基于yolov3的水下目标检测(百度飞浆实现)
写在前面:
本博客主要介绍了如何使用百度飞浆中的yolov3模型进行水下小目标(海胆,海星等)检测,目前mAP值达到47%,随着训练轮数的增加后续可能会有提高。博客中主要进行SSR图像增强、PaddleDetection的部署、yolov3的使用、模型的评估与预测几部分进行。
文章中用到的一些资源已打包上传:
(包括:原始数据集,SSR处理后图片集,当前PaddleDetection压缩包,mAP值为47%的best_model)

链接:
https://pan.baidu.com/s/11T4zwqtvkfbiK3VFATt6MA
提取码:n2ik
链接:
https://aistudio.baidu.com/aistudio/datasetdetail/171095
(SSR处理后数据集,可直接飞浆使用,点个喜爱,谢谢)
正文开始:
SSR图像处理
SSR简介: Retinex理论始于Land和McCann,其基本思想是人感知到某点的颜色和亮度并不仅仅取决于该点进入人眼的绝对光线,还和其周围的颜色和亮度有关。其基本内容是物体的颜色是由物体对长波(红色)、中波(绿色)、短波(蓝色)光线的反射能力来决定的,而不是由反射光强度的绝对值来决定的,物体的色彩不受光照非均匀性的影响,具有一致性,即Retinex是以色感一致性(颜色恒常性)为基础的。
即一幅给定的图像S(x,y)可以分解为两个不同的图像:反射图像R(x,y)和亮度图像L(x,y),Retinex算法要做的就是去除或者减小L(x,y)的影响,得到物体本来的样子。

SSR作为单尺度的Retinex算法,是最基础、最简单的一种Retinex算法。
其实现流程如下:

matlab代码实现:
**********************matlab代码*****************************
clear;clc
Input_path = '***'; %图片输入路径
Output_path='***'; %图片输出路径
namelist = dir(strcat(Input_path,'*.jpg')); %获得文件夹下所有的 .jpg图片
len = length(namelist);
for i = 1:len
name=namelist(i).name; %namelist(i).name; %这里获得的只是该路径下的文件名
I=imread(strcat(Input_path, name)); %图片完整的路径名
R = I(:, :, 1);
[N1, M1] = size(R);
R0 = double(R);
Rlog = log(R0+1);
Rfft2 = fft2(R0); %二维傅里叶变换
sigma = 250;
F = fspecial('gaussian', [N1,M1], sigma); %对图像进行高斯滤波 sigma指定滤波器的标准差
Efft = fft2(double(F));
DR0 = Rfft2.* Efft; %低通滤波图像D(x,y)=S(x,y)*F(x,y) S为原图像 F为高斯滤波函数
DR = ifft2(DR0); %二维离散傅里叶逆变换
DRlog = log(DR +1);
Rr = Rlog - DRlog; %高频增强图像G(x,y)=logS(x,y)-logD(x,y)
EXPRr = exp(Rr); %对G(x,y)取对数,得到增强后的图像R(x,y)
MIN = min(min(EXPRr));
MAX = max(max(EXPRr));
EXPRr = (EXPRr - MIN)/(MAX - MIN); %归一化
EXPRr = adapthisteq(EXPRr); %直方图均衡
%重复其他两个通道的变换,过程同上
G = I(:, :, 2);
G0 = double(G);
Glog = log(G0+1);
Gfft2 = fft2(G0);
DG0 = Gfft2.* Efft;
DG = ifft2(DG0);
DGlog = log(DG +1);
Gg = Glog - DGlog;
EXPGg = exp(Gg);
MIN = min(min(EXPGg));
MAX = max(max(EXPGg));
EXPGg = (EXPGg - MIN)/(MAX - MIN);
EXPGg = adapthisteq(EXPGg);
B = I(:, :, 3);
B0 = double(B);
Blog = log(B0+1);
Bfft2 = fft2(B0);
DB0 = Bfft2.* Efft;
DB = ifft2(DB0);
DBlog = log(DB+1);
Bb = Blog - DBlog;
EXPBb = exp(Bb);
MIN = min(min(EXPBb));
MAX = max(max(EXPBb));
EXPBb = (EXPBb - MIN)/(MAX - MIN);
EXPBb = adapthisteq(EXPBb);
result = cat(3, EXPRr, EXPGg, EXPBb); %联结数组
imwrite(result,[Output_path,num2str(i,'%06d'),'.jpg']); %完整的图片存储的路径名 处理为六位数字
end
下面是SSR处理后的图片对照




