matlab 运用传统图像分割-深度学习的实现图像分割与识别案例-棉花的苞叶与叶
目录
1:单一棉花叶片的分割的讨论
1.1图像的获取与建模数据库的建立
1.2单一叶片分割策略的讨论
1.3深度学习-卷积神经网络的搭建与运用
2:整株棉花的叶片分割与识别
2.1:植株冠层图像的预处理:腐蚀、膨胀与判断
2.2识别判断与显示
2.3关于局限性与改进的简要讨论
摘要:本文通过脚本实现了自动化的图像获取及分割,建立了一个卷积神经网络的学习数据库,并以此建立一个基于Alexnet卷积神经网络的棉花叶片和苞叶识别模型,最后通过形态学分割方法与深度学习网络的结合,实现了实时分割棉花器官与叶片的效果。最终,初步满足了目标,但由于数据库不标准及图像分割的用(属于本人2021年的一个课程作业分享)
1:单一棉花叶片的分割的讨论
1.1图像的获取与建模数据库的建立
数据于2021年6月-9月新疆库尔勒采集的棉花叶片,所有图片依据数据类型、采集日期、和序号分别放入了四层文件夹中。为了将自动快速将主茎叶、果枝叶以及苞叶的图片从文件中按规律的快速提取出来,首先我编写了一个快速获取文件的脚本。图像抓取的脚本如getPicture.m所示,这个脚本帮助我们非常快抓取到了历史库中的23000余图片,并配合自定义函数findFile.m快速的将图片按照波段分别放入了460nm、520nm等不同的文件夹,方便我们后续进行建模学习和处理。
1.2单一叶片分割策略的讨论
试验方法,在大田中采集棉花叶片,通过自建的多光谱成像系统对单一的棉花叶片进行采集,每片叶子采集9张不同类型的光谱成像数据,因为需要将棉花贴到背景板上需要粘性材料,这使棉花在某些波段下会有背景的反射,如图一所示。
 图一:普通阈值分割下的棉花二值化图像
图一:普通阈值分割下的棉花二值化图像
显然,对于每张照片的单独分割无法满足要求,但是通过观察可以发现,在某些波段下对叶片的分割效果使极好的,比如对进行(520nm)的波段下分割,可以清晰地将叶片分割,这是因为520nm即绿色是植物反射,而同样一片叶子在图中显示的位置是固定的。还有一个完美的分割源是多光谱荧光的红光与近红外红光的波段,这一波段有较强的荧光效果,且荧光源的本身把周围杂点的反射个屏蔽了。为此本文调用自定义函数先将多光谱荧光的红光波段的进行图像分割,并输出一个二值化矩阵,再用二值化矩阵点乘该叶片的其他照片,使其他照片也达到令人满意的效果。
为了快速进行参数调试,本文自定义了分割函数T_SGM.m[1],其支持迭代法全局阈值分割, 全局阈值Otsu法阈值分割与基于形态学元素的局部分割方法,实现方法如T_SGM.m(其表示Threshold-segmentation)的内容所示。其次,为了消除背景杂点,本文设定了自定义函数DeleNos_dot.m[2],其基本判断逻辑为:若该像素周围包括1以内的切比雪夫距离没有有超过3个的亮点,则判断该为点为图像分割的噪声杂点,这一过程相当于判断点的连通性,可以配合imfill函数实现,而噪点其实是可以通过傅里叶变化后的滤波实现。但是显然,自定义函数更加简介且好定义。最终分割效果如图二所示

图二:将520nm波段下的全局阈值Otsu法分割扩展到其他波段图像的方法
1.3深度学习-卷积神经网络的搭建与运用
基于卷积网络的深度学习自2012年2012年ILSVRC(分类)AlexNet获得冠军以后[3],掀起深度学习计算机视觉狂潮提出以来:就被大量的运用到在了图像识别和分割的领域上,
这篇文章也被引用了高达12万次。本文拟建立的卷积神经网络就是基于AlexNet所搭建的。
本文搭建的网络如图所示,存放于文件夹中的Alnex_2.mat文件中。该模型输入为227*227,1通道,过大的输入会导致模型训练难度过大,而过小的模型输入会导致模型准确率难以提示。因此,在输入建模集之前,我们要先将图片运用imresize()函数进行尺寸调整,通过适当地旋转、拉伸、以及平移等函数使我们的建模集更加全面。

