【生成式网络】入门篇(二):GAN的 代码和结果记录
GAN非常经典,我就不介绍具体原理了,直接上代码。
感兴趣的可以阅读,里面有更多变体。
https://github.com/rasbt/deeplearning-models/tree/master/pytorch_ipynb/gan
GAN 在 MINIST上的代码和效果
import os
# os.chdir(os.path.dirname(__file__))
import torch
import torch.nn as nn
import torch.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sample_dir = 'samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir, exist_ok=True)
writer = SummaryWriter(sample_dir)
# Hyper-parameters
image_size = 784
latent_size = 64
hidden_size = 256
num_epochs = 200
batch_size = 128
learning_rate = 0.0002
# MNIST
T = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], # 1 for greyscale channels
std=[0.5])])
dataset_train = torchvision.datasets.MNIST(root='../data',
transform=T,
train=True)
dataset_test = torchvision.datasets.MNIST(root='../data',
transform=T,
train=True)
dataloader_train = torch.utils.data.DataLoader(dataset=dataset_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
dataloader_test = torch.utils.data.DataLoader(dataset=dataset_test,
batch_size=batch_size,
shuffle=False)
# GAN model
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid()
)
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh()
)
D = D.to(device)
G = G.to(device)
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr = learning_rate)
g_optimizer = torch.optim.Adam(G.parameters(), lr = learning_rate)
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()
def denorm(x):
out = (x+1)/2
return out.clamp(0, 1)
ld = len(dataloader_train)
accumulated_iter = 0
for epoch in range(num_epochs):
for i, (x, _) in enumerate(dataloader_train):
# forward
x = x.to(device).view(-1, image_size)
real_label = torch.ones(batch_size, 1).to(device)
fake_label = torch.zeros(batch_size, 1).to(device)
# ================================================================== #
# Train the discriminator #
# ================================================================== #
# discriminate real data
real_output = D(x)
d_loss_real = criterion(real_output, real_label)
# generate fake data
z = torch.randn(batch_size, latent_size).to(device)
fake_data = G(z)
# discriminate fake data
fake_output = D(fake_data)
d_loss_fake = criterion(fake_output, fake_label)
# compute the loss
d_loss = d_loss_fake + d_loss_real
reset_grad()
d_loss.backward()
d_optimizer.step()
# ================================================================== #
# Train the generator #
# ================================================================== #
# compute the loss with fake image
z = torch.randn(batch_size, latent_size).to(device)
fake_data = G(z)
fake_output = D(fake_data)
# We train G to maximize log(D(G(z)) instead of minimizing log(1-D(G(z)))
g_loss = criterion(fake_output, real_label)
reset_grad()
g_loss.backward()
g_optimizer.step()
accumulated_iter += 1
writer.add_scalar('loss_d', d_loss.item(), global_step=accumulated_iter)
writer.add_scalar('loss_g', g_loss.item(), global_step=accumulated_iter)
if (i+1) % 10 == 0:
print("Epoch[{}/{}], Step [{}/{}], D Loss: {:.4f}, G Loss: {:.4f}".format(epoch+1, num_epochs, i+1, ld, d_loss.item(), g_loss.item()))
# 根据test数据集来看重建效果
with torch.no_grad():
writer.add_images('images_src', denorm(x).view(-1, 1, 28, 28), global_step=epoch)
# 根据随机变量decode来看重建效果
with torch.no_grad():
writer.add_images('images_gen', denorm(fake_data).view(-1, 1, 28, 28), global_step=epoch)
with torch.no_grad():
x_all = torch.zeros(10, 10, 1, 28, 28).to(device)
for a, da in enumerate(torch.linspace(-0.5, 0.5, 10)):
for b, db in enumerate(torch.linspace(-0.5, 0.5, 10)):
z = torch.zeros(1, latent_size).to(device)
z[0, 0] = da
z[0, 1] = db
fake_data = G(z).view(-1, 1, 28, 28)
x_all[a,b] = denorm(fake_data[0])
