Batch Normal - 批量规范化(CNN卷积神经网络)
文章目录
-
- Batch Normal - 批量规范化
-
- 全连接层
- 卷积层
- 预测过程中的批量规范化
- 从零实现
- 使用批量规范化层的 LeNet
- 简明实现
- 小结
Batch Normal - 批量规范化
批量规范化(batch normalization) [Ioffe & Szegedy, 2015],这是一种流行且有效的技术,是通过对样本数据进行规范化操作(如标准化正态分布、softmax回归等),使样本数据更加稳定,可持续加速深层网络的收敛速度。
主要公式如下:
B N ( x ) = γ ⊙ x − μ ^ B σ ^ B + β . \mathrm{BN}(\mathbf{x}) = \boldsymbol{\gamma} \odot \frac{\mathbf{x} - \hat{\boldsymbol{\mu}}_\mathcal{B}}{\hat{\boldsymbol{\sigma}}_\mathcal{B}} + \boldsymbol{\beta}. BN(x)=γ⊙σ^Bx−μ^B+β.
其中 μ ^ B \hat{\boldsymbol{\mu}}_\mathcal{B} μ^B 是均值, σ ^ B \hat{\boldsymbol{\sigma}}_\mathcal{B} σ^B 是标准差, γ {\gamma} γ 是拉伸参数(scale), β {\beta} β 是偏移参数(shift), x − μ ^ B σ ^ B \frac{\mathbf{x} - \hat{\boldsymbol{\mu}}_\mathcal{B}}{\hat{\boldsymbol{\sigma}}_\mathcal{B}} σ^Bx−μ^B 即标准化正态分布。
实现如下:
全连接层
通常,我们将批量规范化层置于全连接层中的仿射变换和激活函数之间。
若全连接层的输入为x,权重参数和偏置参数分别为 W \mathbf{W} W和 b \mathbf{b} b,激活函数为 ϕ \phi ϕ,批量规范化的运算符为 B N \mathrm{BN} BN。
那么,使用批量规范化的全连接层的输出的计算详情如下:
h = ϕ ( B N ( W x + b ) ) \mathbf{h} = \phi(\mathrm{BN}(\mathbf{W}\mathbf{x} + \mathbf{b}) ) h=ϕ(BN(Wx+b))
卷积层
同样,对于卷积层,我们可以在卷积层之后和非线性激活函数之前应用批量规范化。
所以,在计算平均值和方差时,我们会收集所有空间位置的值,然后在给定通道内应用相同的均值和方差,以便在每个空间位置对值进行规范化。
预测过程中的批量规范化
正如我们前面提到的,批量规范化在训练模式和预测模式下的行为通常不同。
首先,将训练好的模型用于预测时,我们不再需要样本均值中的噪声以及在微批次上估计每个小批次产生的样本方差了。 其次,例如,我们可能需要使用我们的模型对逐个样本进行预测。 一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。
可见,和暂退法一样,批量规范化层在训练模式和预测模式下的计算结果也是不一样的。
从零实现
接下来我们从零实现一个具有张量的批量规范化层。
import torch
from torch import nn
from d2l import torch as d2l
#对批量二维或思维数据进行正态分布标准化
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
#通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
#若当前是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
#要求输入的X数据必须为全连接层2个维度或者卷积层4个维度
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
#使用全连接层的情况,计算特征维度上的均值和方差
mean = X.mean(dim=0) #计算每个特征列上面的均值
var = ((X - mean) ** 2).mean(dim=0) #计算每个特征列上的方差
else:
#使用二维卷积层的情况,计算通道维上 (axis = 1) 的均值和方差
#这里我们需要保持X1的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
#训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
#更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
#缩放和移位
Y = gamma * X_hat + beta
#返回规范化后的数据,以及更新移动平均的均值和方差
return Y, moving_mean, moving_var
我们现在可以创建一个正确的BatchNorm层。 这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新。 此外,我们的层将保存均值和方差的移动平均值,以便在模型预测期间随后使用。
#定义批量数据集规范化模型
class BatchNorm(nn.Module):
#num_features: 完全连接层的输出数量或隐藏层的输出通道数
#num_dims: 2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
#参与求梯度和迭代的拉伸和偏移参数,分别初始化为1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
#非模型参数的变量参数初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
#如果X不在内存上,讲moving_mean和moving_var复制到X所在的显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
#保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(X, self.gamma, self.beta,
self.moving_mean, self.moving_var,
eps=1e-5, momentum=0.9)
return Y
使用批量规范化层的 LeNet
为了更好理解如何应用BatchNorm,下面我们将其应用于LeNet模型。 想象一下,批量规范化是在卷积层或全连接层之后、相应的激活函数之前应用的。
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.Linear(84, 10))
和以前一样,我们将在Fashion-MNIST数据集上训练网络。 这个代码与我们第一次训练LeNet时几乎完全相同,主要区别在于学习率大得多。
X = torch.rand(size=(1 ,1, 28, 28))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output:\t', X.shape)
Conv2d output: torch.Size([1, 6, 24, 24])
BatchNorm output: torch.Size([1, 6, 24, 24])
Sigmoid output: torch.Size([1, 6, 24, 24])
AvgPool2d output: torch.Size([1, 6, 12, 12])
Conv2d output: torch.Size([1, 16, 8, 8])
BatchNorm output: torch.Size([1, 16, 8, 8])
Sigmoid output: torch.Size([1, 16, 8, 8])
AvgPool2d output: torch.Size([1, 16, 4, 4])
Flatten output: torch.Size([1, 256])
Linear output: torch.Size([1, 120])
BatchNorm output: torch.Size([1, 120])
Sigmoid output: torch.Size([1, 120])
Linear output: torch.Size([1, 84])
BatchNorm output: torch.Size([1, 84])
Sigmoid output: torch.Size([1, 84])
Linear output: torch.Size([1, 10])
开始训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
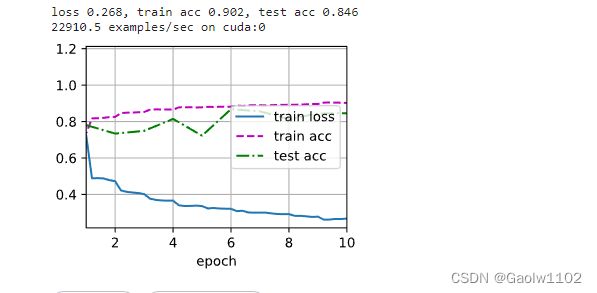
可见模型对于训练集的准确度为 0.908,测试集的精度为 0.846。
简明实现
除了使用我们刚刚定义的BatchNorm,我们也可以直接使用深度学习框架中定义的BatchNorm。 该代码看起来几乎与我们上面的代码相同。
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
再次训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

可能迭代次数较低,所以测试集的准确度不是非常理想,有兴趣的小伙伴可以设置迭代次数为20次或50次,再次测试结果。
小结
1.在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
2.批量规范化在全连接层和卷积层的使用略有不同。
3.批量规范化层和暂退层一样,在训练模式和预测模式下计算不同。
4.批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。