YOLO v2算法详解
论文地址:YOLO9000: Better, Faster, Stronger
优势:
YOLO9000能够预测超过9000个不同类别。
在voc07数据集上,YOLO v2表现胜过Faster R-CNN,67FPS,76.8mAP;40FPS,78.6mAP。
Better
YOLO算法产生大量定位误差,并且具有低召回率。因此我们在维持分类准确性的前提下,提高召回率和定位准确度。
1、Batch Normalization
BN为对每一层输入进行归一化处理,一般放在卷积层后,激活层前。
- 加入BN层,在没有正则项时,也可加速收敛。
- mAP提升2%。
- 加入BN层,即使去掉dropout层,也不会出现过拟合现象。
2、High Resolution Classifier
YOLO在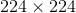 分辨率上训练网络,在
分辨率上训练网络,在![]() 分辨率上检测,导致网络模型在转换到目标检测时,需要调整分辨率。
分辨率上检测,导致网络模型在转换到目标检测时,需要调整分辨率。
YOLO v2在分辨率ImageNet数据集训练160个epoch,之后改变分辨率为![]() ,训练10个epoch,数据集仍为ImageNet;最后在检测数据集上fine-tune,最终mAP提升4%。
,训练10个epoch,数据集仍为ImageNet;最后在检测数据集上fine-tune,最终mAP提升4%。
3、Convolutional With Anchor Boxes
YOLO通过全联接层直接预测bounding box坐标,而Faster R-CNN中RPN通过卷积层预测anchor的偏移和置信度,因为预测层是卷积层,预测偏移而不是坐标使得网络更易于学习。
YOLO v2移除YOLO网络中的全联接层,使用anchor box预测bounding box。首先,去除一个池化层,使卷积层输出有较高分辨率;其次缩减网络,更改输入图片![]() 为
为![]() ,之所以做如此更改,是因为这样特征图有奇数个位置,存在中心单元;输入图片
,之所以做如此更改,是因为这样特征图有奇数个位置,存在中心单元;输入图片![]() ,通过卷积层降采样32倍,得到
,通过卷积层降采样32倍,得到![]() 的特征图。因此中心单元为1个而不是4个,对于大目标,通常占据图片中心,所以希望用一个中心单元预测目标,而不是4个。
的特征图。因此中心单元为1个而不是4个,对于大目标,通常占据图片中心,所以希望用一个中心单元预测目标,而不是4个。
YOLO每张图片预测98个box,引入anchor box后,YOLO v2每张图片预测超过1000个box。引入anchor box之前,模型mAP为69.5%,召回率81%;引入anchor box之后,模型mAP略微下降,为69.2%,但召回率提高明显,为88%
4、Dimension Clusters
