GAN 简介
GAN
原理:
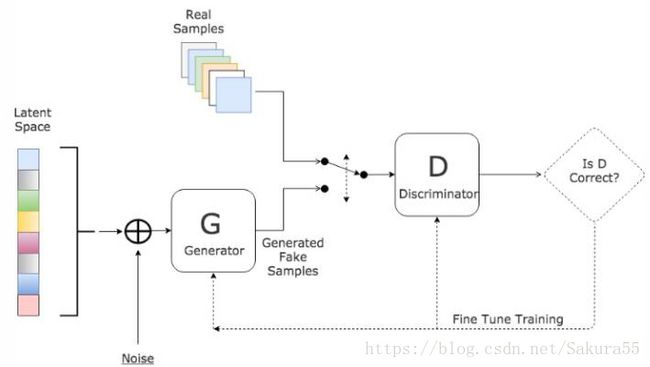
GAN 的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上来说,就是通过生成网络 G(Generator)和判别网络 D(Discriminator)不断博弈,进而使 G 学习到数据的分布,如果用到图片生成上,则训练完成后,G 可以从一段随机数中生成逼真的图像。
- G 是一个生成网络,其输入为一个随机噪音,在训练中捕获真实数据的分布,从而生成尽可能真实的数据并让 D 犯错
- D 是一个判别网络,判别生成的数据是不是“真实的”。它的输入参数是 x,输出 D(x) 代表 x 为真实数据的概率,如果为 1,就代表 100% 是真实的数据,而输出为 0,就代表不可能是真实的数据
为了从数据 x 中学习到生成器的分布 p g p_g pg,我们定义一个输入噪音变量 p z ( z ) p_z(z) pz(z),然后将其映射到数据空间得到 G ( z ; θ g ) G(z;\theta_g) G(z;θg)。 D ( x ; θ d ) D(x; \theta_d) D(x;θd) 输出是一个数,代表 x x x 来自真实数据而不是 p g p_g pg 的概率。
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ l o g ( D ( x ) ) ] + E z ∼ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] ① 训 练 D 来 最 大 化 辨 别 能 力 : max D V ( D , G ) = E x ∼ p d a t a ( x ) [ l o g ( D ( x ) ) ] + E z ∼ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] ② 训 练 G 来 最 小 化 l o g ( 1 − D ( G ( z ) ) ) : min G V ( D , G ) = E z ∼ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] ③ \begin{aligned} &\min_G \max_D V(D,G) = E_{x∼p_{data}(x)}[log(D(x))]+E_{z∼p_{z}(z)}[log(1−D(G(z)))] \qquad ①\\ &训练 D 来最大化辨别能力:\quad \max_D V(D,G)=E_{x∼p_{data}(x)}[log(D(x))]+E_{z∼p_z(z)}[log(1−D(G(z)))]\qquad② \\ &训练 G 来最小化log(1−D(G(z))):\quad \min_G V(D,G)=E_{z∼p_z(z)}[log(1−D(G(z)))]\qquad③ \\ \end{aligned} GminDmaxV(D,G)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z)[log(1−D(G(z)))]①训练D来最大化辨别能力:DmaxV(D,G)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z)[log(1−D(G(z)))]②训练G来最小化log(1−D(G(z))):GminV(D,G)=Ez∼pz(z)[log(1−D(G(z)))]③
注: max D \max_D maxD 表示令 D ( x ) D(x) D(x) 尽可能大以便找出真实数据,而令 D ( G ( z ) ) D(G(z)) D(G(z)) 尽可能小以便区分出伪造数据,最后导致 ② 式尽可能大; min G \min_G minG 表示令 D ( G ( z ) ) D(G(z)) D(G(z)) 尽可能大从而混淆判别器,最后导致 ③ 式尽可能小。训练早期,G 的拟合程度很低,D 可以被训练得很好,导致 log(1-D(G(z))) 趋于 0,进而使回传梯度很小,导致训练效果不行。因此,比起 minimize log(1-D(G(z))),maximize log(D(G(z))) 会更好。
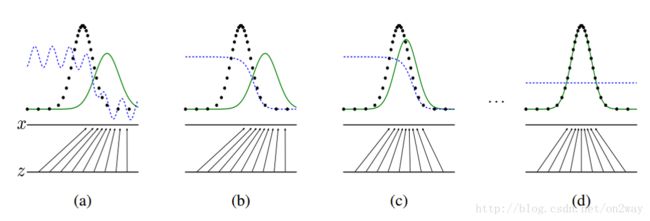
注:将随机噪音 z 映射到 x 上(x = G(z)),使 x 尽可能拟合真实数据 data 的分布。绿色实线为生成的数据 p_g,黑色点为真实数据 p_data,蓝色虚线为判别器 D。每次训练 G 都使 p_g 尽可能拟合 p_data,而判别器 D 则会调整从而尽可能将 p_g 和 p_data 区分开。当 D(x) = 0.5 时,判别器将无法区分真假。
算法:

小结:
命题1:当 G 被固定住时,最优的辨别器 D 如下
D G ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) = 1 2 ∈ [ 0 , 1 ] D_G^*(x) = \frac{p_{data}(x)}{p_{data}(x)+p_g(x)} = \frac{1}{2} \in [0, 1] DG∗(x)=pdata(x)+pg(x)pdata(x)=21∈[0,1]
