DALL·E 2 解读 | 结合预训练CLIP和扩散模型实现文本-图像生成

目录
一、导读
论文信息
CLIP(打通文本-图像模型)相关讲解:
扩散模型Diffusion Model相关讲解:
二、DALL·E 2 模型解读
DALL·E 2 模型总览
DALL·E 2 训练过程
DALL·E 2 推理过程(由文本生成图像过程)
三、DALL·E 2实验效果和不足之处
实验效果
不足之处
Reference
一、导读

论文信息
- 论文标题: 《Hierarchical Text-Conditional Image Generation with CLIP Latents》
- 作者/单位:Aditya Ramesh et al. / Open AI
- 论文链接: http://arxiv.org/abs/2204.06125
- 代码链接: 非官方实现 https://github.com/lucidrains/DALLE2-pytorch (OpenAI官方实现待更新)
- 项目主页: 待更新
CLIP(打通文本-图像模型)相关讲解:
- 详解CLIP (一) | 打通文本-图像预训练实现ImageNet的zero-shot分类,比肩全监督训练的ResNet50/101
- 详解CLIP (二) | 简易使用CLIP-PyTorch预训练模型进行图像预测
- 小小将:神器CLIP:连接文本和图像,打造可迁移的视觉模型
- 徐土豆:CLIP-对比图文多模态预训练的读后感
- 如何评价OpenAI最新的工作CLIP:连接文本和图像,zero shot效果堪比ResNet50?
扩散模型Diffusion Model相关讲解:
- Jonathan Ho et al.“Denoising diffusion probabilistic models.” arxiv Preprint arxiv:2006.11239 (2020).
- xjtupanda:DDPM:Denoising Diffusion Probabiblistic Model 去噪扩散概率模型学习笔记
- 理想主义者:生成模型(四):扩散模型
二、DALL·E 2 模型解读

使用DALL·E 2 从文字(图片下方)生成对应的图像
DALL·E 2 模型总览
DALL·E 2 这个模型的任务很简单:输入文本text,生成与文本高度对应的图片。
它主要包括三个部分:CLIP,先验模块prior和img decoder。其中CLIP又包含text encoder和img encoder。(在看DALL·E 2之前强烈建议先搞懂CLIP模型的训练和运作机制)

DALL·E 2 模型框架总览。虚线上方:训练CLIP过程;虚线下方:由文本生成图像过程
DALL·E 2 训练过程
DALL·E 2是将其子模块分开训练的,最后将这些训练好的子模块拼接在一起,最后实现由文本生成图像的功能。
1. 训练CLIP,使其能够编码文本和对应图像
这一步是与CLIP模型的训练方式完全一样的,目的是能够得到训练好的text encoder和img encoder。这么一来,文本和图像都可以被编码到相应的特征空间。对应上图中的虚线以上部分。
2. 训练prior,使文本编码可以转换为图像编码
论文中对于该步骤作用的解释为:
A prior P(zi|y) that produces CLIP image embeddings zi conditioned on captions y .
实际的训练过程为:将CLIP中训练好的text encoder拿出来,输入文本y,得到文本编码zt。同样的,将CLIP中训练好的img encoder拿出来,输入图像 x 得到图像编码zi。我们希望prior能从zt获取相对应的zi。假设zt经过prior输出的特征为zi′,那么我们自然希望zi′与zi越接近越好,这样来更新我们的prior模块。最终训练好的prior,将与CLIP的text encoder串联起来,它们可以根据我们的输入文本y生成对应的图像编码特征zi了。关于具体如何训练prior,有兴趣的小伙伴可以精度一下原文,作者使用了主成分分析法PCA来提升训练的稳定性。
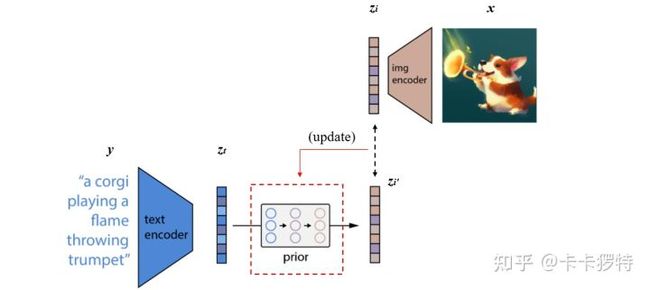
prior训练过程
在DALL·E 2 模型中,作者团队尝试了两种先验模型:自回归式Autoregressive (AR) prior 和扩散模型Diffusion prior [1]。实验效果上发现两种模型的性能相似,而因为扩散模型效率较高,因此最终选择了扩散模型作为prior模块。本文不具体解释扩散模型,大家可以查阅参考博文,或者我后期再整理相关知识。
3. 训练decoder生成最终的图像
论文中对于该步骤作用的解释为:
A decoder P(x|zi,y) that produces images x conditioned on CLIP image embeddingszi (and optionally text captions y ).
也就是说我们要训练decoder模块,从图像特征zi还原出真实的图像 x ,如下图左边所示。这个过程与自编码器类似,从中间特征层还原出输入图像,但又不完全一样。我们需要生成出的图像,只需要保持原始图像的显著特征就可以了,这样以便于多样化生成,例如下图右边的示例。