图三:本文基于AlnexNet建立的模型结构

图四:建模集内容
该模型输出主要包括:undefined(未知)、bud(苞叶)、leaf(叶片),但需要注意的是神经网络一般都不会输出undefined,尽管其将目标判断错误,这是由神经网络的特性决定的,我们必须给出未知的样本让神经网络理解未知,否则只有在神经网络出现梯度爆炸时才会显示undefined的定义,如图5所示。如图4所示,建模及样本包含1483叶片样本,以及210份苞叶样本。本文模型的建立运用的时matlab2022a的深度网络设计器app。如图六所示,其提供了大量的模块接口,方便我们建立深度学习网络的各层接口。

图五:出现梯度爆炸,Loss为NaN
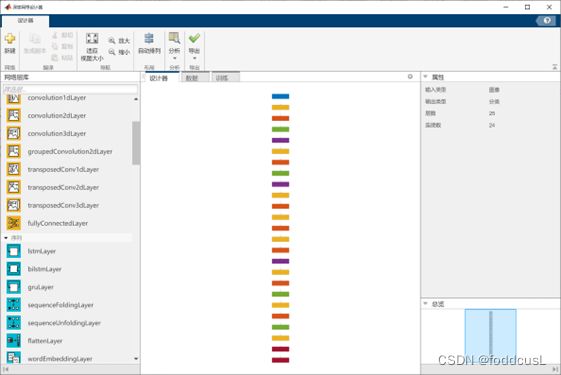
图六:设计器界面

图七:模型训练效果
最终,利用Alnex深度学习模型,我们对花蕾和叶片的识别可以达到97.5%以上的识别率。本课设的重点并不在神经网络,所以其卷积层和池化以及全连接层的概念和运行流程这里就不作赘述。
2:整株棉花的叶片分割与识别
在植物表型的研究中,植物的表型具有个体差异性,小尺度的角度下的植株信息有良好的精度但也会放大个体差异以至于需要大量的重复试验,而宏观尺度下植株信息又会损失严重,模型精度不佳,如何将叶片尺度提升至植株尺度,最后再将植株尺度提升到大田冠层尺度,一直是各位学者关注的问题,为此本最后通过运用叶片尺度下的模型对植株冠层尺度下的图像进行分析。如图八所示,原始图像包含了植株的各个茎叶内容。
(一下为这一部分的代码参考)
%%这个代码主要是将图中的主要区域框选进来,并提交给代码进行识别
%%输入 img图片
%输出:分割的图片数量,及区域(上标点与下标点)
clear all
img_orin=imread("D:\同步空间\试验\盆栽棉花实验\2021年棉花第一轮实验\6-11_12\表型平台\2022.06.12\2022.06.12\56\13_22_37#Multispectral\0005.jpg");
img_div=T_SGM(img_orin,3,80);%局部分隔,最大分割值为80
IM2=img_div;
%figure,imshow(img_div)
for i=1:10%循环腐蚀和分割,减少图中整体
[L,n(i)]=bwlabel(IM2);%贴标签,n检测到的目标数量
figure,imshow(img_div);
if i>1& n(i)==n(i-1) | i==10;
break
end
branch=strel('disk',12-i);
boom=strel('disk',10);
IM2=imerode(img_div,branch);%将枝腐蚀掉
IM2=imdilate(IM2,boom);%大量膨胀
%%这里做与或运算,把叶片因为角度的暗部区域复原一下