证明:
E x ∼ p f ( x ) = ∫ x p ( x ) f ( x ) d x x = g ( z ) V ( G , D ) = ∫ x p d a t a ( x ) log ( D ( x ) ) d x + ∫ z p z ( z ) log ( 1 − D ( g ( z ) ) ) d z = ∫ x p d a t a ( x ) log ( D ( x ) ) + p g ( x ) log ( 1 − D ( x ) ) d x 记 : V ( G , D ) = ∫ x a ⋅ log ( y ) + b ⋅ log ( 1 − y ) d x 则 函 数 y → a ⋅ log ( y ) + b ⋅ log ( 1 − y ) 在 [ 0 , 1 ] 里 最 大 值 为 : a a + b = p d a t a ( x ) p d a t a ( x ) + p g ( x ) \begin{aligned} &E_{x∼p}f(x) = \int_xp(x)f(x)dx \qquad x = g(z) \\ &V(G, D) = \int_x p_{data}(x)\log{(D(x))}dx + \int_zp_z(z)\log{(1-D(g(z)))}dz = \int_x p_{data}(x)\log{(D(x))} + p_g(x)\log{(1-D(x))}dx\\ &记:V(G, D) = \int_x a \cdot \log(y) + b \cdot \log{(1-y)} dx\qquad \\ &则函数 \quad y \rightarrow a \cdot \log(y) + b \cdot \log{(1-y)} 在 [0, 1]里最大值为:\quad \frac{a}{a+b} = \frac{p_{data}(x)}{p_{data}(x)+p_g(x)} \end{aligned} Ex∼pf(x)=∫xp(x)f(x)dxx=g(z)V(G,D)=∫xpdata(x)log(D(x))dx+∫zpz(z)log(1−D(g(z)))dz=∫xpdata(x)log(D(x))+pg(x)log(1−D(x))dx记:V(G,D)=∫xa⋅log(y)+b⋅log(1−y)dx则函数y→a⋅log(y)+b⋅log(1−y)在[0,1]里最大值为:a+ba=pdata(x)+pg(x)pdata(x)
定理1:当且仅当 p g p_g pg = p d a t a p_{data} pdata 时, C(G) 取得全局最小值,为 -log4
C ( G ) = max D V ( G , D ) = E x ∼ p d a t a [ l o g ( D G ∗ ( x ) ) ] + E z ∼ p z [ l o g ( 1 − D G ∗ ( G ( z ) ) ) ] = E x ∼ p d a t a [ l o g ( D G ∗ ( x ) ) ] + E x ∼ p g [ l o g ( 1 − D G ∗ ( x ) ] = E x ∼ p d a t a [ l o g p d a t a ( x ) p d a t a ( x ) + p g ( x ) ] + E x ∼ p g [ l o g p g ( x ) p d a t a ( x ) + p g ( x ) ] \begin{aligned} C(G) &= \max_DV(G, D) = E_{x∼p_{data}}[log(D_G^*(x))]+E_{z∼p_z}[log(1−D_G^*(G(z)))]\\ &= E_{x∼p_{data}}[log(D_G^*(x))]+E_{x∼p_g}[log(1−D_G^*(x)] = E_{x∼p_{data}}[log\frac{p_{data}(x)}{p_{data}(x)+ p_g(x)}]+E_{x∼p_g}[log\frac{p_g(x)}{p_{data}(x)+ p_g(x)}]\\ \end{aligned} C(G)=DmaxV(G,D)=Ex∼pdata[log(DG∗(x))]+Ez∼pz[log(1−DG∗(G(z)))]=Ex∼pdata[log(DG∗(x))]+Ex∼pg[log(1−DG∗(x)]=Ex∼pdata[logpdata(x)+pg(x)pdata(x)]+Ex∼pg[logpdata(x)+pg(x)pg(x)]
KL 散度:KL(p||q) = E x ∼ p log p ( x ) q ( x ) E_{x∼p}\log{\frac{p(x)}{q(x)}} Ex∼plogq(x)p(x)
证明:
