PYQT5+CNN(TensorFlow-keras)做一个简单的手写数字识别PC端图形化小程序
目录
前言
一、功能介绍
1.画板识别
2.图片识别
二、UI设计
1.整体设计思想
2.颜色设计
3.Logo 设计
4.按钮设计
三、算法介绍
1.图片预处理
2.数字分割和显示
3.识别算法
4.UI搭建
四、代码及架构
1.配置环境
2、代码结构
1、main
2、Tan
3、Run
4、predict
5、train
6、tarin_new
3、全部代码
1、main
2、Tan
3、Run
4、predict
5、train
6、tarin_new
总结
1.一些不足之处
2.界面和交互
3.网络搭建
4.深度学习算法设计与评估基本步骤总结
前言
这个其实是我上学期多媒体课的大作业(本文译自实验报告233),综合了网上一些零碎资料,谨以记录学习经历,如有错漏、不完善之处,请多多指正!
ps:文章框架参考了两篇博客,但是写的时候有点找不到了ORZ,要是有人发现雷同,帮忙找到文章,我会标记到文末,感激!
一、功能介绍
1.画板识别
![]()
(2)在“画板”模块处可以进行鼠标绘制,绘制时接近画板中央会效果更好

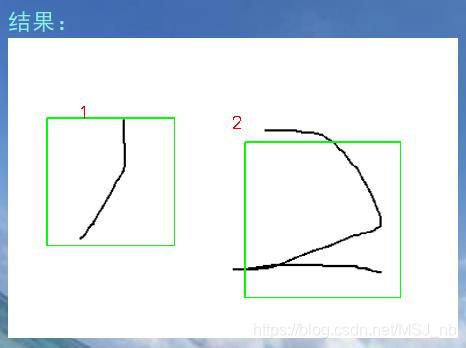
(4)点击按钮“画板擦除”即可清空“画板”模块。
2.图片识别


二、UI设计
1.整体设计思想

2.颜色设计
3.Logo 设计

4.按钮设计

三、算法介绍
1.图片预处理
代码如下:
image = cv2.resize(img, (960, 640), interpolation=cv2.INTER_LINEAR)
# 将这帧转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
retval, binary = cv2.threshold(gray, 90, 255, cv2.THRESH_BINARY_INV)
# 放大所有轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
cv2.drawContours(binary, contours, i, (255, 255, 255), 5)
# 过滤噪声点
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
perimeter = cv2.arcLength(contours[i], False)
if perimeter < 100:
# print(s)
cv2.drawContours(binary, contours, i, (0, 0, 0), 15)
# cv2.imshow('binary_f', binary)
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)2.数字分割和显示
代码如下:
for i in range(len(contours)):
M = cv2.moments(contours[i])# 找到中心点
if M['m00'] != 0:
cx = int(M['m10'] / M['m00'])
cy = int(M['m01'] / M['m00'])
x, y, w, h = cv2.boundingRect(contours[i])
pad = max(w, h) + 10
# 画出绿色框图
cv2.rectangle(image, (cx - pad // 2, cy - pad // 2), (cx + pad // 2, cy + pad // 2), (0, 255, 0), thickness=2)
# 进行预测
if cy - pad // 2 >= 0 and cx - pad // 2 >= 0:
number_i = (binary[cy - pad // 2:cy + pad // 2, cx - pad // 2:cx + pad // 2])
number_i = cv2.resize(number_i, (28, 28))
if model_x == 1:
number_i = np.reshape(number_i, (-1, 28, 28, 1)).astype('float')
else:
number_i = number_i.reshape(1, 784).astype('float32')
#将结果红色显示在框上
result = number_predict(number_i, model, model_x)
cv2.putText(image, str(result[0]), org=(x, y), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1.2,
color=(0, 0, 255), thickness=2)3.识别算法
ps:除了CNN其实都是调的sklearn库保存的模型


4.UI搭建
ps:因为做这个的时候第一次接触qt,所以没有用图形化界面而是找了个框架自己边学边改手撕的界面QAQ
1、Tan类,继承PYQT5的QWidget类
(1)设置主体框架大小和出现位置等基本参数,将l图标和背景置为自选图片
(2)添加logo、各个按钮、画板、结果显示、文字提示等控件,并copy模板略微美化界面
(3)图片识别和画板识别用同一个逻辑,截图或者直接选取图片,然后调用RUN函数用选中的模型进行预处理和预测得到结果,功能函数分别和两个按钮的鼠标点击事件连接
2、MyLabel类,继承PYQT5的QLabel类,主要是为了在背景图片上还能写字(可能方法比较蠢)
(1)定义一个事件函数,记录鼠标位置,用来写字
(2)定义一个擦除画板功能,和对应按钮鼠标点击事件连接
四、代码及架构
1.配置环境
keras 2.4.3 PyQt5 5.15.4
numpy 1.19.5 TensorFlow 2.5.0
opencv-python 4.5.2.52
pyscreenshot 3.0 joblib 1.0.1
sklearn 0.0
2、代码结构
1、main
调用界面
2、Tan
界面逻辑和交互
3、Run
图片预处理、预测及生成结果图片
4、predict
读入图片归一化、根据参数选择预测模型预测函数
5、train
CNN训练并保存模型
6、tarin_new
sklearn库函数模型训练、比较和保存
3、全部代码
1、main
import sys
from PyQt5.QtWidgets import QApplication