x_all = x_all.view(10*10, 1, 28, 28)
imgs = torchvision.utils.make_grid(x_all, pad_value=2,nrow=10)
writer.add_image('images_uniform', imgs, epoch, dataformats='CHW')
writer.close()
生成的图像如下,效果还行
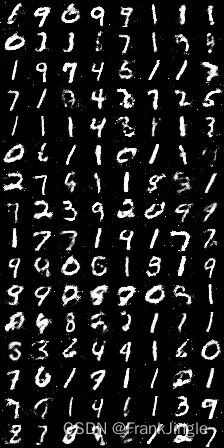
简单的提一下这个loss,可以看出是由Discriminator和Generator两部分loss组成,对于前者来说,真样本label为1,经过G生成的fake样本label为0,这里就可以用BCELoss针对正负样本算loss了。对于Generator而言,虽然是一个变体,但是可以简单理解成,想用fake样本欺骗discriminatory,那就相当于希望G生成的样本label为1,那就把这个送进BCELoss进行计算。
DCGAN 在 Anime上的实验
这里,在二次元的头像任务上,我就使用DCGAN来做实验,DCGAN简单来说,就是用了deep CNN做backbone,网络比较简单
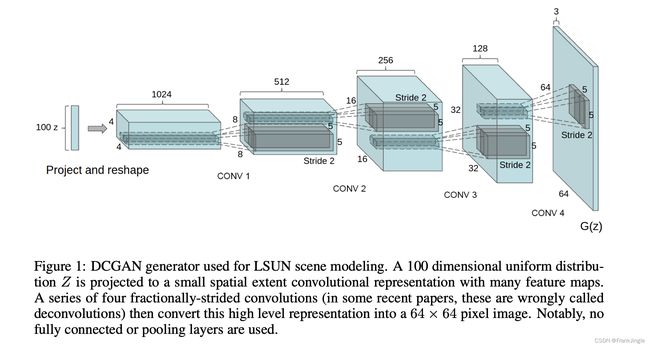

需要注意,在实际实现中,会把latent code比如128维,给写成128 * 1* 1的向量,这样就可以使用全卷积操作了。实际使用代码如下
import os
# os.chdir(os.path.dirname(__file__))
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.datasets as dset
from torchvision import transforms
from torchvision.utils import save_image
from torch.utils.tensorboard import SummaryWriter
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sample_dir = 'samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir, exist_ok=True)
writer = SummaryWriter(sample_dir)
# Hyper-parameters
h_dim = 1024
z_dim = 128
num_epochs = 200
batch_size = 128
learning_rate = 0.0002
data_root = '../data/anime-faces'
# Anime dataset
def is_valid_file(fpath):
fname = os.path.basename(fpath)
return fname[0] != '.'
T = transforms.Compose([
transforms.Scale(64),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)), # bring images to (-1,1)
])
dataset = dset.ImageFolder(
root=data_root,
transform=T,
is_valid_file=is_valid_file
)
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1,
drop_last=True)
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()
def denorm(x):
out = (x+1)/2
return out.clamp(0, 1)
# GAN model
NUM_MAPS_GEN = 64
class G(nn.Module):
def __init__(self, h_dim=h_dim, z_dim=z_dim):
super(G, self).__init__()
self.generator = nn.Sequential(
#
# input size: vector z of size LATENT_DIM
#
nn.ConvTranspose2d(z_dim, NUM_MAPS_GEN*8,
kernel_size=4, stride=1, padding=0,
bias=False), # bias is redundant when using BatchNorm
nn.BatchNorm2d(NUM_MAPS_GEN*8),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN*8 x 4 x 4
#
nn.ConvTranspose2d(NUM_MAPS_GEN*8, NUM_MAPS_GEN*4,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_GEN*4),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN*4 x 8 x 8
#
nn.ConvTranspose2d(NUM_MAPS_GEN*4, NUM_MAPS_GEN*2,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_GEN*2),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN*2 x 16 x 16
#
nn.ConvTranspose2d(NUM_MAPS_GEN*2, NUM_MAPS_GEN,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_GEN),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN x 32 x 32
#
nn.ConvTranspose2d(NUM_MAPS_GEN, 3,
kernel_size=4, stride=2, padding=1,
bias=False),
#
# size: IMAGE_SIZE[2] x 64 x 64
#
nn.Tanh()
)
def forward(self, z):
return self.generator(z)
# GAN model
NUM_MAPS_DIS = 64
class D(nn.Module):
def __init__(self, h_dim=h_dim, z_dim=z_dim):
super(D, self).__init__()
self.discriminator = nn.Sequential(
#
# input size IMAGE_SIZE[2] x IMAGE_SIZE[0] x IMAGE_SIZE[1]
#
nn.Conv2d(3, NUM_MAPS_DIS, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS x 32 x 32
#
nn.Conv2d(NUM_MAPS_DIS, NUM_MAPS_DIS*2,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_DIS*2),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS*2 x 16 x 16
#
nn.Conv2d(NUM_MAPS_DIS*2, NUM_MAPS_DIS*4,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_DIS*4),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS*4 x 8 x 8
#
nn.Conv2d(NUM_MAPS_DIS*4, NUM_MAPS_DIS*8,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_DIS*8),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS*8 x 4 x 4