E x ∼ p d a t a [ − log 2 ] + E x ∼ p g [ − log 2 ] = − log 4 , 则 C ( G ) = − log ( 4 ) + K L ( p d a t a ∣ ∣ p d a t a + p g 2 ) + K L ( p g ∣ ∣ p d a t a + p g 2 ) = − log ( 4 ) + 2 ⋅ J S D ( p d a t a ∣ ∣ p g ) 由 于 J S D 非 负 , 且 仅 当 其 两 个 参 数 相 等 时 才 为 0 , 故 , 当 p d a t a = p g 时 C ( G ) 取 最 小 值 为 − log ( 4 ) \begin{aligned} &E_{x∼p_{data}}[-\log2] + E_{x∼p_g}[-\log2] = -\log4,则 \\ &C(G) = -\log(4) + KL(p_{data} || \frac{p_{data} + p_g}{2}) + KL(p_g || \frac{p_{data} + p_g}{2}) = -\log(4) + 2 \cdot JSD(p_{data} || p_g) \\ &由于 JSD 非负,且仅当其两个参数相等时才为 0,故,当 p_{data} = p_g 时 C(G) 取最小值为 -\log(4) \end{aligned} Ex∼pdata[−log2]+Ex∼pg[−log2]=−log4,则C(G)=−log(4)+KL(pdata∣∣2pdata+pg)+KL(pg∣∣2pdata+pg)=−log(4)+2⋅JSD(pdata∣∣pg)由于JSD非负,且仅当其两个参数相等时才为0,故,当pdata=pg时C(G)取最小值为−log(4)
命题2:当 G 和 D 有足够容量,且算法 1 中我们允许每一步 D 是可以达到他的最优解。那么如果我们对 G 的优化是去迭代下面这一步骤,则 p_g 会收敛到 p_{data}
E x ∼ p d a t a [ log D G ∗ ( x ) ] + E x ∼ p g [ log ( 1 − D G ∗ ( x ) ) ] E_{x∼p_{data}}[\log{D_G^*(x)}] + E_{x∼p_g}[\log{(1 - D_G^*(x))}] Ex∼pdata[logDG∗(x)]+Ex∼pg[log(1−DG∗(x))]
优缺点:
特点:
- 相比较传统的模型,GAN 存在两个不同的网络,而不是单一的网络,并且训练方式采用的是对抗训练方式
- GAN 中 G 的梯度更新信息来自判别器 D,而不是来自数据样本
优点:
- GAN 是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链
- 相比其他所有模型, GAN 可以产生更加清晰、真实的样本
对 f 期望的求导等价于对 f 自己求导 => 通过误差的反向传递对 GAN 进行求解: lim σ → 0 ∇ x E ϵ ∼ N ( 0 , σ 2 I ) f ( x + ϵ ) = ∇ x f ( x ) \lim_{\sigma\rightarrow0}\nabla_xE_{\epsilon∼N(0, \sigma^2I)}f(x+\epsilon) = \nabla_xf(x) limσ→0∇xEϵ∼N(0,σ2I)f(x+ϵ)=∇xf(x)
- GAN 采用的是一种无监督学习方式训练,可以被广泛用在无监督学习和半监督学习领域。但却用一个有监督学习的损失函数来做无监督学习,在训练上会高效很多
- 相比于变分自编码器(VAE),GANs 没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置。因为他们优化对数似然的下界,而不是似然度本身,这导致了 VAEs 生成的实例比 GANs 更模糊
- 相比 VAE,GANs 没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布。换句话说,GANs 是渐进一致的,而 VAE 是有偏差的
由于 GAN 的无监督,在生成过程中,G 就会按照自己的意思天马行空生成一些“诡异”的图片,可怕的是 D 还可能给一个很高的分数。这就是无监督目的性不强所导致的,所以在同年的NIPS大会上,有一篇论文 conditional GAN 就加入了监督性进去,将可控性增强,表现效果也好很多
缺点:
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,但有时候做不到。我们还没有找到很好的达到纳什均衡的方法,所以训练 GAN 相比 VAE 或者 PixelRNN 是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多
- GAN 不适合处理离散形式的数据,比如文本
- GAN 存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
GAN 的目的是在高维非凸的参数空间中找到纳什均衡点,GAN 的纳什均衡点是一个鞍点,但是 SGD 只会找到局部极小值,因为 SGD 解决的是一个寻找最小值的问题,GAN 是一个博弈问题。同时,SGD容易震荡,容易使GAN训练不稳定。因此,GAN 中的优化器不常用 SGD
补充:Generative Adversarial Net、GAN(生成对抗神经网络)原理解析、简单理解与实验生成对抗网络GAN、blogs from CSDN