from Tan import Tan
if __name__ == "__main__":
app = QApplication(sys.argv)
mymnist = Tan() # 调用Tan中GUI
mymnist.show()
app.exec_()2、Tan
# --coding:utf-8--
from PyQt5.QtWidgets import (QWidget, QPushButton, QLabel, QComboBox, QFileDialog)
from PyQt5.QtGui import (QPainter, QPen, QFont)
from PyQt5.QtCore import Qt
from PyQt5 import QtGui
from PyQt5.Qt import QIcon
from PyQt5.QtCore import *
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from PyQt5.Qt import QDir, QIcon
from PyQt5.QtGui import QPixmap
import sys
from PIL import Image
import os
import pyscreenshot as ImageGrab
import Run
import cv2
import numpy
def is_chinese(string):
"""
检查整个字符串是否包含中文
:param string: 需要检查的字符串
:return: bool
"""
for ch in string:
if u'\u4e00' <= ch <= u'\u9fff':
return True
return False
class MyLabel(QLabel):
pos_xy=[]
def paintEvent(self, event):
painter = QPainter()
painter.begin(self)
#pen = QPen(Qt.black, int(self.huabi.currentText()), Qt.SolidLine) # 画笔尺寸 颜色
painter.setPen(QPen(Qt.black, 2, Qt.SolidLine))
if len(self.pos_xy) > 1:
point_start = self.pos_xy[0]
for pos_tmp in self.pos_xy:
point_end = pos_tmp
if point_end == (-1, -1):
point_start = (-1, -1)
continue
if point_start == (-1, -1):
point_start = point_end
continue
painter.drawLine(point_start[0], point_start[1], point_end[0], point_end[1])
point_start = point_end
painter.end()
# 记录鼠标点下的点,添加到pos_xy列表
def mouseMoveEvent(self, event):
pos_tmp = (event.pos().x(), event.pos().y())
self.pos_xy.append(pos_tmp)
self.update()
# 鼠标释放,在pos_xy中添加断点
def mouseReleaseEvent(self, event):
pos_test = (-1, -1)
self.pos_xy.append(pos_test)
#绘制事件
def btn_clear_on_clicked(self):
self.pos_xy = []
self.setText('')
self.update()
# 界面
class Tan(QWidget):
def __init__(self):
super(Tan, self).__init__()
self.resize(654, 768) # 外围边框大小
self.move(550, 95) # 设置位置
self.setWindowTitle('手写数字识别') # 标题
self.setMouseTracking(False) # False代表不按下鼠标则不追踪鼠标事件
self.pos_xy = [] # 保存鼠标移动过的点
# 添加控件
#窗口图标
self.setWindowIcon(QIcon('bluesky.jpg'))
#窗口背景
self.echoLabel = QLabel(self)
self.echoLabel.setGeometry(160, 0, 903, 768)
self.pixmap = QPixmap("bluesky.jpg") # 按指定路径找到图片
self.echoLabel.setPixmap(self.pixmap) # 在label上显示图片
self.echoLabel.setScaledContents(True) # 让图片自适应label大小
# logo
self.logoLabel = QLabel(self)
self.logoLabel.setGeometry(-80, -50, 319, 220)
self.pixmap1 = QPixmap("logo.png") # 按指定路径找到图片
self.logoLabel.setPixmap(self.pixmap1) # 在label上显示图片
self.logoLabel.setScaledContents(True) # 让图片自适应label大小
# 画板文字
self.label_draw_name = QLabel(('''画板:'''), self)
self.label_draw_name.setGeometry(180, 15, 70, 30)
# 画板区域
self.label_draw = MyLabel('', self)
self.label_draw.setGeometry(180, 45, 450, 300)
self.label_draw.setStyleSheet("QLabel{border:1px solid white;background-color: #FFFFFF}")
self.label_draw.setAlignment(Qt.AlignCenter)
# 图片结果文字
self.label_result_name = QLabel('''结果:''', self)
self.label_result_name.setGeometry(180, 410, 70, 30)
self.label_result_name.setAlignment(Qt.AlignCenter)
# 图片结果区域
self.label_result1 = QLabel(' ', self)
self.label_result1.setGeometry(180, 440, 450, 300)
self.label_result1.setStyleSheet("QLabel{border:1px solid white;background-color: #FFFFFF}")
self.label_result1.setAlignment(Qt.AlignCenter)
# 识别按钮,跳转到 reco 方法
self.btn_recognize = QPushButton('画板识别', self)
self.btn_recognize.setGeometry(6, 210, 60, 50)
self.btn_recognize.setStyleSheet('''
background-color: #87CEFA ;
height:30px;
border-style: outset;
border-width: 2px;
border-radius: 20px;
border-color: beige;
font: bold 12 px;
min-width: 9em;
padding: 5px;
''')
self.btn_recognize.clicked.connect(self.reco)
# 选择上传图片
self.btn_clear = QPushButton("图片识别", self)
self.btn_clear.setGeometry(6, 510, 60, 50)
self.btn_clear.clicked.connect(self.open_file)
self.btn_clear.setStyleSheet('''
background-color: #87CEFA ;
height:30px;
border-style: outset;
border-width: 2px;
border-radius: 20px;
border-color: beige;
font: bold 12 px;
min-width: 9em;
padding: 5px;
''')
# 清空所写数字
self.btn_clear = QPushButton("擦除画板", self)
self.btn_clear.setGeometry(6, 360, 60, 50)
self.btn_clear.clicked.connect(self.label_draw.btn_clear_on_clicked)
self.btn_clear.setStyleSheet('''
background-color: #87CEFA ;
height:30px;
border-style: outset;
border-width: 2px;
border-radius: 20px;
border-color: beige;
font: bold 12 px;
min-width: 9em;
padding: 5px;
''')
# 识别模式
self.moshi = QComboBox(self)
self.moshi.addItems(['CNN', "RandomForest", "KNeighbors", "DecisionTree"])
self.moshi.setGeometry(30, 650, 100, 30)
self.moshi.setStyleSheet('''
background-color: #87CEFA ;
''')
# 识别函数
def reco(self):
bbox = (self.x()+183, self.y()+83, 1180, 470) # 设置截屏位置
im = ImageGrab.grab(bbox) # 截屏
im.save("now.png")
img = cv2.imread("now.png")
if self.moshi.currentText() == "CNN":
Run.Run(img, 1) # 调用Run中'CNN'方法对所截图img进行处理
if self.moshi.currentText() == "RandomForest":
Run.Run(img, 2) # 调用Run中'RandomForest'方法对所截图img进行处理
if self.moshi.currentText() == "KNeighbors":
Run.Run(img, 3) # 调用Run中'KNeighbors'方法对所截图img进行处理
if self.moshi.currentText() == "DecisionTree":
Run.Run(img, 4) # 调用Run中'DecisionTree'方法对所截图img进行处理
self.label_result1.setPixmap(
QtGui.QPixmap('img.png').scaled(self.label_result1.width(), self.label_result1.height())) # 在label_result1中显示图片
self.update()
def open_file(self):
imgName, imgType = QFileDialog.getOpenFileName(self, "选择一张图片", "", "*.jpg;;*.png;;All Files(*)")
if imgName == "":
return
if is_chinese(imgName):
s = imgName.split('/')[-1]
else:
s = imgName
img = cv2.imread(s)
if self.moshi .currentText() == "CNN":
Run.Run(img, 1) # 调用Run中'CNN'方法对所截图img进行处理
if self.moshi .currentText() == "RandomForest":
Run.Run(img, 2) # 调用Run中'RandomForest'方法对所截图img进行处理
if self.moshi .currentText() == "KNeighbors":
