Keras的Adam优化器decay理解及自适应学习率
Adam优化器是目前应用最多的优化器,在训练的过程中我们有时会让学习率随着训练过程自动修改,以便加快训练,提高模型性能。关于adam优化器的具体实现过程可以参考这篇博客,或者更简洁一点的这篇博客,这里我只想简单介绍一下adam优化器里decay的原理。
Adam in Keras
在Keras的Adam优化器中各参数如下:
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
lr: 学习率beta_1: 0到1之间,一般接近于1beta_2: 0到1之间,一般接近于1,和beta_1一样,使用默认的就好epsilon: 模糊因子,如果为空,默认为k.epsilon()decay: 学习率随每次更新进行衰减amsgrad: 布尔型,是否使用AMSGrad变体
下面我们来看看decay是如何发挥作用的:
if self.initial_decay > 0:
lr = lr * (1. / (1. + self.decay * K.cast(self.iterations,K.dtype(self.decay))))
为了更好的观察学习率的衰减情况,我们将学习率lr的衰减过程画出来,lr取0.01,decay取0.01
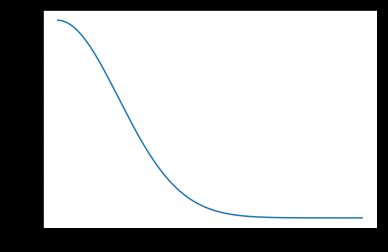
lr=0.01,decacy=0.0001,iterations=500
从图中可以看到学习率会随着迭代次数增加而逐渐减小,这样可以在训练初期加快训练。