机器学习之批训练
机器学习入门之重要参数的理解
第一章 批数据训练(batch)
第二章 训练轮数(epoch)
第三章 学习率(LR : learning rate)
第四章 图像区块(patch)
第五章 滤波器(filter)
目录
机器学习入门之重要参数的理解
前言
一、批训练是什么?
二、批训练的作用
为什么说Batch size的增大能使网络的梯度更准确?
一个具体例子分析:
三、使用步骤
1.引入库
2.读入数据
3.批训练(源码)
4.运行结果
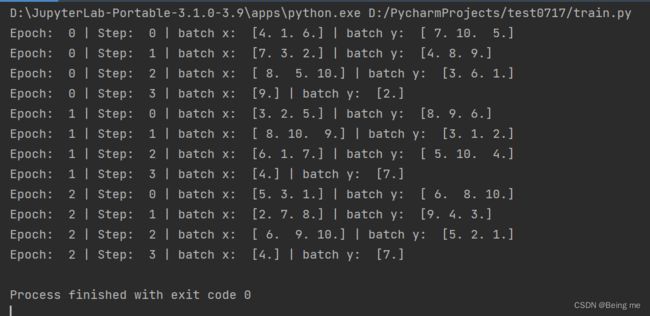
4.1 下面这个图为BATCH_SIZE = 3 时的结果
4.2 下面这个图为BATCH_SIZE = 6 时的结果
五、Batch_size调参注意事项
总结
前言
在开启学习机器学习之前,我们先来了解了解机器学习中重要的参数吧,本文介绍了机器学习的基础内容之批数据训练。
一、批训练是什么?
批训练,我觉得应再加上两个字为妙——批数据训练。
直观的理解:
Batch Size定义:一次训练所选取的样本数。
Batch Size的大小影响模型的优化程度和速度,也对GPU内存的使用情况有直接影响。
在没有使用Batch Size之前,在训练时会一次把所有的数据(整个数据库)输入网络中,然后计算它们的梯度进行反向传播;由于在计算梯度时使用了整个数据库,所以计算得到的梯度方向更为准确。但在这情况下,计算得到不同梯度值差别巨大,难以使用一个全局的学习率。
在小样本数的数据库中,不使用Batch Size是可行的,而且效果也很好。但是一旦是大型的数据库,一次性把所有数据输进网络,必引起内存爆炸,因此就提出Batch Size的概念。
二、批训练的作用
为应对大数据和内存限制,我们常采用批训练的方式以提高训练效率。
为什么说Batch size的增大能使网络的梯度更准确?
梯度的方差表示:
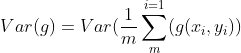
由于样本是随机选取的,满足独立同分布,所以所有样本具有相同的方差
所以有以下简化的式子:
![]()
可以看出当Batch size为m时,样本的方差减少m倍,梯度就更准确了。
一个具体例子分析:
在分布式训练中,Batch_size随着数据并行的workers增加而增大,假如baseline的Batch Size为B,而学习率为lr,训练epoch为N。假如保持baseline的lr,一般达不到很好的收敛速度和精度。
原因:对于收敛速度,假如有K个workers,则每个批次为KB,因此一个epoch迭代的次数为baseline的1k,而学习率lrlr不变,所以要达到与baseline相同的收敛情况,epoch要增大。而根据上面公式,epoch最大需要增大KN个epoch,但一般情况下不需要增大那么多。对于收敛精度,由于Batch_size的使用使梯度更准确,噪声减少,所以更容易收敛。
三、使用步骤
1.引入库
Torch中有一种整理我们数据结构的函数模块DataLoader,它能够包装我们的数据,并且进行批训练。
import torch.utils.data as Data2.读入数据
代码如下(示例):
# 2.1 初始数据:
x = torch.linspace(1 , 10, 10)
y = torch.linspace(10, 1, 10)
# 2.2 包装数据类:
# 先转换成 torch 能识别的 Dataset
torch_dataset = Data.TensorDataset(x,y) #现在的版本这样就行了
# 2.3 加载数据:.DataLoader
loader = Data.DataLoader(
dataset = torch_dataset, #数据集
batch_size = BATCH_SIZE, #每次读取的大小
shuffle = True, #是否随机打乱
num_workers=2, # 多线程来读数据
)
- Data.TensorDataset():包装数据和目标张量的数据集,通过沿着第一个维度索引两个张量来恢复每个样本。
- batch_size: 一次训练所选取的样本数,其大小影响模型的优化程度和速度,也对GPU内存的使用情况有直接影响。
- shuffle: random shuffle for training,其性能高低直接影响了整个程序的性能和吞吐量。
- num_workers=2:subprocesses for loading data,数据有x,y两类
- Data.DataLoader(): 数据加载器, 用以组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。
3.批训练(源码)
#批数据训练
BATCH_SIZE = 3
import torch
import torch.utils.data as Data
x = torch.linspace(1 , 10, 10)
y = torch.linspace(10, 1, 10)
# 加入“数据集”里面
torch_dataset = Data.TensorDataset(x,y)
loader = Data.DataLoader(
dataset = torch_dataset,
batch_size = BATCH_SIZE,
shuffle = True, #是否随机抽样
num_workers=2, # 多线程来读数据
)
if __name__ == '__main__': #没有这一行可能会报错:“he "freeze_support()" line can be omitted if the program”
for epoch in range(3):
for index,(batch_x,batch_y) in enumerate(loader):
# 打出来一些数据
print('Epoch: ', epoch, '| Step: ', index, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
- epoch:表示所有数据的训练次数
- batch:每一批次装载
4.运行结果
4.1 下面这个图为BATCH_SIZE = 3 时的结果
size为3,数据有10个,因此4次,前3次每次3个,最后一次1个。原因在于:当数据大小和每次话费大小不是整数倍时,最后一次划分就是剩下的,不一定就是BATCH_SIZE这么大。
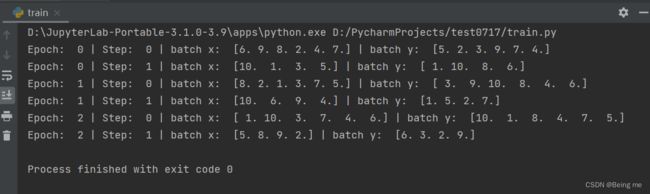
4.2 下面这个图为BATCH_SIZE = 6 时的结果
size为6,数据有10个,所以分为2次,第一次有6个数,第二次有4个数。
五、Batch_size调参注意事项
Batch Size的变化对网络产生的影响:
1、没有Batch_size时,梯度准确,只适用于小样本数据库
2、Batch_size=1时,梯度变来变去,非常不准确,网络很难收敛。
3、Batch_size增大时,梯度变准确,
4、Batch_size增大时,梯度已经非常准确,再增加Batch_size也没有用注意:Batch_size增大了,要到达相同的准确度,也应适当增大epoch。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了我对批数据训练以及参数batch_size的理解。望多多指教!