作者引入anchor遇到第一个问题:box大小通过人工选择。
在Fast R-CNN中,anchor box大小根据经验设定,然后通过训练不断调整。但是若一开始选定恰当尺寸,可以帮助网络进行更好的预测。作者k-means的方式对训练集的bounding boxes做聚类,找到合适大小anchor box。
由于使用标准k-means的方法,即使用欧式距离进行聚类,则大的box产生的误差必然比小box要大很多。因此采用评估公式为:
![]()
centroid表示簇的中心。
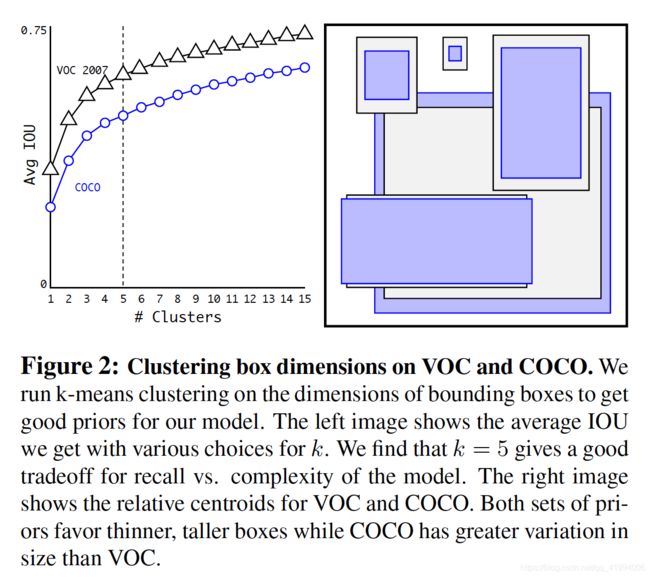
左图表示不同数据集上簇的个数与平均IOU关系,k=5时是比较好的权衡点,平衡召回率与模型复杂度。右图展示在不同数据集得到的簇,即5个box大小。聚类得到的anchor box与手动选择的anchor box有显著不同,聚类得到的box大多为高瘦型,很少有矮胖型。
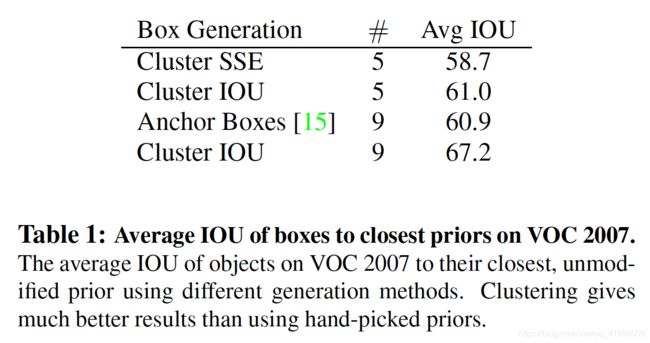
表1中作者采用的5种anchor(Cluster IOU)的Avg IOU是61%。通过聚类产生bounding box的方法,使得模型训练更容易。
5、 Direct location prediction
作者引入anchor遇到第二个问题:模型稳定性。作者认为模型不稳定性主要来自box的(x,y)坐标。
RPN中预测偏移量![]() 以及bounding box中心坐标(x,y)可根据下面公式计算:
以及bounding box中心坐标(x,y)可根据下面公式计算:
![]()
![]()
个人认为论文中公式写错。
这个公式不受限制,所以任何anchor box都可能扩张到图片边界大小,当模型进行随机初始化时,需花费大量时间使模型稳定预测出合适偏移量。
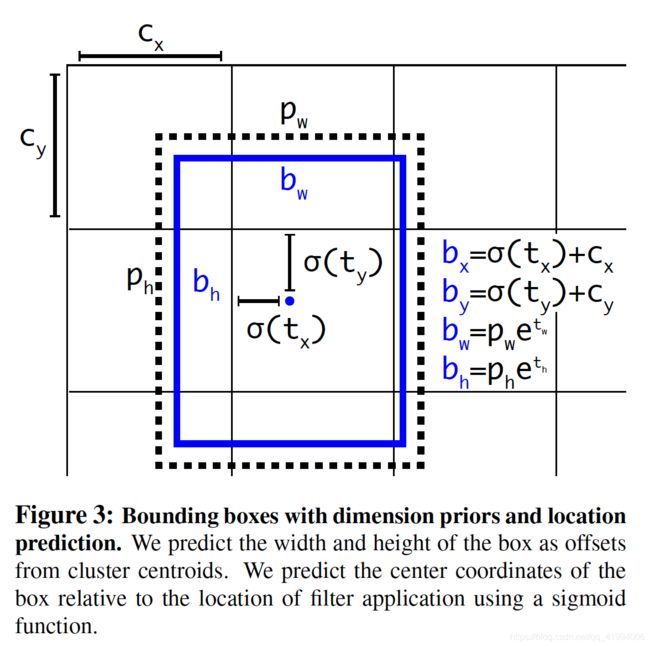
YOLO v2没有预测偏移量,沿用YOLO方法,预测与网格位置相关的坐标。YOLO v2在![]() 的特征图上的每个单元(cell)预测5个bounding box,每个bounding box需要预测5个坐标:
的特征图上的每个单元(cell)预测5个bounding box,每个bounding box需要预测5个坐标:![]() (类似于置信度)。
(类似于置信度)。![]() 经过sigmoid函数处理后范围在0到1之间,这样的归一化处理也使得模型训练更加稳定;
经过sigmoid函数处理后范围在0到1之间,这样的归一化处理也使得模型训练更加稳定;![]() 表示每个cell和图像左上角的横纵距离;
表示每个cell和图像左上角的横纵距离;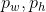 表示bounding box的宽和高,即一开始设置的anchor大小,因此bounding box的坐标
表示bounding box的宽和高,即一开始设置的anchor大小,因此bounding box的坐标![]() 可根据