Run.Run(img, 3) # 调用Run中'KNeighbors'方法对所截图img进行处理
if self.moshi .currentText() == "DecisionTree":
Run.Run(img, 4) # 调用Run中'DecisionTree'方法对所截图img进行处理
self.label_result1.setPixmap(
QtGui.QPixmap('img.png').scaled(self.label_result1.width(), self.label_result1.height())) # 在label_result1中显示图片
self.update()
3、Run
import cv2
import numpy as np
import matplotlib.pyplot as plt
from keras.models import load_model
from predict import *
import joblib
def Run(img,model_x):
"""
:param img: 输入图像矩阵
:excute 将标注好的图片存入根目录,命名为“img.png”
"""
# 载入训练好的模型
if model_x == 1:
model = load_model('net1')
if model_x == 2:
model = joblib.load("RandomForest.pkl")
if model_x == 3:
model = joblib.load("KNeighbors.pkl")
if model_x == 4:
model = joblib.load("DecisionTree.pkl")
image = cv2.resize(img, (960, 640), interpolation=cv2.INTER_LINEAR)
# 将这帧转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
retval, binary = cv2.threshold(gray, 90, 255, cv2.THRESH_BINARY_INV)
# 放大所有轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
cv2.drawContours(binary, contours, i, (255, 255, 255), 5)
# 过滤噪声点
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
perimeter = cv2.arcLength(contours[i], False)
if perimeter < 100:
# print(s)
cv2.drawContours(binary, contours, i, (0, 0, 0), 15)
# cv2.imshow('binary_f', binary)
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#print(len(contours))
# 遍历整个图片每个轮廓
for i in range(len(contours)):
M = cv2.moments(contours[i])# 找到中心点
if M['m00'] != 0:
cx = int(M['m10'] / M['m00'])
cy = int(M['m01'] / M['m00'])
x, y, w, h = cv2.boundingRect(contours[i])
pad = max(w, h) + 10
# 画出绿色框图
cv2.rectangle(image, (cx - pad // 2, cy - pad // 2), (cx + pad // 2, cy + pad // 2), (0, 255, 0), thickness=2)
# 进行预测
if cy - pad // 2 >= 0 and cx - pad // 2 >= 0:
number_i = (binary[cy - pad // 2:cy + pad // 2, cx - pad // 2:cx + pad // 2])
number_i = cv2.resize(number_i, (28, 28))
if model_x == 1:
number_i = np.reshape(number_i, (-1, 28, 28, 1)).astype('float')
else:
number_i = number_i.reshape(1, 784).astype('float32')
#将结果红色显示在框上
result = number_predict(number_i, model, model_x)
cv2.putText(image, str(result[0]), org=(x, y), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1.2,
color=(0, 0, 255), thickness=2)
cv2.imwrite('img.png', image)
return 0
#cv2.waitKey()
#cv2.destroyAllWindows()
4、predict
def number_predict(img, model, k):
# 图像处理
img = img / 255.0
# 预测
if k == 1:
result = model.predict_classes(img)
else:
result = model.predict(img)
return result
5、train
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import matplotlib.pyplot as plt
import numpy as np
from keras.utils import np_utils
batch_size = 128
num_classes = 10
epochs = 10
path = 'mnist_data/mnist.npz'
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
x_train = x_train.reshape(60000, 28, 28, 1).astype('float32')