可见,对于处理水下图像SSR效果还是很好的,这也符合Retinex理论:在彩色图像增强、图像去雾、彩色图像恢复方面拥有很好的效果。
PaddleDetection的部署
简介: PaddleDetection为基于飞桨PaddlePaddle的端到端目标检测套件,内置30+模型算法及250+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量级产业级SOTA模型、冠军方案和学术前沿算法,并提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。
详细PaddleDetection的学习请见:https://gitee.com/paddlepaddle/PaddleDetection
部署流程:
(以下代码均需在百度飞浆aistudio中运行,也可直接访问项目链接,点个喜欢,谢谢)
step1:创建项目
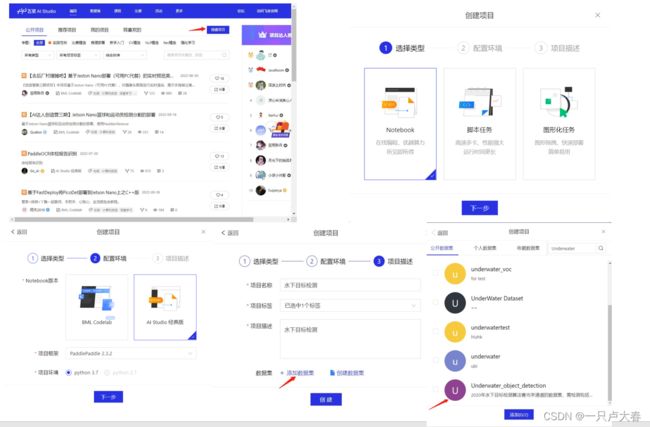
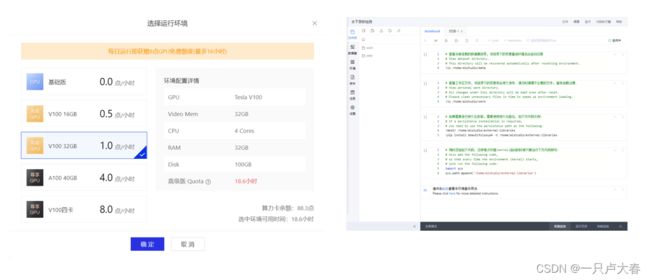
这样一个项目就创建完成了(处理图片拿GPU来跑,飞浆运行项目会赠送的),项目中初始的四部分初始代码不用运行,也可以删掉。
step2:部署PaddleDetection
在gitee上下载PaddleDetection的安装包并解压到work下的文件夹中,代码如下:
%cd ~/work/
! git clone https://gitee.com/paddlepaddle/PaddleDetection.git
飞浆的PaddleDetection安装包一段时间会更新一次,如果需要我当时运行时的安装包可移步文首百度网盘。
tips: 飞浆建立项目后给的两个初始文件夹data与work,我觉得可以浅显的认为data是存储数据的,work为写算法的工作区域。
部署完成后就可看到work下的PaddleDetection文件夹了,其他的一些环境配置见下文中yolov3的使用。
yolov3的使用
yolov3的原理和说明可以参照其他博客,从2018年出来后已经有很多课程讲它讲的很清晰了。我在这里只说明PaddleDetection中yolov3模型的使用,如有疏漏或错误还请补充。
yolov3使用时我们首先需要对数据集处理,数据集处理后可分为VOC和COCO两种格式,格式说明见下:
1. VOC格式数介绍
VOC数据格式的目标检测数据,是指每个图像文件对应一个同名的xml文件,xml文件中标记物体框的坐标和类别等信息。
Pascal VOC比赛对目标检测任务,对目标物体是否遮挡、是否被截断、是否是难检测物体进行了标注。对于用户自定义数据可根据实际情况对这些字段进行标注。
├── annotations
│ ├── road0.xml
│ ├── road100.xml
│ ...
├── images
│ ├── road0.png
│ ├── road100.png
│ ...
├── label_list.txt
├── train.txt
└── valid.txt
xml文件中包含以下字段:
- filename,表示图像名称。
road650.png
- size,表示图像尺寸。包括:图像宽度、图像高度、图像深度
300
400
3
- object字段,表示每个物体。包括
name: 目标物体类别名称
pose: 关于目标物体姿态描述(非必须字段)
truncated: 目标物体目标因为各种原因被截断(非必须字段)
occluded: 目标物体是否被遮挡(非必须字段)
difficult: 目标物体是否是很难识别(非必须字段)
bndbox: 物体位置坐标,用左上角坐标和右下角坐标表示:xmin、ymin、xmax、ymax
label_list.txt 文件中保存着需要识别的类别
train.txt与valid.txt文件中保存着训练与验证的划分标签,格式像这种:
./images/road839.png ./annotations/road839.xml
./images/road363.png ./annotations/road363.xml
./images/road148.png ./annotations/road148.xml
...
2. COCO格式数介绍
COCO数据格式,是指将所有训练图像的标注都存放到一个json文件中。数据以字典嵌套的形式存放。
annotations/
├── train.json
└── valid.json
images/
├── road0.png
├── road100.png
json文件中存放了 info licenses images annotations categories的信息:
-
info: 存放标注文件标注时间、版本等信息。
-
licenses: 存放数据许可信息。
-
images: 存放一个list,存放所有图像的图像名,下载地址,图像宽度,图像高度,图像在数据集中的id等信息。
-
annotations: 存放一个list,存放所有图像的所有物体区域的标注信息,每个目标物体标注以下信息:
{ 'area': 899, 'iscrowd': 0, 'image_id': 839, 'bbox': [114, 126, 31, 29], 'category_id': 0, 'id': 1, 'ignore': 0, 'segmentation': [] }介绍完两种数据格式进行本次数据的处理,我使用的是VOC数据格式,采用的是等间隔抽样(即隔固定间隔进行抽样),0.8:0.2进行划分,代码如下:
#将数据集解压到dataset下,data171095处的路径要改
%cd ~/work/PaddleDetection/dataset/
! pwd
!unzip -oq ~/data/data171095/train.zip
#生成label_list.txt train.txt valid.txt文件
import random
import os
#生成train.txt和val.txt
# random.seed(2020)
#路径要改
xml_dir = '/home/aistudio/work/PaddleDetection/dataset/train/annotations'#标签文件地址
img_dir = '/home/aistudio/work/PaddleDetection/dataset/train/images'#图像文件地址
path_list = list()
for img in sorted(os.listdir(img_dir)):
img_path = os.path.join(img_dir,img)
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))
# random.shuffle(path_list)
ratio = 10
#路径要改
train_f = open('/home/aistudio/work/PaddleDetection/dataset/train/train.txt','w') #生成训练文件
val_f = open('/home/aistudio/work/PaddleDetection/dataset/train/valid.txt' ,'w')#生成验证文件
for i ,content in enumerate(path_list):
img, xml = content
text = img + ' ' + xml + '\n'
#取名称末尾是1或者2的,相当于0.8:0.2划分数据集
if i%ratio==1 or i%ratio==2:
val_f.write(text)
else:
train_f.write(text)
train_f.close()
val_f.close()
#生成标签文档
label = ['holothurian','echinus','scallop','starfish','waterweeds'] #设置你想检测的类别
with open('./train/label_list.txt', 'w') as f:
for text in label:
f.write(text+'\n')
接下来就是继续PaddleDetection中yolov3的配置了,这块笔者现阶段了解的不是太多也,说的有些粗糙还请理解,后续有更深入的理解后会回来补充。
一些必要环境的安装:
%cd /home/aistudio/work/PaddleDetection/
!pip install -r requirements.txt
!pip install pycocotools
!pip install paddledet
因为我们使用GPU来对图片进行训练,接下来设置GPU。
!with fluid.dygraph.guard(place=fluid.CUDAPlace(0)) #设置使用GPU资源训神经网络,默认使用服务器的第一个GPU卡。"0"是GPU卡的编号,比如一台服务器有的四个GPU卡,编号分别为0、1、2、3。
import paddle
print(paddle.device.get_device())
我们使用yolov3_mobilenet_v3_large_ssld_270e_voc.yml这个模型,对模型中的参数进行更改:

在修改文件之前,先给大家解释一下各依赖文件的作用:
'_base_/optimizer_270e.yml',主要说明了学习率和优化器的配置,以及设置epochs。在其他的训练的配置中,学习率和优化器是放在了一个新的配置文件中。
'../datasets/voc.yml'主要说明了训练数据和验证数据的路径,包括数据格式(coco、voc等)
'_base_/yolov3_reader.yml', 主要说明了读取后的预处理操作,比如resize、数据增强等等
'_base_/yolov3_mobilenet_v3_large.yml',主要说明模型、和主干网络的情况说明。
'../runtime.yml',主要说明了公共的运行状态,比如说是否使用GPU、迭代轮数等等
介绍一下需要修改的几个地方(画红线的地方):

上图中第一个箭头为训练轮数,可以增加训练次数达到更好的效果,第二个为学习率,两个地方可根据自己需要更改。

这里提醒,名称要按 VOC格式数来写。
yolov3对训练数据使用k-means聚类的算法来获得anchor boxes大小
#K-means聚类
# -c 参数表示指定使用哪个配置文件
# -n 9 生成 9 组尺寸
# -s 608 指定图像训练尺寸
# -m v2 使用默认的 v2 版本方法
# -i 1000 迭代次数
!python tools/anchor_cluster.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -n 9 -s 608 -m v2 -i 1000
接下来就可以进行模型的训练了
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
# --eval 参数表示边训练边评估,最后会自动保存一个名为best_model.pdparams的模型
# --use_vdl=True 配置开启深度学习可视化,可以看一些 loss 曲线,可视化训练过程中关键指标的变化
# 最后模型文件输出在output中
!python tools/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml --eval --use_vdl=True --vdl_log_dir="./output"
训练过程中会有epoch loss值等的输出,可以根据此查看训练进度以及剩余时间,像这样:

模型的评估与预测
对模型进行评估:
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
!python -u tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams
然后来一张图片看看效果:
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
# --infer_img 指定要测试的图像
!python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams --infer_img=/home/aistudio/work/PaddleDetection/dataset/train/images/000111.jpg
图片会放在work/PaddleDetection/output路径中,效果如图:
感谢前辈的分享,本文参考:
https://blog.smslit.cn/2021/04/15/paddle-detection-train-log/
https://aistudio.baidu.com/aistudio/projectdetail/3460363?channelType=0&channel=0