左:训练decoder的过程。右:图像经过img encoder再经decoder得到重建图像。顶部图像为输入。
DALL-E 2使用的是改进的GLIDE模型 [2]。这个模型可以根据CLIP图像编码的zi,还原出具有相同与 x 有相同语义,而又不是与 x 完全一致的图像。
DALL·E 2 推理过程(由文本生成图像过程)
经过以上三个步骤的训练,已经可以完成DALL·E 2预训练模型的搭建了。我们这事丢掉CLIP中的img encoder,留下CLIP中的text encoder,以及新训练好的prior和decoder。这么一来流程自然很清晰了:由text encoder将文本进行编码,再由prior将文本编码转换为图像编码,最后由decoder进行解码生成图像。

DALL·E 2 推理过程
三、DALL·E 2实验效果和不足之处
实验效果
看下DALL·E 2 在MS-COCO prompts上的生成效果:

DALL·E 2 在MS-COCO prompts上的生成效果
不足之处
本文作者提到了DALL·E 2的三个不足之处:
- DALL·E 2 容易将物体和属性混淆,比如下图 DALL·E 2(unCLIP) 与GLIDE的对比。提示的文字为:“a red cube on top of a blue cube”。

DALL·E 2与GLIDE由“a red cube on top of a blue cube”生成的图像
DALL·E 2 不容易将红色和蓝色分辨出来。这可能来源于CLIP的embedding过程没有将属性绑定到物体上;并且decoder的重建过程也经常混淆属性和物体,如下图所示,例如中间的柯基图片,有的重建结果将其帽子和领结的颜色搞反了。

decoder经常混淆属性和物体
2. DALL·E 2对于将文本放入图像中的能力不足,如下图所示,我们希望得到一个写着deep learning的标志,而标志却将单词/词组拼写得很离谱。这个问题可能来源于CLIP embedding不能精确地从输入地文本提取出“拼写”信息。

DALL·E 2由“A sign that says deep learning.”生成的图像
3.DALL·E 2 在生成复杂场景图片时,对细节处理有缺陷,如下图所示生成Times Square的高质量图片。这个可能来源于decoder的分层(hierarchy)结构,先生成64 × 64的图像,再逐步上采样得到最终结果的。如果将decoder先生成的图像分辨率提高,比如从64 × 64提升到128 × 128,那么这个问题可能可以缓解,但要付出更大计算量和训练成本的代价。

DALL·E 2由“A high quality photo of Times Square.”生成的图像
待更新内容:代码实现以及上手使用(OpenAI仍未开源,目前可先使用非官方实现代码)
Reference
[1] Denoising diffusion probabilistic models
[2] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.