x_test = x_test.reshape(10000, 28, 28, 1).astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
# label为0~9共10个类别,keras要求格式为binary class matrices
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
# 卷积模型
model = Sequential()
model.add(Conv2D(filters=16,
kernel_size=(5, 5),
padding='same',
input_shape=(28,28,1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=36,
kernel_size=(5, 5),
padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
#model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.summary()
# 损失函数使用交叉熵
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
# 模型训练
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Total loss on Test Set:', score[0])
print('Accuracy of Testing Set:', score[1])
# 模型保存
model.save('./net1.pkl')
6、tarin_new
import numpy as np
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import BernoulliNB
from sklearn.model_selection import StratifiedKFold
import joblib
path = 'mnist_data/mnist.npz'
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
x_train = x_train.reshape(60000, 784).astype('float32')
x_test = x_test.reshape(10000, 784).astype('float32')
x_train /= 255
x_test /= 255
clf5 = MultinomialNB()
clf5.fit(x_train, y_train)
joblib.dump(clf5, "MultinomialNB().pkl")
classifierResult = clf5.predict(x_test)
mTest = len(x_test)
errorCount = 0.0 ## 统计识别错误的样本个数
for i in range(mTest):
if classifierResult[i] != y_test[i]:
errorCount += 1.0
print("\t 测试样本个数为: %d " % mTest)
print("\t 预测错误个数为: %d " % errorCount)
print("\t 预测错误率为: %2.2f%% " % (errorCount/float(mTest)*100))
print("\t 预测准确率为: %2.2f%%" % ((1-errorCount/float(mTest))*100))
'''
clf = KNeighborsClassifier(algorithm='kd_tree', n_neighbors=10)
clf.fit(x_train, y_train)
joblib.dump(clf, "KNeighbors.pkl")
clf2 = RandomForestClassifier()
clf2.fit(x_train, y_train)
joblib.dump(clf2, "RandomForest.pkl")
clf1 = DecisionTreeClassifier(criterion='entropy', random_state=0)
clf1.fit(x_train, y_train)
joblib.dump(clf1, "DecisionTree.pkl")
clf3 = GaussianNB()
clf3.fit(x_train, y_train)
joblib.dump(clf3, "GaussianNB.pkl")
clf4 = BernoulliNB()
clf4.fit(x_train, y_train)
joblib.dump(clf4, "BernoulliNB.pkl")
clf5 = MultinomialNB()
clf5.fit(x_train, y_train)
joblib.dump(clf5, "MultinomialNB().pkl")
clf = joblib.load("RandomForest.pkl")
classifierResult = clf.predict(x_test)
mTest = len(x_test)
errorCount = 0.0 ## 统计识别错误的样本个数
for i in range(mTest):
if classifierResult[i] != y_test[i]:
errorCount += 1.0
print("\t 测试样本个数为: %d " % mTest)
print("\t 预测错误个数为: %d " % errorCount)
print("\t 预测错误率为: %2.2f%% " % (errorCount/float(mTest)*100))
print("\t 预测准确率为: %2.2f%%" % ((1-errorCount/float(mTest))*100))
'''
总结
1.一些不足之处
ps:有兴致和空闲再进行修改(估计是不会改了,滑稽.jpg
另外我尝试了用pyinstaller进行打包,但是不知道是不是含有qt库,打包出来贼大(好几百M),.dll文件贼多,有兴趣的小伙伴可以自己尝试
2.界面和交互
3.网络搭建
4.深度学习算法设计与评估基本步骤总结
ps:最近在考虑将抽空将正在学习的数据挖掘、深度学习、强化学习、计算机视觉等内容的基础知识整理来发博客,不过要准备考研估计得等很久以后了