可根据![]() 这个cell附近的anchor来预测tx和ty得到的结果。公式如下:
这个cell附近的anchor来预测tx和ty得到的结果。公式如下:
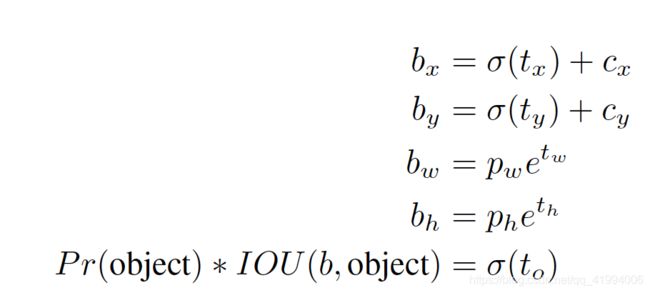
6、 Fine-Grained(细粒度) Features
在![]() 的特征图上预测大目标足够,但对于小目标效果不理想,Faster R-CNN及SSD在不同大小特征图上进行预测。YOLO v2只是单纯增加 passthrough层,将前面
的特征图上预测大目标足够,但对于小目标效果不理想,Faster R-CNN及SSD在不同大小特征图上进行预测。YOLO v2只是单纯增加 passthrough层,将前面![]() 特征图与本层连接。passthrough层将
特征图与本层连接。passthrough层将![]() 特征图转变为
特征图转变为![]() 的特征图与本层
的特征图与本层![]() 特征图结合,得到
特征图结合,得到![]() 的特征图,由此增加细粒度,在此特征图上做预测。
的特征图,由此增加细粒度,在此特征图上做预测。
7、 Multi-Scale Training
为了让YOLO v2在不同大小图片上检测稳定,引入多尺度训练。在检测数据上(非ImageNet数据集)训练网络时,每10个batch,网络随机选择一个图片尺寸,由于模型下采样倍数为32,因此选择32的倍数,{320,352,...,608},即图片最小为![]() ,最大为
,最大为![]() 。这种结构使得网络学着在各种分别率输入都有较好预测结果。此网络在小图片上检测更快,YOLO v2在速度与准确率上找到一个权衡点。
。这种结构使得网络学着在各种分别率输入都有较好预测结果。此网络在小图片上检测更快,YOLO v2在速度与准确率上找到一个权衡点。
在voc数据集上,YOLO v2与其他模型检测效果比较如表3所示。
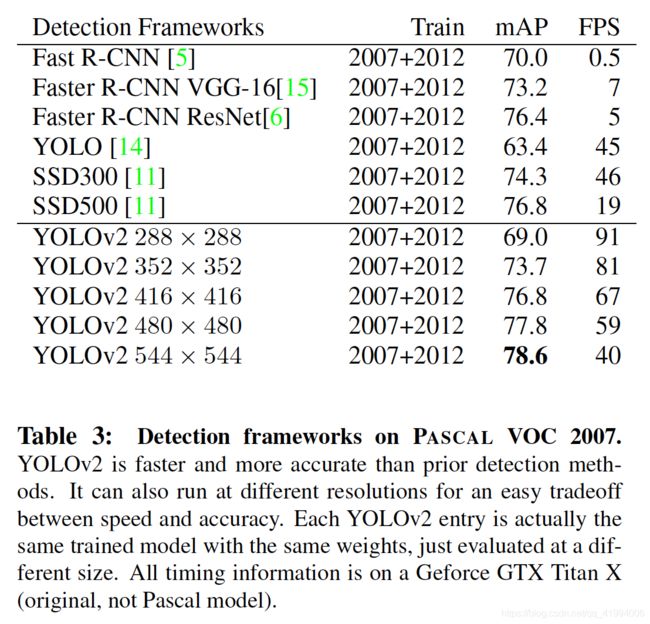
在较高分辨率的输入图片下,YOLO v2检测mAP为78.6%,40FPS,达到实时检测效果。
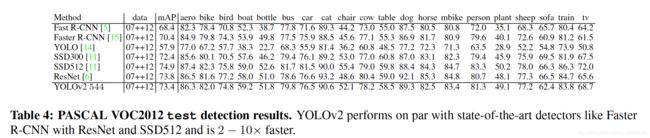
表四与表五展示不同检测模型在VOC及COCO数据集上检测效果。
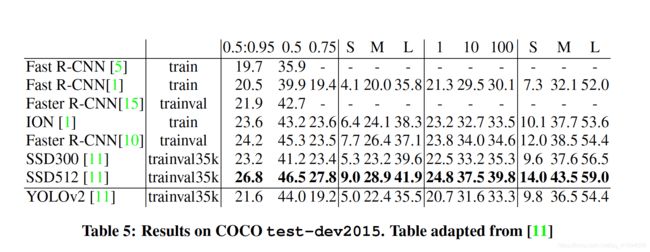
表二总结YOLO到YOLO v2的过渡过程。使用anchor及新网络对mAP提升不大,但是使用anchor box提高了召回率,使用新网络缩减33%计算量。
Faster
VGG-16有 30.69 billion operations, Googlenet比 VGG-16计算速度快,有8.52 billion operations,但是在ImageNet数据集上,基于Googlenet的YOLO top-5准确率为88%,而基于VGG-16的模型top-5准确率为90%.
