【目标检测-YOLO】YOLO_V2
yolov2 论文分为两部分:yolov2(Better, Faster)和 yolo9000(Stronger)。本文不讨论 yolo 9000内容。
1.yolov2(Better)
YOLOv2 相对v1改进在哪里?(消融研究)
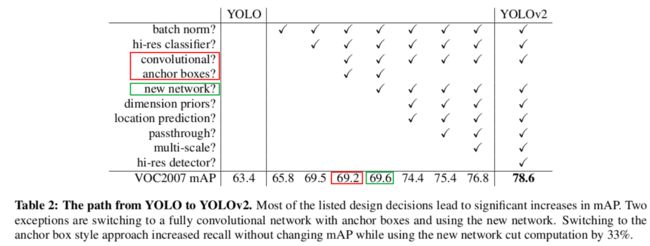
图中,红框和绿框并没有增加 mAP。
但是红框增加了 recall,69.5 mAP + 81% recall 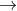 69.2 mAP + 88% recall。recall增加,那么什么减少了呢?Precision 减少了,但是可以通过表中的后面的技巧优化结果。原论文说:recall 的提升代表yolov2有很大的提升空间。
69.2 mAP + 88% recall。recall增加,那么什么减少了呢?Precision 减少了,但是可以通过表中的后面的技巧优化结果。原论文说:recall 的提升代表yolov2有很大的提升空间。
绿框并没有提升太多 mAP(0.4),但是计算量降低了 33%。
以下都是在 yolov1 为 baseline 上进行的消融研究。
1. BN
在 yolov1 中的所有卷积层的后面加 BN, 并且移除了 dropout。没有过拟合。(BN是否可以防止过拟合,目前没有看到定论。)
参考:批量归一化和层归一化_hymn1993的博客-CSDN博客_层归一化批量归一化是对每个特征/通道里的元素进行归一化。(不适合序列长度会变的NLP应用)层归一化是对每个样本里面的元素进行归一化。ln = nn.LayerNorm(2)bn = nn.BatchNorm1d(2)X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)# 在训练模式下计算X的均值和方差print('layer norm:', ln(X), '\nbatch norm:', bn(X))输出:layer norm: thttps://blog.csdn.net/hymn1993/article/details/122719043 通常,将批量规范化层置于全连接层中的仿射变换和激活函数之间。

优点:
- 使深度网络容易训练(容易收敛)
- 改善梯度流(避免梯度消失和爆炸)
- 可以使用较大学习率,更快收敛
- 对网络初始化更加 稳健(robust )
- 正则化作用
- 训练和测试时候不同
BN 和 Dropout 一起使用模型性能为什么降低?
大白话《Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift》 - 知乎原文戳首先大家都知道自BN提出之后,Dropout突然失宠,究其原因就是BN原作者提到在他们的实践中对有BN的网络加了Dropout通常性能不升反降。他们猜测BN由于引入了不同样本之间的统计量,可能产生了一定的正则化效果… https://zhuanlan.zhihu.com/p/33101420
https://zhuanlan.zhihu.com/p/33101420
Batch Normalization和Dropout如何搭配使用?_hexuanji的博客-CSDN博客_batchnormalization和dropoutBatch Normalization和Dropout如何搭配使用?背景分析解决方案参考资料背景众所周知,在Batch Normalization(BN)出来之前,dropout是训练神经网络时的标配,如果你的数据不够多,那么模型很容易过拟合,导致模型的性能下降。Dropout在很多任务上证明了自己的有效性,比如图片分类,语音识别,目标检索等等。但是在BN提出之后,dropout突然失宠了,原...https://blog.csdn.net/hexuanji/article/details/103635335
2. 高分辨率分类器
v1 的 backbone 是在 224*224 输入下在ImageNet上训练的, 然后增加分辨率到 448 进行检测。网络需要同时学习目标检测和调整到新的输入分辨率。
v2 的 backbone 怎么训练的?
在 yolov1 的基础上训练的 224*224的预训练模型上,然后 448 * 448 分辨率下训练 10 epochs on ImageNet. 然后 训练检测。效果:提升 3.7% mAP。
3. Convolutional With Anchor Boxes
yolov1 在全连接层上 直接预测 边框坐标,而 Faster R-CNN 是 使用手动选择的 先验框上直接预测。Faster R-CNN 预测 offsets and confidences 来自 anchor boxes. 预测 offsets 相对 预测坐标更加简化了问题,容易学习。
在以上基础上,移除了 YOLOv1 的 FC 和使用 anchor boxes 来预测 bounding boxes.
- 移除一个pooling层,输出更高分辨率的feature map。
- 将网络的输入由448改为416,这样使得得到的feature map只有一个中心点,因为经过32的下采样率,最后得到13*13的feature map,是奇数。因为大的物体通常在图片的中间,所以最好使用一个中心点来负责预测这个物体。因为已经移除了 pooling ,原始 V1 是下采样 64 倍,所以这里是 32 倍。
- 使用anchor boxs,将 class 预测机制与空间位置解耦。预测每个 anchor box 的 class 和 objectness(v1中的置信度)。(v1 中,class 的预测和空间坐标是耦合在一起的,因为类别的预测是与 grid cell 绑定的,每个 grid cell 会预测 20-dims 的条件概率向量,而gird cell 是图像空间中的某个位置。)
- objectness 的预测是 IOU(gt,anchor)作为 标签。(v1中是 IOU(gt, 预测框) 作为 objectness 的标签)。class 预测同 v1, 是有物体条件下的 条件概率。
效果:69.5 mAP + 81% recall 69.2 mAP + 88% recall。
4. anchor 大小聚类
不同于手动选择 anchor 大小, 选择更好的 anchor 尺度可以让网络更容易学习。怎么做?
k-means 对训练集中的真值边框进行聚类来得到更好的先验框。
这里的聚类是针对 真实框的 w 和 h。
标准的距离衡量是 欧式距离,![]() 。但是对于相同的IOU而言,欧式距离对大边框产生比小边框更多的误差。
。但是对于相同的IOU而言,欧式距离对大边框产生比小边框更多的误差。

