CNN + LSTM 航空乘客预测
前言
- LSTM 航空乘客预测单步预测的两种情况。 简单运用LSTM 模型进行预测分析。
- 加入注意力机制的LSTM 对航空乘客预测采用了目前市面上比较流行的注意力机制,将两者进行结合预测。
- 多层 LSTM 对航空乘客预测 简单运用多层的LSTM 模型进行预测分析。
- 双向LSTM 对航空乘客预测双向LSTM网络对其进行预测。
- MLP多层感知器 对航空乘客预测 使用MLP 对航空乘客预测
本文采用的CNN + LSTM网络对其进行预测。
我喜欢直接代码+ 结果展示
先代码可以跑通,才值得深入研究每个部分之间的关系;进而改造成自己可用的数据。
1 数据集
链接: https://pan.baidu.com/s/1jv7A2JvIhA6oqvtYnYh9vQ
提取码: m5j5
2 模型
卷积神经网络,简称CNN,是为处理二维图像数据而开发的一种神经网络。
CNN可以非常有效地从一维序列数据(例如单变量时间序列数据)中自动提取和学习特征。
CNN模型可以在具有LSTM后端的混合模型中使用,其中CNN用于解释输入的子序列,这些子序列一起作为序列提供给LSTM模型进行解释。这种混合模型称为CNN-LSTM。
2.1 单步预测 1—》1
- 代码
#单变量,1---》1
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers import Flatten
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
#matplotlib inline
# load the dataset
dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python')
# print(dataframe)
print("数据集的长度:",len(dataframe))
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
plt.plot(dataset)
plt.show()
# X是给定时间(t)的乘客人数,Y是下一次(t + 1)的乘客人数。
# 将值数组转换为数据集矩阵,look_back是步长。
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
# X按照顺序取值
dataX.append(a)
# Y向后移动一位取值
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
# fix random seed for reproducibility
numpy.random.seed(7)
# 数据缩放
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 将数据拆分成训练和测试,2/3作为训练数据
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print("原始训练集的长度:",train_size)
print("原始测试集的长度:",test_size)
# 构建监督学习型数据
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
print("转为监督学习,训练集数据长度:", len(trainX))
# print(trainX,trainY)
print("转为监督学习,测试集数据长度:",len(testX))
# print(testX, testY )
# 数据重构为4D [samples, subsequences, timesteps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1,1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0],1, 1, testX.shape[1]))
print('构造得到模型的输入数据(训练数据已有标签trainY): ',trainX.shape,testX.shape)
# create and fit the LSTM network
model = Sequential()
model.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu', input_shape=(None,1, testX.shape[1]))))
model.add(TimeDistributed(MaxPooling1D(pool_size=1)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(4,activation='relu'))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
model.fit(trainX, trainY, epochs=50)
# 打印模型
model.summary()
# 开始预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 逆缩放预测值
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# shift train predictions for plotting
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
- 结果展示
数据集的长度: 144
原始训练集的长度: 96
原始测试集的长度: 48
转为监督学习,训练集数据长度: 94
转为监督学习,测试集数据长度: 46
构造得到模型的输入数据(训练数据已有标签trainY): (94, 1, 1, 1) (46, 1, 1, 1)
Epoch 1/50
3/3 [==============================] - 1s 2ms/step - loss: 0.0581
Epoch 2/50
3/3 [==============================] - 0s 2ms/step - loss: 0.0540
Model: "sequential_26"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
time_distributed_45 (TimeDis (None, 1, 1, 64) 128
_________________________________________________________________
time_distributed_46 (TimeDis (None, 1, 1, 64) 0
_________________________________________________________________
time_distributed_47 (TimeDis (None, 1, 64) 0
_________________________________________________________________
lstm_20 (LSTM) (None, 4) 1104
_________________________________________________________________
dense_15 (Dense) (None, 1) 5
=================================================================
Total params: 1,237
Trainable params: 1,237