1、Darknet-19
作者提出一种新的网络作为YOLO v2的基础——Darknet-19.
- 该网络与VGG-16类似,大量使用
 的卷积层,每次进行池化后,都将chanel层翻倍。
的卷积层,每次进行池化后,都将chanel层翻倍。 - 使用global average pooling代替全联接层。
- 在两个的卷积层之间使用
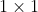 的卷积层压缩特征。
的卷积层压缩特征。 - 使用BN层,使得训练过程稳定,加速收敛,正则化模型。
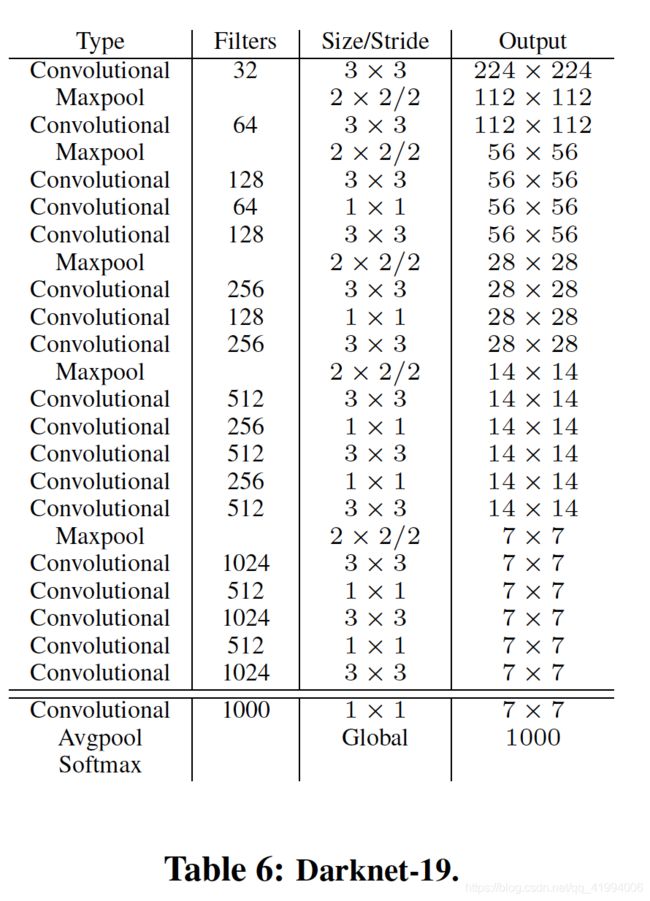
Darknet-19网络有19个卷积层,5个maxpooling层,网络结构如表6所示,最后用其有5.58 billion operations,在ImageNet数据集上取得top-1的72.9%的准确率以及top-5的91.2%的准确率。
2、Training for classification
首先在1000类的ImageNet数据集上进行训练Darknet-19网络,训练160个epoch,输入图像的大小是224*224,初始学习率为0.1。训练过程使用标准数据增强方法:随机裁剪,旋转,色调、饱和度及曝光度变化。
接下来在448*448图像上fine tune网络,训练10个epoch,学习率为0.001,其他参数不变。此时在ImageNet数据集上取得top-1的76.5%的准确率以及top-5的93.3%的准确率。
3、Training for detection
接下来将上面训练的网络移植到检测网络,基于检测数据进行fine-tune,首先更改网络结构,去除最后一个卷积层,增加3个![]() 的卷积层,每个卷积层有1024个filters,每个
的卷积层,每个卷积层有1024个filters,每个![]() 的卷积层后面跟随
的卷积层后面跟随![]() 的卷积层,filter数量为待检测的的输出数量。比如:voc数据集上,我们需要预测5个box,每个box预测5个坐标及20个类别,所以需要
的卷积层,filter数量为待检测的的输出数量。比如:voc数据集上,我们需要预测5个box,每个box预测5个坐标及20个类别,所以需要![]() 个filters,注意与YOLO的不同,YOLO中每个网格预测
个filters,注意与YOLO的不同,YOLO中每个网格预测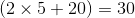 个参数。最后在最后一层
个参数。最后在最后一层![]() 卷积层与倒数第二层卷积层之间加入paathrough层,因此模型增加细粒度特性。
卷积层与倒数第二层卷积层之间加入paathrough层,因此模型增加细粒度特性。
作者在检测数据集上,训练160个epoch,初始学习率为0.001,在第60与90个epoch时,学习率分别缩小10倍,weight decay采用0.0005。采用与YOLO、SSD相同的数据扩充策略。
Stronger
作者提出一种联合训练分类数据和检测数据的方法。在检测数据上学习特别的检测信息比如bounding box坐标及常见对象的分类;只有类别信息的数据用来扩充模型可检测的类别数量。
