神经网络模型的选择与优化
当一个神经网络算法表现不好时,我们需要对它进行优化。优化的方式有许多种,我们可以:
- 扩充训练集
- 减少或增加特征数量
- 减少或增加多项式次数
- 改变正则化参数λ
关键是怎么选用优化方法呢?有时候若是方向没找对,最后只会南辕北辙,离目标越来
越远。例如如果一个算法的训练样本数量少得可怜,那么你再怎么折腾算法,最后的训练结果都不会多好。接下来我们就介绍数据集大小、模型多项式次数和正则化项参数对训练误差的影响。
模型选择
首先我们要选择适合数据特点的训练模型。为此,我们将数据集分为三部分——训练集(60%)、验证集(20%)和测试集(20%)。
第一步用训练集训练参数,第二步用验证集来评估训练出的参数以优化算法,最后将测试集的测试情况视为真实应用时的情况,也就是泛化情况。许多人只将数据集分为两部分,训练集和测试集,这样优化参数和得出泛化情况都在一个数据集里面,这个进行了优化的泛化情况就会比真实情况好。如下图根据房屋大小预测房价:

接下来我们选用不同的模型对训练集进行训练得出合适的参数Θ(Θ为矩阵),将参数Θ代入模型并将此模型在验证集中进行模拟以得到误差![]() ,这里的cv下标是cost function of validation set,验证集的代价函数。最后我们选择
,这里的cv下标是cost function of validation set,验证集的代价函数。最后我们选择![]() 最小的模型即可。例如若我们要选择多项式的次数d (degree of polynomial),可以操作如下图,对不同的d在训练集上求出参数Θ,然后在验证集上模拟得到误差
最小的模型即可。例如若我们要选择多项式的次数d (degree of polynomial),可以操作如下图,对不同的d在训练集上求出参数Θ,然后在验证集上模拟得到误差![]() 并选择
并选择![]() 最小的模型。
最小的模型。
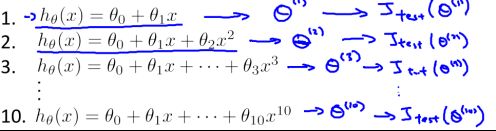
选择了模型之后,就要对模型进行优化。模型不合适时会出现两种情况——欠拟合和过拟合。欠拟合就是模型过于简单无法拟合复杂的训练数据,相反,过拟合就是模型过于复杂,很好地拟合了训练集,而在真实应用中表现较差。
数据集大小对训练结果的影响
首先判断是否扩充训练集。Banko和Brill的实验已经充分证明了数据的重要性,因此我们首先判断是否是数据不够。为了直观表示,我们可以绘制学习曲线(learning curve)。
当出现欠拟合时,若训练数据很少,在训练集上可以很容易拟和它们,随着数据增多,误差逐渐增大;在验证集上,数据很少时,模型训练不足,在应用中误差很大;随着数据增多模型误差减少,但由于模型过于简单,本身具有局限性,误差下降到一定程度就平缓了。如下图,当我们选择线性函数![]() ,那么无论如何调整
,那么无论如何调整![]() 都无法拟和这些数据点。
都无法拟和这些数据点。

因此,可绘制欠拟合的学习曲线,其特点是随着数据增长,![]() 不再下降,与
不再下降,与![]() 数值相近。可知,在欠拟合情况下收集数据的意义不大,此时改善模型较为合适。
数值相近。可知,在欠拟合情况下收集数据的意义不大,此时改善模型较为合适。

模型过拟合时,训练集上同样数据越多误差越大,在验证集上随着数据量增加误差减小,并且由于提取数据的特征多,模型局限性小,随着数据量增加误差会持续减小(只要模型足够复杂)。这种情况下,收集更多的数据就有用了。

多项式次数对训练结果的影响
显而易见,模型多项式次数越低,模型越简单,![]() 越大,容易出现欠拟合;模型多项式次数越高,模型越复杂,容易出现过拟合,
越大,容易出现欠拟合;模型多项式次数越高,模型越复杂,容易出现过拟合,![]() 越大,如下图所示。
越大,如下图所示。

因此可根据![]() 的表现判断模型多项式次数过大还是过小——若都很大,则说明模型欠拟合,应该增加多项式次数;若
的表现判断模型多项式次数过大还是过小——若都很大,则说明模型欠拟合,应该增加多项式次数;若![]() ,
,![]() 说明出现了过拟合,应该减小多项式次数。
说明出现了过拟合,应该减小多项式次数。
正则化项参数λ的选择
大多数情况下我们需要选择复杂的网络,复杂网络可以通过正则化改善表现,而简单网络存在的结构性劣势很难改善,由上述可知。复杂的网络隐藏层和神经单元很多,通常我们都会加入正则化项避免过拟合,这时λ的选择就很重要了。如下图所示,当λ过大,对于参数惩罚很大,此时各个参数接近零模型接近与平行线,会出现欠拟合,因为模型过于简单,对训练集和验证集拟合都较差;当λ很时,对于参数的惩罚不足,参数值没有改变,此时的正则项没有解决过拟合的问题,训练集上的误差非常小,而泛化误差很大。

因此我们得到了![]() 随λ变化的曲线如下图,若
随λ变化的曲线如下图,若![]() 大很多,则说明模型过拟合,
大很多,则说明模型过拟合,![]() 都很大,说明出现了欠拟合,我们需要调整λ以取得中间那个合适的点让
都很大,说明出现了欠拟合,我们需要调整λ以取得中间那个合适的点让![]() 最小。
最小。
综上可得,当训练结果欠拟合,可以增加特征数、增加多项式次数或者减小正则项系数λ;过拟合时可以减少特征数、扩大训练数据集或增大则项系数λ。
在实际应用中,一定要将模型运行一次通过运行结果来判断采取什么优化措施,而不是想当然地去扩大数据集,这样太浪费时间。事实指导实践而不是感觉指导实践。
不对称分类的误差评估
若某个罕见病的发病率为0.4%,我们训练出了一个模型检查病人是否有该病,准确率为99.5%。那么我们何不直接预测所有病人都没患病,这样准确率0.4%大于模型查准率0.5%?这样显然是不行的。
因此对于这种发生概率很小的不对称类 (skewed class),我们需要另外的方法评价算法的误差,而不是简单的准确率。
为此学者们提出了查准率和查全率(Precision and Recall)。
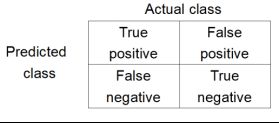
如下图,true positive表示病人患病并且查出患病,false positive表示病人没患病却查出患病;false negative表示病人没患病却查出患病,true negative表示病人没患病并且查出没患病。
查准率(precision)表示:病人生病并且查出生病了的概率:

查全率(recall)表示:生病的人查出生病的概率。

我们可以根据实际需求对两个参数进行权衡。比如你不想吓到体检的人,就降低模型阈值,只有较为确定才判断ta生病了,这样查准率提高了;如果你不希望漏掉太多生病的人,就降低判断有病的阈值,只要有疾病苗头的就会被判断生病了,这样查全率就提高了。
通过Precision and Recall就可以衡量不对称类的表现,但是两个参数确实没有一个参数直观,那么我们要将Precision and Recall综合成一个参数—— 。查重率与查全率越高,F1越大;并且,如果P(precision)和R(recall)中有一项为0那么F1就为0,避免了开头所说的全部记为0或1的情况。
。查重率与查全率越高,F1越大;并且,如果P(precision)和R(recall)中有一项为0那么F1就为0,避免了开头所说的全部记为0或1的情况。