Non-trainable params: 0
_________________________________________________________________
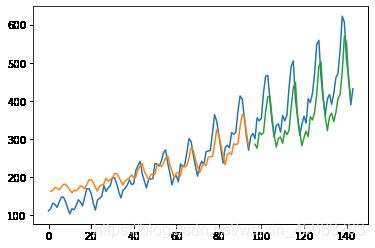
Train Score: 32.66 RMSE
Test Score: 65.98 RMSE
2.2 单步预测 3—》1
- 代码
# 单变量,3---》1
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers import Flatten
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
#matplotlib inline
# load the dataset
dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python')
# print(dataframe)
print("数据集的长度:",len(dataframe))
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
plt.plot(dataset)
plt.show()
# X是给定时间(t)的乘客人数,Y是下一次(t + 1)的乘客人数。
# 将值数组转换为数据集矩阵,look_back是步长。
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
# X按照顺序取值
dataX.append(a)
# Y向后移动一位取值
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
# fix random seed for reproducibility
numpy.random.seed(7)
# 数据缩放
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 将数据拆分成训练和测试,2/3作为训练数据
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print("原始训练集的长度:",train_size)
print("原始测试集的长度:",test_size)
# 构建监督学习型数据
look_back = 3
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
print("转为监督学习,训练集数据长度:", len(trainX))
# print(trainX,trainY)
print("转为监督学习,测试集数据长度:",len(testX))
# print(testX, testY )
# 数据重构为4D [samples, subsequences, timesteps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1,trainX.shape[1],1))
testX = numpy.reshape(testX, (testX.shape[0],1,testX.shape[1], 1))
print('构造得到模型的输入数据(训练数据已有标签trainY): ',trainX.shape,testX.shape)
# create and fit the LSTM network
model = Sequential()
model.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu', input_shape=(None,testX.shape[1],1))))
model.add(TimeDistributed(MaxPooling1D(pool_size=1)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(4,activation='relu'))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
model.fit(trainX, trainY, epochs=50)
# 打印模型
model.summary()
# 开始预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 逆缩放预测值
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# shift train predictions for plotting
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
- 结果展示
原始训练集的长度: 96
原始测试集的长度: 48
转为监督学习,训练集数据长度: 92
转为监督学习,测试集数据长度: 44
构造得到模型的输入数据(训练数据已有标签trainY): (92, 1, 3, 1) (44, 1, 3, 1)
Epoch 1/50
3/3 [==============================] - 1s 3ms/step - loss: 0.0589
Epoch 2/50
3/3 [==============================] - 0s 3ms/step - loss: 0.0531
Model: "sequential_25"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
time_distributed_42 (TimeDis (None, 1, 3, 64) 128
_________________________________________________________________
time_distributed_43 (TimeDis (None, 1, 3, 64) 0
_________________________________________________________________
time_distributed_44 (TimeDis (None, 1, 192) 0
_________________________________________________________________
lstm_19 (LSTM) (None, 4) 3152
_________________________________________________________________
dense_14 (Dense) (None, 1) 5
=================================================================
Total params: 3,285
Trainable params: 3,285
Non-trainable params: 0
_________________________________________________________________
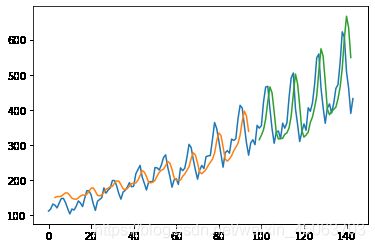
Train Score: 33.02 RMSE
Test Score: 79.32 RMSE
3 总结
- 将CNN 和LSTM 组合的话,可以利用两者的优势,提高预测的能力
- 写代码的时候,注意格式的转化和连接过程的格式
- CNN-LSTM是CNN(卷积层)与LSTM的集成。首先,模型的CNN部分处理数据,一维结果输入LSTM模型。
- 每一个时间步,都使用卷积网络结构进行输入的特征提取