了这些注意力机制。
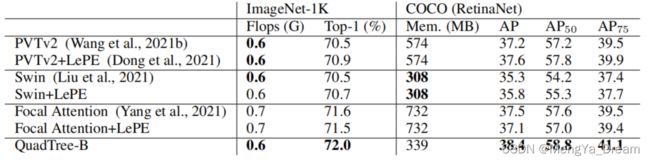
与Focal Attention相比,QuadTree Attention在目标检测上的结果提高了1.0,这可能是因为QuadTree Attention总是能够覆盖整个图像,而Focal Attention在第一阶段只覆盖了图像的1/6。
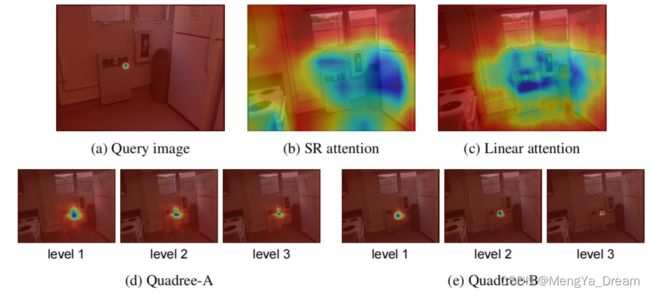
对于Cross Attention任务,本文提供了可视化的注意力分数,如图所示。QuadTree Attention可以注意到比PVT和Linear attention更多的相关区域。