img_div=IM2 | img_div;
figure,imshow(IM2)
end
IM2=imerode(IM2,branch);%将枝腐蚀掉,达到最终目标
figure,imshow(IM2)
[L,n]=bwlabel(IM2);%贴标签,n检测到的目标数量
%获取这些目标的范围
k=1;
Are=[];
for i=1:n
[y,x]=find(L==i);%定位到第n个目标
[xsize,~]=size(x);
%若是目标像素小于900点,且长宽比不在范围内,比值范围为2.5
if any(xsize<900) || any(((max(x)-min(x))/(max(y)-min(y)))<0.4) || any(((max(x)-min(x))/(max(y)-min(y)))>2.5 )
continue
end
Are(k,1)=min(x);
Are(k,2)=min(y);
Are(k,3)=max(x)-min(x);
Are(k,4)=max(y)-min(y);
Aimnum(k)=i;
k=k+1;
end
load('alnex_2.mat');%加载训练好的图形
[y1,x1]=size(img_orin);%输入图像的尺度
bountry=ceil(min(y1,x1)*0.02);%bountry为边界,只测试边界内的物体,靠近边缘的物体不检验
ynum=227;%训练模型的的输入尺度
xnum=227;
imshow(L,jet(n));%分开效果
%将框选的区域分割开后进行深度学习
imshow(img_orin);
hold on
for i=1:k-1
%若目标在边缘,则跳过
if Are(i,1)>bountry && Are(i,2)>bountry && (Are(i,3)+Are(i,1)+bountry)2.1:植株冠层图像的预处理:腐蚀、膨胀与判断
该部分内份的程序详细内容请参考divide_ImgContent.m,首先我们通过自定义函数T_SGM将图像进行区域阈值分割,pluse项值为80,即结构元素大小为80*80,再通过imerode()与imdilate()函数将二值图像循环腐蚀与膨胀(其中腐蚀程度随着循环次数减少,而膨胀程度不变,以保证分割不严重失真),在这一过程中由于拍摄角度照成叶片暗部导致一张叶片再图像中被分割成两个部分的效果得到了改变,复原了单一叶片的实际情况。而这一循环中断的的条件则是bwlabel()函数对图像的标签数量的判断是否和上一次循环一致,如果两次循环中label的数量一致,则说明对叶片的复原达到了目标,则退出循环。之后进行进一步腐蚀将纤细的茎区域腐蚀。
 图八:植株冠层原始图像
图八:植株冠层原始图像
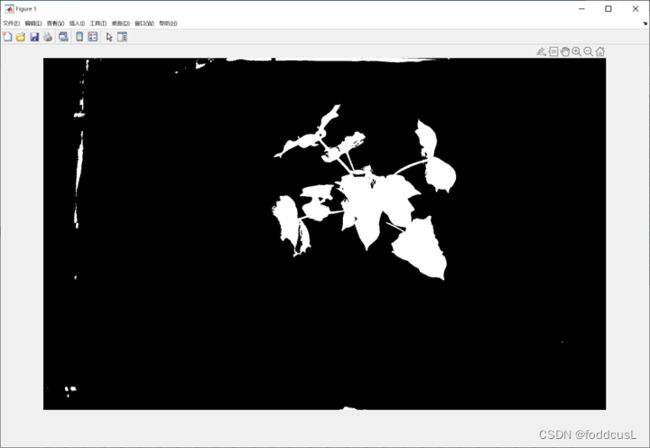 图九:阈值分割效果
图九:阈值分割效果