红色框为聚类中心的边框b,绿色为 小边框 b1,橙色为 大边框 b2,显然,IOU(b, b1) = IOU(b, b2) = 1/9。如果计算欧式距离:b2: (2* (9-3)^2)^0.5 = 8.5,b1: (2* (1-3)^2)^0.5 = 2.8
聚类的目的是: 先验框(anchor) 与 真实框 的 IOU值大,从而使模型更容易学习。我们希望,边框的大小不影响距离的衡量。
聚类的最终结果是:训练集中的真实框 都属于某个聚类中心(最终是anchor),这些真实框离它们的中心距离最小。我们期望的是:距离最小应该代表 IOU(真实框,聚类中心) 最大。所以,使用 1 - IOU(真实框,聚类中心)表示距离函数,这样就保证距离越小,IOU值越大。
![]()

把所有的真实框与它们最近的聚类框求IOU,然后求平均值。得到上图左图。 选择 k =5 作为 模型复杂度和高的recall 之间的权衡。右边图为了显示,把不同尺度的框画在了不同位置。蓝色的为 coco 数据集结果,黑色为 voc数据集的结果。结果表明,与手动选择不同,聚类的结果高瘦的更多。

上图中SSE为欧式距离聚类,文献[15]是 faster rcnn 采用的手动选择。表明使用k-means来生成我们的边界框可以使模型有更好的表示,并使任务更容易学习。
5. Direct location prediction
在以上的基础上使用 anchor boxes,遇到问题:在训练的早期,模型不稳定。大部分原因来自与 边框的定位的预测。在 faster rcnn中的 RPN网络中:
![]()
![]()
(x, y)是预测框的中心坐标,  和
和![]() 是anchor的中心点坐标,
是anchor的中心点坐标, 和
和 是anchor的宽和高,
是anchor的宽和高, 和
和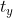 是要学习的参数。 注意,YOLOv2论文中写的是 "-",根据Faster R-CNN,应该是"+"。
是要学习的参数。 注意,YOLOv2论文中写的是 "-",根据Faster R-CNN,应该是"+"。
例如,预测= 1将使预测框向右移动一个 anchor box 的宽度; 预测= -1将使预测框向左移动一个 anchor box 的宽度。
由于和的取值没有任何约束,因此 预测框的中心 可能出现在图像中的任何位置,不管anchor box 的中心坐标在哪里。在随机初始化的情况下,模型需要很长时间才能稳定到预测合理的offsets。
yolov1中,在训练时,预测框的标签值的(x,y)坐标 在 0~1 之间,但是预测值 却没有被约束,因此,预测框的中心坐标可以出现在全图的任何位置。yolov2中,使用 sigmoid 函数,将 预测值 约束到 0~1 之间。
该网络在 输出特征图中每个cell 预测 5个 预测框。每个预测框有五个值 :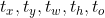 。如果这个 cell 从图像的左上角偏移
。如果这个 cell 从图像的左上角偏移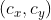 ,anchor box的宽度和高度是
,anchor box的宽度和高度是![]() ,那么 预测框 的 (
,那么 预测框 的 (![]() ) 为:
) 为:

由于约束了 定位参数,那么这个参数更容易学习,使得网络更稳定。anchor 聚类 + 输出约束 相对以上部分 提升了 近 5% mAP。这里 ![]() 被约束到 和 anchor box 同样的 cell中。
被约束到 和 anchor box 同样的 cell中。
因为预测框的w和h 显然是非负的。使用指数函数将![]() 约束为 正数。
约束为 正数。