检测数据和类比数据混合后,在训练时,对于检测数据可以根据YOLO v2的损失函数反向传播对应信息,对于类别数据,只反向传播类别信息。
大多数对待分类的方法是使用softmax层,但是softmax使得类别之间互相排斥,这对类别有包含关系的数据集不适用,比如ImageNet中的“Norfolk terrier”和COCO中的“dog”。对此作者使用一种多标签的模型进行联合数据。
1、Hierarchical classification
ImageNet的标签分布为WordNet,这种结构是图结构而不是树结构。因为树结构不存在交集,而图结构可以。比如:狗这个label即属于犬科也属于家畜。作者没有使用全图结构而是构造一种多层次树——WordTree,简化这一问题。我们可以预测每个节点处条件概率值,如下所示,

进而如果想判断某张图片是否属于某一类别,可以计算下面的式子,依次在各个类别条件概率相乘,

Imagenet 1k有1000类,使用WordTree后,类别扩充到1369,在Imagenet 1k和WordTree1k上预测情况如图5所示,在ImageNet上使用一个softmax,在WordTree上使用多个softmax,每一层次类使用一个softmax,
作者使用与之前相同的训练参数,Darknet-19模型在WordTree1k数据集上top-1 accuracy为71.9%,top-5 accuracy为90.4%。尽管增加了额外369类,但准确率值下降了一点儿。
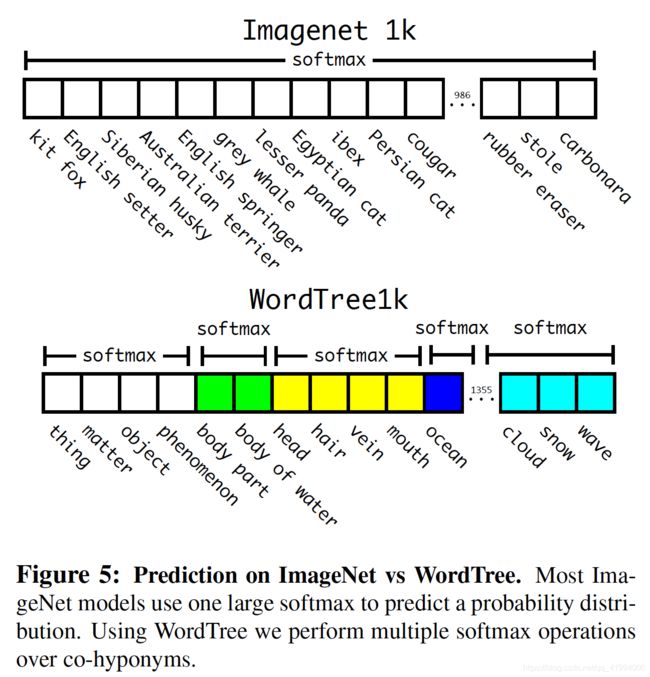
2、Dataset combination with WordTree
使用WordTree可以将多个数据集整合到一起,如图6所示, 将ImageNet和COCO数据集整合。
3、Joint classification and detection
作者通过WordTree联合COCO数据集与ImageNet数据集前9000类,最终形成9418类的数据集。由于ImageNet数据集远大于COCO数据集,作者通过过采样方法(oversample),使ImageNet与COCO数据集比例为4:1.
作者使用新的数据集训练YOLO9000,其结构与YOLO v2相同,但是每个特征图中每个cell输出3个box,而不是5个。
YOLO9000在所以数据上mAP为19.7%,在互斥的156类没有检测信息只有类别信息的数据上,mAP为16.0%。YOLO9000可以很容易学习新的动物种类,但是难以学习类似衣服、装备等类别。动物容易学习是因为从COCO中动物数据很好概括出动物特征,相反,对于衣服、装备等类别,COCO没有相应的bpunding box信息,所以难以检测。检测结果如表7所示,

总结
主要介绍YOLO v2和YOLO9000两种实时检测系统。YOLO v2在各种检测数据集上检测速度快,而且对一些不同分辨率的图片,YOLO v2找到一个速度和准确率的权衡点。
YOLO 9000通过将有检测信息的数据集和只有类别信息的数据集合并(WordTree的方法),可以预测超过9000种目标类别。