图十:循环腐蚀、填充后叶片区域获得联通
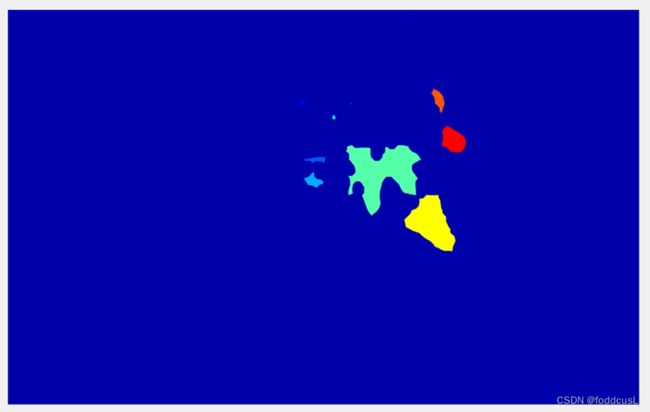
图11:腐蚀后进行标签化
2.2识别判断与显示
通过预处理后,我们通过bwlabel函数可以将图像进行标签化处理,当然其中还包含许多背景杂点,因此如程序中:使用了循环语句进行了判断,若该标签尺度小于900个像素点则判断为杂点,若其区域范围长宽比或宽长比大于2.5则说明该目标不是正常的叶片或者苞叶,可能是背景金属的反光,也被舍去。未被舍去的标签区域会通过Max与min函数(如图12所示)将该区域的坐标范围提交给深度学习模型,其中运用imresize函数将输入修改为227*227,标准的尺度,最后在讲返回的判断内容输入到rectangle函数生成的框中,如图13所示。
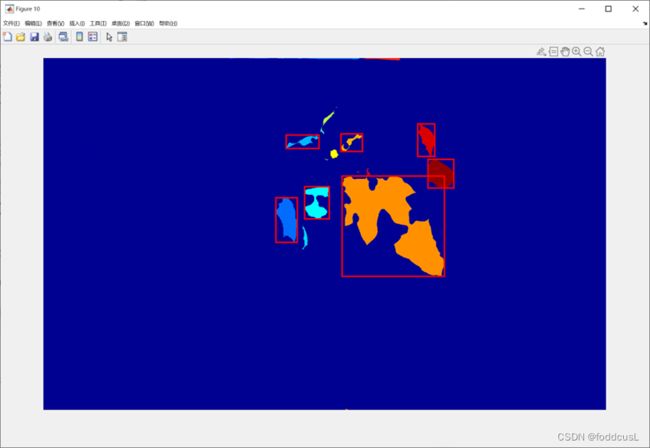
图12:调试后进行将标签的范围进行框选
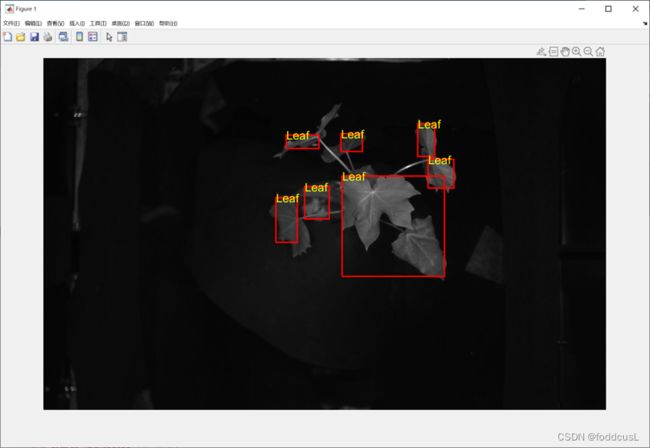 图13:配合深度学习完成识别
图13:配合深度学习完成识别
其他识别效果
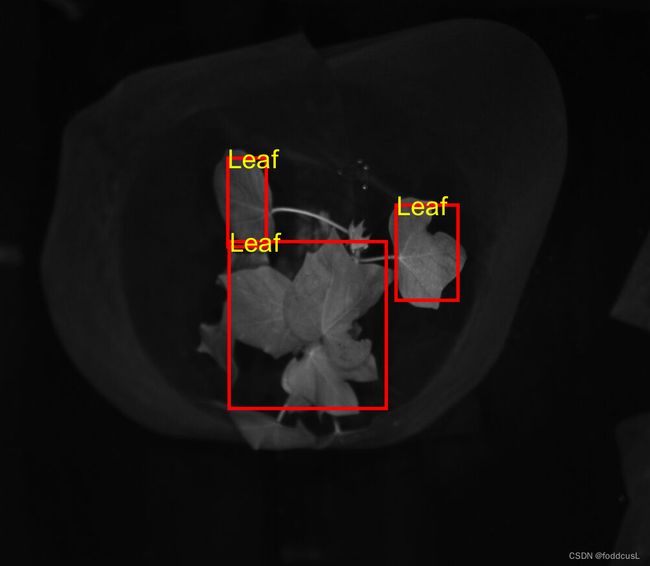



2.3关于局限性与改进的简要讨论
显然,最后的效果并不完美,只能说基本满足。该方法的局限性显然是其还是“太笨”了,叶片的重叠包括叶片的倾斜角度都会显著的影响图像分割的效果,传统的方法并不能聪明地将重叠的叶片分割开来,也不能智能地不腐蚀倾斜角度过大的叶片,这就导致很多叶片误判和漏判,并且甚至会将一个叶片分割成两部分。其次,基于时间问题,本文并没有对原始的单一叶片模型进行迁移学习。显然,图中的识别准确率并不好,摘取的叶子和苞叶的状态与植株中的状态差距太大,因此,一种方法是需要在在该模型中附加一个新的全连接层,然后用植株层面的样本对模型进行迁移学习的训练,或者直接使用YOLO模型进行分割和辨识[4];
相关参考连接与论文
1:(matlab 图像分割-自定义函数T_SGM
2:matlab自定义函数 DeleNos_dot 消除二值化图像杂点
3: Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C].Advances in neural information processing systems. 2012: 1097-1105.
4::深度学习神经网络各网络简介及资料汇总 (matlab :deep network designer )