#
nn.Conv2d(NUM_MAPS_DIS*8, 1,
kernel_size=4, stride=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
return self.discriminator(x)
def reconstruct_loss_binaray(x, y):
return F.binary_cross_entropy(x, y, size_average=False)
def reconstruct_loss_real(x, y):
return F.mse_loss(x, y, size_average=False)
def kl_loss(mu, log_var):
return -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
D = D().to(device)
G = G().to(device)
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr = learning_rate)
g_optimizer = torch.optim.Adam(G.parameters(), lr = learning_rate)
ld = len(data_loader)
accumulated_iter = 0
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
# forward
x = x.to(device)
real_label = torch.ones(batch_size, 1).to(device)
fake_label = torch.zeros(batch_size, 1).to(device)
# ================================================================== #
# Train the discriminator #
# ================================================================== #
# discriminate real data
real_output = D(x)
d_loss_real = criterion(real_output, real_label)
# generate fake data
z = torch.randn(batch_size, z_dim, 1, 1,).to(device)
fake_data = G(z)
# discriminate fake data
fake_output = D(fake_data)
d_loss_fake = criterion(fake_output, fake_label)
# compute the loss
d_loss = 0.5*(d_loss_fake + d_loss_real)
reset_grad()
d_loss.backward()
d_optimizer.step()
# ================================================================== #
# Train the generator #
# ================================================================== #
# compute the loss with fake image
z = torch.randn(batch_size, z_dim, 1, 1,).to(device)
fake_data = G(z)
fake_output = D(fake_data)
# We train G to maximize log(D(G(z)) instead of minimizing log(1-D(G(z)))
g_loss = criterion(fake_output, real_label)
reset_grad()
g_loss.backward()
g_optimizer.step()
accumulated_iter += 1
writer.add_scalar('loss_d', d_loss.item(), global_step=accumulated_iter)
writer.add_scalar('loss_g', g_loss.item(), global_step=accumulated_iter)
if (i+1) % 10 == 0:
print("Epoch[{}/{}], Step [{}/{}], D Loss: {:.4f}, G Loss: {:.4f}".format(epoch+1, num_epochs, i+1, ld, d_loss.item(), g_loss.item()))
with torch.no_grad():
writer.add_images('images_src', denorm(x), global_step=epoch)
writer.add_images('images_gen', denorm(fake_data), global_step=epoch)
with torch.no_grad():
x_all = torch.zeros(20, 20, 3, 64, 64).to(device)
for a, da in enumerate(torch.linspace(-1, 1, 20)):
for b, db in enumerate(torch.linspace(-1, 1, 20)):
z = torch.zeros(1, z_dim, 1, 1).to(device)
z[0, 0] = da
z[0, 1] = db
fake_data = G(z)
x_all[a,b] = denorm(fake_data[0])
x_all = x_all.view(-1, 3, 64, 64)
imgs = torchvision.utils.make_grid(x_all, pad_value=2, nrow=20, normalize=True)
writer.add_image('images_uniform', imgs, epoch, dataformats='CHW')
writer.close()
Improved techniques for training GANs.
这里介绍一个小trick,来自 Improved techniques for training GANs 这篇论文
label smoothing, 把 real image labels 1改成 0.9。
可以简单的这么操作
real_label= torch.ones(targets.size(0)).float().to(device) * 0.9
WGAN
Wasserstein GAN,一种经典的变体,核心思想是一种新的loss,能比较好的提升训练的稳定性。GAN网络训练的重点在于均衡生成器与判别器,若判别器太 强,loss没有再下降,生成器学习不到东西,生成图像的质量 便不会再有提升。原始GAN定义的生成器loss 等价变换为最小化真实分布与生成分布之间的JS散度。我们通过 优化JS散度就能将生成分布拉向真实分布,最终以假乱真。 这个希望在两个分布有所重叠的时候是成立的,但是如果两 个分布完全没有重叠的部分,或者它们重叠的部分可忽略, 那它们的JS散度就一直是 log2,这样在距离远的时候,很难优化。
Wasserstein距离 衡量两个分布之间的距离 Wasserstein距离 优越性在于: 即使两个分布没有任何重叠,也可以反应他们之间的距离。
核心区别是:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的值截断到不超过一个 固定常数c
- 不要用基于动量的优化算法(包括momentum和 Adam),推荐RMSProp
- 生成器每更新一次,评论者都需要训练多次
- WGAN的训练使用1表示真实,-1表示伪造
别人总结的如下
- Not using a sigmoid activation function and just using a linear output layer for the critic (i.e., discriminator).
