Deformable DETR
目录
- 一、Deformable Convolution原理分析
- Deformable DETR 原理分析
-
- Deformable Attention Module
-
- Multi-scale Deformable Attention Module
一、Deformable Convolution原理分析
Deformable Convolution 将固定形状的卷积过程改造成了能适应物体形状的可变的卷积过程,从而使结构适应物体形变的能力更强。
传统的CNN卷积核是固定大小的,只能在固定为位置对固定输入特征进行采样, 为了解决这个问题,研究人员提出了两种解决思路:
- 使用大量的数据进行训练。 比如用ImageNet数据集,再在其基础上做翻转等变化来扩展数据集,通俗地说就是通过穷举的方法使模型能够适应各种形状的物体,这种方法收敛较慢而且要设计复杂的网络结构才能达到理想的结果。
- 设计一些特殊的算法来适应形变 。比如SIFT,目标检测时用滑动窗口法来适应目标在不同位置上的分类也属于这类。
对第一种方法,如果用训练中没有遇到过的新形状物体 (但同属于一类)来做测试,由于新形状没有训练过,会造成测试不准确,而且靠数据集来适应形变的训练过程太耗时 ,网络结构也必须设计的很复杂。
对于第二种方法,如果物体的形状极其复杂 ,要设计出能适应这种复杂结构的算法就更困难了。
为解决该问题,研究人员提出了 Deformable Convolution 方法,它对感受野上的每一个点加一个偏移量 ,偏移的大小是通过学习得到的 ,偏移后感受野不再是个正方形,而是和物体的实际形状相匹配。这么做的好处就是无论物体怎么形变,卷积的区域始终覆盖在物体形状的周围。
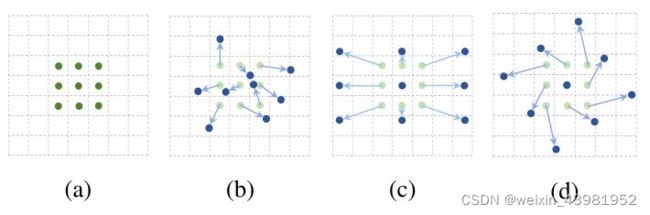
下图为Deformable Convolution的示意图,a 为原始感受野范围,b ~ c 是对感受野上的添加偏移量后的感受野范围,可以看到叠加偏移量的过程可以模拟出目标移动、尺寸缩放、旋转等各种形变
完整的可变性卷积如下图所示,注意上面的卷积用于输出偏移量,该偏移量的长宽和输入特征图的长宽一直,维度是输入的两倍 , 因为同时输出了x和y方向的偏移量。

实验效果 :
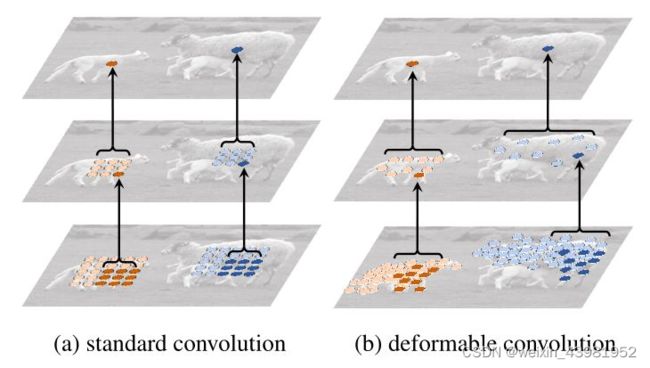
上图所示为标准卷积和Deformable卷积中的receptive field,采样位置(sampling locations)在整个顶部特征图(左)中是固定的。它们根据可变形卷积中对象的比例和形状进行自适应调整(右)。可以看到经过两层的传统卷积和两层的Deformable卷积的对比结果。左侧的传统卷积单个目标共覆盖了5 x 5=25个采样点,感受野始终是固定不变的方形;右侧的可变形卷积因为感受野的每一个点都有偏移量,造成卷积核在图片上滑动时对应的感受野的点不会重复选择,这意味着会采样9 x 9=81个采样点,比传统卷积更多。
显然,传统卷积核在卷积过程中由于会存在重叠,因此输出后的感受野范围小,而可变性卷积中因为有偏移,不会有重叠,从而感受野范围更大
可变形卷积的优点:
- 对物体的形变和尺度建模的能力比较强。
- 感受野比一般卷积大很多 ,因为有偏移的原因,实际上相关实验已经表明了DNN网络很多时候受感受野不足的条件制约;但是一般的空洞卷积空洞是固定的,对不同的数据集不同情况可能最适合的空洞大小是不同的,但是可形变卷积的偏移是可以根据具体数据的情况进行学习的。
Deformable DETR 原理分析
我们知道,DETR利用了Transformer通用以及强大的对相关性的建模能力,来取代anchor,proposal等一些手工设计的元素 。但是DETR依旧存在2个缺陷:
- 训练时间极长 :相比于已有的检测器,DETR需要更久的训练才能达到收敛(500 epochs),比Faster R-CNN慢了10-20倍。
- 计算复杂度高 :发现DETR对小目标的性能很差,现代许多种检测器通常利用多尺度特征,从高分辨率(High Resolution)的特征图中检测小物体。但是高分辨率的特征图会大大提高DETR复杂度。
产生上面两个问题的原因是:
- 在初始化阶段, attention map 对于特征图中的所有pixel的权重是一致 的,导致要学习的注意力权重集中在稀疏的有意义的位置这一过程需要很长时间,意思是 attention map 从Uniform到Sparse and meaningful需要很久。
- attention map 是 Nq x Nk 的,在图像领域我们一般认为 Nq = Nk = Nv = N = HW, 所以里面的weights的计算是像素点数目的平方。 因此,处理高分辨率特征图需要非常高的计算量,存储也很复杂。
所以Deformable DETR的提出就是为了解决上面的两个问题,它主要利用了可变形卷积 (Deformable Convolution)的稀疏空间采样的本领,以及Transformer的对于相关性建模的能力 。针对此提出了一种 Deformable Attention Module ,这个东西只关注一个feature map中的一小部分关键的位置,起着一种pre-filter的作用 。这个 deformable attention module 可以自然地结合上FPN ,我们就可以聚集多尺度特征。
DETR探测小物体方面的性能相对较低,与现代目标检测相比,DETR需要更多的训练epoches才能收敛,这主要是因为处理图像特征的注意模块很难训练。所以本文提出了 Deformable Attention Module 。设计的初衷是:传统的 attention module 的每个 Query 都会和所有的 Key 做attention,而 Deformable Attention Module 只使用固定的一小部分 Key 与 Query 去做attention,所以收敛时间会缩短。
Deformable Attention Module
首先对比下常规attention module与deformable在表达式上的不同:



然后再比较一下二者的self-attention module的不同,如下图,可以发现:Deformable的Attention不是又Query和Key矩阵做内积得到的,而是由输入特征 i 直接通过Lienear Transformation得到的。
Deformable 在具体的代码实现时,Encoder和Decoder的所有attention中除了decoder的self-attention利用Q,K,V三个矩阵,剩下的像encoder的self以及decoder的cross都是只使用了Q,V两个矩阵

我们假设输入特征 i 的维度是 (Nq, C) ,他与几个转移矩阵相乘得到δx,δy以及A ,他们的维度都是 (Nq,M*K) ,其中A表示attention,后面会跟value为内积。
δx,δy代表相对参考点的偏移量,对于Encoder来将,Nq=H*W,即特征图上的每一个点都是向量,δx,δy表示的就是特征图上某点(x,y)对应的value的位置,因为value的维度是(HW, C)维的,所以有HW个位置可以对应,我们需要的就是其中K个位置。
同时,输入特征 i 再与转移矩阵W’ 相乘得到 Value∈(HW,C)矩阵,结合前面计算的δx,δy,可以为Nq维的query中的每一个向量都采样K个分量
为什么是query中的每一个维都取k个分量,这是因为我们从δx的维度就可以知道(Nq,K),而Attention的维度是(Nq, K)
所以采用之后的Value∈(Nq,K, C),M个head的Value就是(Nq,M,K, C),这样就可以使用Attention中的每一行与Value中的一组(M, K, C)去做weighted sum ,并把结果拼接到一起,得到的输出是O∈(Nq,M, C),最后将所有的head拼接到一起。
Multi-scale Deformable Attention Module
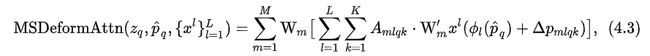
式子中 L 表示feature map的level。


这里不使用FPN,是因为每个query会与所有层的Key进行聚合

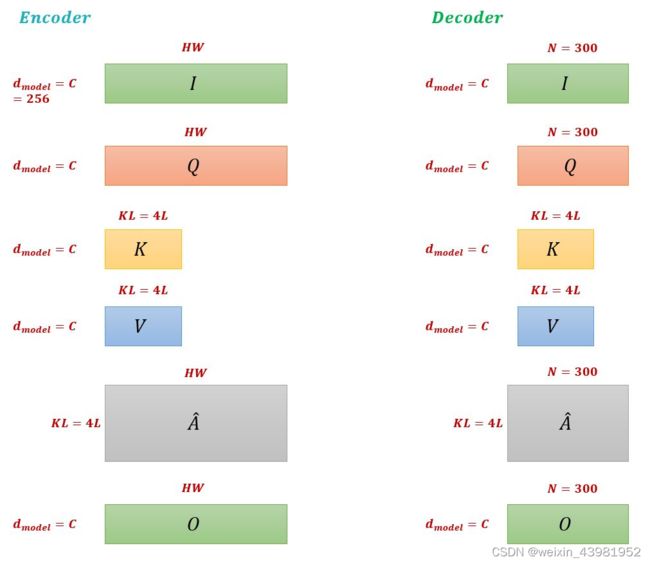
下图是Encoder与Decoder的变量shape的变化图: