VOC格式数据集转yolo(darknet)格式
一、前言
在上一篇文章中我们已经了解了VOC数据集的组织格式,如果我们想要训练自己的数据集,那么就可以按照VOC的格式来组织你的数据。
当然可能需要借助一些工具,这个以后有机会再说!!!
但是,官方的darknet版本的yolov3、yolov4所需的数据格式并不是这样的,我们还需要做一些转换。但是好消息是,我们可以利用一些python脚本来帮助我们快速完成格式转换!!!
二、yolo的数据格式
前面说到,yolo的数据格式和voc的有一些不同,主要体现在类别和坐标信息的组织形式不同,也即前者并不是直接使用上一篇文章中说到的.xml文件读取数据,而是使用以一定格式保存类别和坐标信息的.txt文件来读取数据。那么yolo保存类别和坐标信息的格式具体是怎样的呢?见下图:

一个
.txt对应一张图片,并且它们的名字是一样的。
一行对应一个物体,第一部分是class_id,后面四个数分别是
BoundingBox的(中心x坐标,中心y坐标,宽,高)。这些坐标都是 0~1 的相对坐标。
三、格式转换
那么既然voc中label部分的数据格式和yolo中的不一样,那么我们就需要转换一下,我们可以使用官方提供的voc_label.py来实现转换。下面就来简单说一下我们应该注意些什么!!!
1、 首先假设,在此之前你已经获取到了voc的数据集,并且存放在了VOCdevkit文件夹下面。在此文件夹下面会存在VOC2007子文件夹或者VOC2012子文件夹或者两者都有。在VOC2007和VOC2012下面存放的就是上一篇文章中说的Annotations、ImageSets和JPEGImages等子文件夹了。(注意,下载的时候训练验证、测试的数据集是分开的,但是它们的图片名称以及xml文件名称都是连续的,也即互相之前没有重名的,所以直接混在一起就是所有的图片。所以如果想要一次性转换全部的train、val以及test数据,就直接将下载的测试数据集中同名文件夹下的文件都拷贝到训练验证数据集中的同名文件夹里即可。)
其实Main文件夹下其他的文件用不到,直接只保留下图中的这些文件也是可以的。

2、 将 voc_label.py脚本文件和你的VOCdevkit文件夹放在同一级路径下。
3、 根据实际情况修改代码:
- 首先是
sets:你应该根据代码中使用到sets的地方,例如下面这段代码来理解你的sets里面应该设置些什么值,其实是和你的文件夹的名字以及路径密切相关。
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'
%(year, image_set)).read().strip().split()
因为我的VOCdevkit文件下只有一个VOC2007子文件夹,并且在VOCdevkit/VOC2007/ImageSets/Main路径下有train.txt、val.txt和test.txt文件,存放的分别是所有类(或者说所有图片)中用于训练、验证和测试的图片的名字。所以,我的sets设置成了sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]。
- 其次是
classes:这里就是你的数据集中包含的各种类别。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'),('2007', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'
%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'
%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
4、 运行 voc_label.py,最后会在VOCdevkit文件夹的同级目录下生成2007_train.txt,2007_val.txt,2007_test.txt,并且会在VOCdevkit/VOC2007路径下生成一个label文件夹。


那么上面生成的几个文件,里面的具体内容是啥呢?
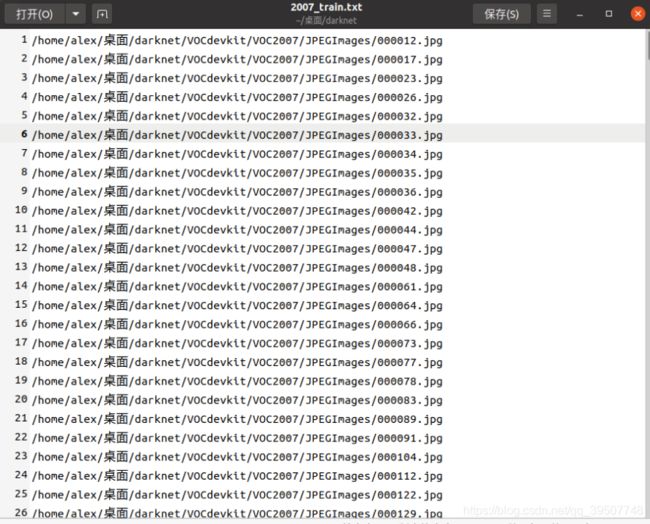
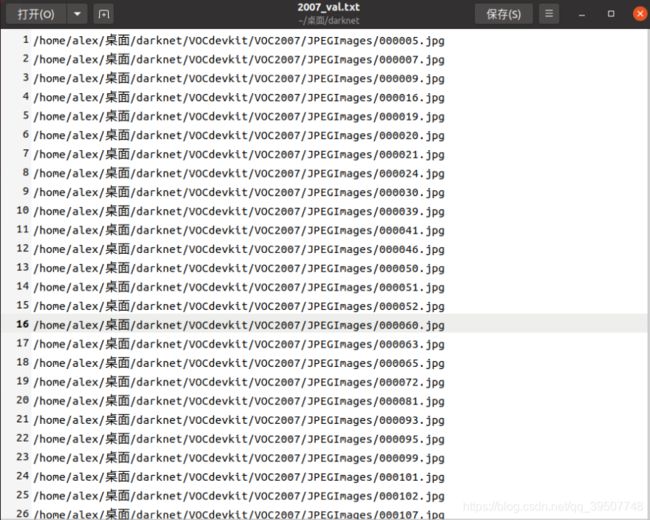
2007_train.txt,2007_val.txt,2007_test.txt
如下所示,里面存放的是train.txt、val.txt、test.txt中存放的图片的文件名的全路径。也即和train.txt、val.txt、test.txt相比,只是把里面存放的图片名字变成了全路径,其他的无论在个数以及对应的图片都是完全相同的。

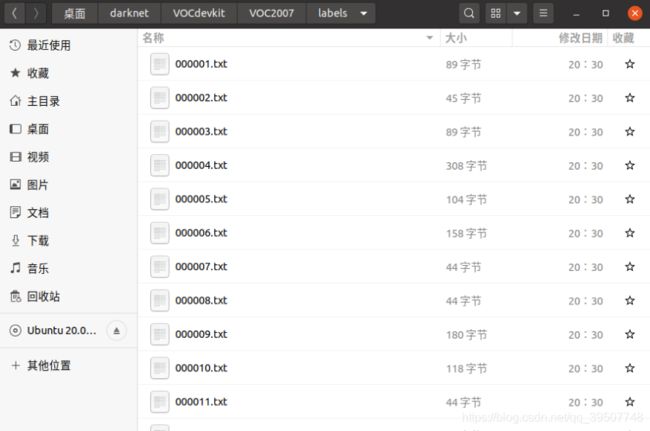
labels文件夹
该文件夹下面存放的.txt文件对应着所有的图片(训练+验证+测试),一个图片一个文件,并且名字都是一样的。每个文件里的存放的就是类别和坐标信息,如下所示。
四、总结
我们已经知道通过voc_label.py将VOC格式的数据集转换成yolo格式生成了一些新的,重新组织的文件,那么这些文件应该怎么使用呢?关于如何使用它们进行训练,还是等到下一篇文章再说吧!希望以上内容可以帮助到你!