- Using label -1 instead of 1 for the real images; using label 1 instead of 0 for fake images.
- Using Wasserstein distance (loss) for training both the critic and the generator.
- After each weight update, clip the weights to be in range [-0.1, 0.1].
- Train the critic 5 times for each generator training update.
注意,不同说法里,1和-1到底谁是真实谁是伪造,其实都行,保持一致就ok,我们这里用-1表示真实,1表示伪造。
代码如下
import os
os.chdir(os.path.dirname(__file__))
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.datasets as dset
from torchvision import transforms
from torchvision.utils import save_image
from torch.utils.tensorboard import SummaryWriter
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sample_dir = 'samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir, exist_ok=True)
writer = SummaryWriter(sample_dir)
# Hyper-parameters
h_dim = 1024
z_dim = 128
num_epochs = 200
batch_size = 128
learning_rate = 0.00005
## WGAN-specific settings
num_iter_critic = 5
weight_clip_value = 0.01
data_root = '../data/anime-faces'
# Anime dataset
def is_valid_file(fpath):
fname = os.path.basename(fpath)
return fname[0] != '.'
T = transforms.Compose([
transforms.Scale(64),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)), # bring images to (-1,1)
])
dataset = dset.ImageFolder(
root=data_root,
transform=T,
is_valid_file=is_valid_file
)
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
num_workers=16,
drop_last=True)
def reset_grad():
d_optimizer.zero_grad()
g_optimizer.zero_grad()
def denorm(x):
out = (x+1)/2
return out.clamp(0, 1)
# WGAN model
NUM_MAPS_GEN = 64
class G(nn.Module):
def __init__(self, h_dim=h_dim, z_dim=z_dim):
super(G, self).__init__()
self.generator = nn.Sequential(
#
# input size: vector z of size LATENT_DIM
#
nn.ConvTranspose2d(z_dim, NUM_MAPS_GEN*8,
kernel_size=4, stride=1, padding=0,
bias=False), # bias is redundant when using BatchNorm
nn.BatchNorm2d(NUM_MAPS_GEN*8),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN*8 x 4 x 4
#
nn.ConvTranspose2d(NUM_MAPS_GEN*8, NUM_MAPS_GEN*4,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_GEN*4),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN*4 x 8 x 8
#
nn.ConvTranspose2d(NUM_MAPS_GEN*4, NUM_MAPS_GEN*2,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_GEN*2),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN*2 x 16 x 16
#
nn.ConvTranspose2d(NUM_MAPS_GEN*2, NUM_MAPS_GEN,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_GEN),
nn.ReLU(True),
#
# size: NUM_MAPS_GEN x 32 x 32
#
nn.ConvTranspose2d(NUM_MAPS_GEN, 3,
kernel_size=4, stride=2, padding=1,
bias=False),
#
# size: IMAGE_SIZE[2] x 64 x 64
#
nn.Tanh()
)
def forward(self, z):
return self.generator(z)
# GAN model
NUM_MAPS_DIS = 64
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
class D(nn.Module):
def __init__(self, h_dim=h_dim, z_dim=z_dim):
super(D, self).__init__()
self.discriminator = nn.Sequential(
#
# input size IMAGE_SIZE[2] x IMAGE_SIZE[0] x IMAGE_SIZE[1]
#
nn.Conv2d(3, NUM_MAPS_DIS, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS x 32 x 32
#
nn.Conv2d(NUM_MAPS_DIS, NUM_MAPS_DIS*2,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_DIS*2),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS*2 x 16 x 16
#
nn.Conv2d(NUM_MAPS_DIS*2, NUM_MAPS_DIS*4,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_DIS*4),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS*4 x 8 x 8
#
nn.Conv2d(NUM_MAPS_DIS*4, NUM_MAPS_DIS*8,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(NUM_MAPS_DIS*8),
nn.LeakyReLU(0.2, inplace=True),
#
# size: NUM_MAPS_DIS*8 x 4 x 4
#
nn.Conv2d(NUM_MAPS_DIS*8, 1,
kernel_size=4, stride=1, padding=0),
Flatten(),
# nn.Linear(512, 1),
# nn.Sigmoid() # # WGAN should have linear activation
)
def forward(self, x):
return self.discriminator(x)
def reconstruct_loss_binaray(x, y):