上图中,蓝色框为 当前 cell 的 预测框,虚线框为 anchor box。
6. 细粒度特征
以上部分,模型输出的结果为 13*13*5*(4+1+20),仅使用 13*13 特征层,这对大目标足够,为了定位小目标可能需要 细粒度特征。 Faster R-CNN 和 SSD 都在网络中的多个尺度的特征图上运行它们的proposal networks,以获得多种分辨率。
yolov2 简单采用了一个 叫做 passthrough 层,使用 细粒度特征。

检测头运行在 输出的 13*13*3072 上面,提升了1% mAP。但是在代码实现中: 作者先采用64个 1*1 卷积核进行对 高分辨率特征图(26*26*512)卷积,然后再进行passthrough处理,然后得到的(13*13*256) 的特征图。

passthrough层 如上所示,Swin Transformer 中的 Patch Merging正是这个东西来进行downsample。
7. 多尺度训练
原始 YOLO 使用 448 × 448 的输入分辨率。通过添加 anchor boxes,将分辨率更改为 416×416。 然而,由于我们的模型只使用卷积层和池化层,它可以动态调整大小。 我们希望 YOLOv2 能够在不同大小的图像上运行,因此我们将其训练到模型中。
每 10 batches 网络选择一个随机输入大小, 因为模型下采样 32 倍,因此输入的范围为 32的倍数:{320, 352, ..., 608}。

这种训练方式使网络学会在各种输入分辨率上进行良好的预测。 这意味着同一个网络可以在不同分辨率的进行检测。 网络在较小的尺寸下运行得更快,因此 YOLOv2 提供了速度和准确性之间的权衡。

超过 30 FPS 代表实时目标检测。
8. 更多实验


 前两个表是在 VOC 数据集,后者在 COCO 数据集。“++” 代表在 voc 07的训练集和测试集 + 12 的训练集,在12的测试集上测试。
前两个表是在 VOC 数据集,后者在 COCO 数据集。“++” 代表在 voc 07的训练集和测试集 + 12 的训练集,在12的测试集上测试。
2.yolov2(Faster)
Backbone:
常用backbone vgg-16: 224 × 224 单张图像,30.69 billion floating point operations,ImageNet top-5 accuracy:90.0% 。
yolov1 backbone: 224 × 224 单张图像,8.52 billion floating point operations,ImageNet top-5 accuracy:88.0% 。
yolov2 backbone Darknet-19:224 × 224 单张图像,5.58 billion floating point operations,ImageNet top-5 accuracy:91.2% ,top-1 accuracy:72.9%。

1. 图像分类预训练:(在ImageNet-1k)
- Darknet-19 在 ImageNet-1k, 224 输入,160 epochs, SGD(lr = 0.1, 4次多项式学习率衰减(polynomial rate decay with a power of 4), weight decay = 0.0005, momentum = 0.9。standard data augmentation tricks: random crops, rotations, and HSV(hue, saturation, and exposure) shifts.
- fine tune 448 输入 , 10 epochs, lr = 10^−3 . 获得结果:top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%.
2. 检测训练:

修改网络结构如上图, 然后在检测数据集上训练。
160 epochs, lr = 10^−3(除以10 at 60 and 90 epochs),weight decay = 0.0005, momentum = 0.9,data augmentation:同 YOLOv1 and SSD, random crops, color shifting, etc。 COCO and VOC训练策略一致。
3. 推理:
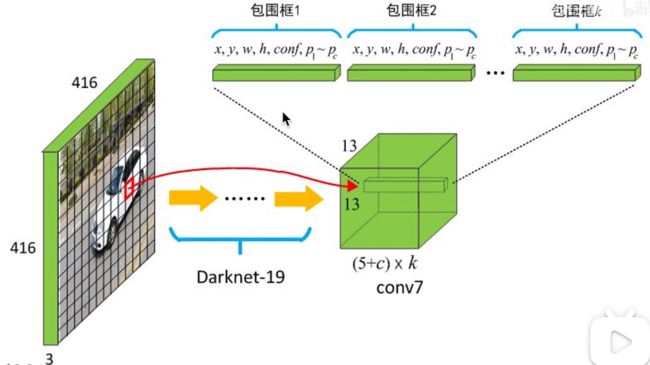
4. 待续
- yolov2 总结
- yolov2 损失函数
5. 参考:
yolov2 论文
【精读AI论文】YOLO V2目标检测算法_哔哩哔哩_bilibili
2.1 YOLO入门教程:YOLOv2(1)-解读YOLOv2 - 知乎
使用k-means聚类anchors_霹雳吧啦Wz-CSDN博客_anchors聚类