return F.binary_cross_entropy(x, y, size_average=False)
def reconstruct_loss_real(x, y):
return F.mse_loss(x, y, size_average=False)
def kl_loss(mu, log_var):
return -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
def wasserstein_loss(y_true, y_pred):
return torch.mean(y_true * y_pred)
D = D().to(device)
G = G().to(device)
criterion = nn.BCELoss()
d_optimizer = torch.optim.RMSprop(D.parameters(), lr = learning_rate)
g_optimizer = torch.optim.RMSprop(G.parameters(), lr = learning_rate)
ld = len(data_loader)
accumulated_iter = 0
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
# forward
x = x.to(device)
real_label = -torch.ones(batch_size, 1).to(device)
fake_label = torch.ones(batch_size, 1).to(device)
# ================================================================== #
# Train the discriminator #
# ================================================================== #
# WGAN: Multiple loops for the discriminator
for _ in range(num_iter_critic):
# discriminate real data
real_output = D(x)
d_loss_real = wasserstein_loss(real_output, real_label)
# generate fake data
z = torch.randn(batch_size, z_dim, 1, 1,).to(device)
fake_data = G(z)
# discriminate fake data
fake_output = D(fake_data)
d_loss_fake = wasserstein_loss(fake_output, fake_label)
# compute the loss
d_loss = 0.5*(d_loss_fake + d_loss_real)
reset_grad()
d_loss.backward()
d_optimizer.step()
# WGAN:
for p in D.parameters():
p.data.clamp_(-weight_clip_value, weight_clip_value)
# ================================================================== #
# Train the generator #
# ================================================================== #
# compute the loss with fake image
z = torch.randn(batch_size, z_dim, 1, 1,).to(device)
fake_data = G(z)
fake_output = D(fake_data)
# We train G to maximize log(D(G(z)) instead of minimizing log(1-D(G(z)))
g_loss = wasserstein_loss(fake_output, real_label)
reset_grad()
g_loss.backward()
g_optimizer.step()
accumulated_iter += 1
writer.add_scalar('loss_d', d_loss.item(), global_step=accumulated_iter)
writer.add_scalar('loss_g', g_loss.item(), global_step=accumulated_iter)
if (i+1) % 10 == 0:
print("Epoch[{}/{}], Step [{}/{}], D Loss: {:.4f}, G Loss: {:.4f}".format(epoch+1, num_epochs, i+1, ld, d_loss.item(), g_loss.item()))
with torch.no_grad():
writer.add_images('images_src', denorm(x), global_step=epoch)
writer.add_images('images_gen', denorm(fake_data), global_step=epoch)
with torch.no_grad():
x_all = torch.zeros(20, 20, 3, 64, 64).to(device)
for a, da in enumerate(torch.linspace(-1, 1, 20)):
for b, db in enumerate(torch.linspace(-1, 1, 20)):
z = torch.zeros(1, z_dim, 1, 1).to(device)
z[0, 0] = da
z[0, 1] = db
fake_data = G(z)
x_all[a,b] = denorm(fake_data[0])
x_all = x_all.view(-1, 3, 64, 64)
imgs = torchvision.utils.make_grid(x_all, pad_value=2, nrow=20, normalize=True)
writer.add_image('images_uniform', imgs, epoch, dataformats='CHW')
writer.close()
# WGAN-GP
这是一个针对WGAN的改进工作,生成器与WGAN完全相同,只有一下几个针对discriminator的修改
- 在discriminatory的损失函数中加入一个梯度惩罚项
- 不要裁剪discriminatory的权重,这样会造成不稳定,我们通过梯度惩罚项来惩罚那些范数偏离1的梯度
- 不要在discriminatory中使用BN层,因为BN会在同一批次的图像之间创建相关性,导致梯度惩罚损失有效性降低。
- 使用Adam优化器,该优化器是公认最佳的WGAN-GP的优化器
在实际梯度惩罚过程中,每一处都计算梯度非常麻烦,因此只评估少数几个点上的梯度,我们把真实图像批次与伪造图像批次之间的随机位置逐像素进行插值,以生成一些图像。
可以参考
def compute_gradient_penalty(D, real_samples, fake_samples):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = Tensor(np.random.random((real_samples.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
d_interpolates = D(interpolates)
fake = Variable(Tensor(real_samples.shape[0], 1).fill_(1.0), requires_grad=False)
# Get gradient w.r.t. interpolates
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
其他
最后推荐一个github
库,https://github.com/eriklindernoren/PyTorch-GAN,
里面实现了很多的GAN,且代码非常简洁易读,感兴趣的可以深入研究一下。