基于Dockerfile构建深度学习模型(OpenPCdet)
文章目录
docker的安装(gpu)
Linux上安装显卡驱动
安装docker
安装 NVIDIA Container Toolkit
编写dockerfile
Docker镜像与容器的启动,打包导出
遇到的一些问题:
no module name 'pcdet'
libGL.so.1

以OpenPCdet为例
参考:[Docker] 镜像打包训练好的模型_Emery_learning的博客-CSDN博客
docker的安装(gpu)
参考:Docker部署深度学习服务器,CUDA+cudnn+ssh_铜锣烧阿南Anan的博客-CSDN博客
以下是安装的步骤:
Linux上安装显卡驱动
参考:ubuntu安装显卡驱动的三种方法_u014682691的专栏-CSDN博客_ubuntu安装显卡驱动
网速好的推荐第一种方法,安装完成,输入nvidia-smi,会提示有点问题,重启电脑即可恢复正常
也可以考虑不更新自己的驱动
安装docker
1.如果安装了旧版本的docker,需要先卸载!
sudo apt-get remove docker docker-engine docker.io containerd runc2.更新apt包索引并安装包以允许apt通过 HTTPS 使用存储库
sudo apt-get update
sudo apt-get install \
ca-certificates \
curl \
gnupg \
lsb-release3.添加Docker官方的GPG密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg4.使用以下命令设置稳定版存储库。
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null5.安装Docker引擎
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io6.此时docker已经安装好了。运行如下命令来测试一下
sudo docker run hello-world安装 NVIDIA Container Toolkit
参考:Installation Guide — NVIDIA Cloud Native Technologies documentation
1.设置稳定版的存储库和GPG密钥
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list2.更新源并安装nvidia-container-toolkit
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker3.设置好默认运行后重启Docker守护进程完成安装
sudo systemctl restart docker4.此时,可以通过运行基本 CUDA 容器来测试工作设置
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smips:上面是我经常出错的地方,之前安装的时候可能没有严格按照步骤,就出错了。(有的时候前一天是正常的,关电脑第二天打开又出错了)提示
could not select device driver "" with capabilities: [[gpu]]。
![]()
如果出现上面的问题,就把docker卸载了,重新再严格按照前面的步骤执行一遍。或者再等等,重启一下电脑
如果正常,docker(gpu)的就安装成功了。下面就是关键的基于Dockerfile构建镜像,创建容器,搭建环境的步骤了。
编写dockerfile
选定一个基本的dockerfile(以OpenPCdet为例)
刚好前几天Openpcdet的作者提供了一个dockerfile,我就以它为基础,修改成适合自己环境
OpenPCDet docker地址:https://github.com/open-mmlab/OpenPCDet/tree/master/docker
其中的dockerfile地址:https://github.com/open-mmlab/OpenPCDet/blob/master/docker/Dockerfile
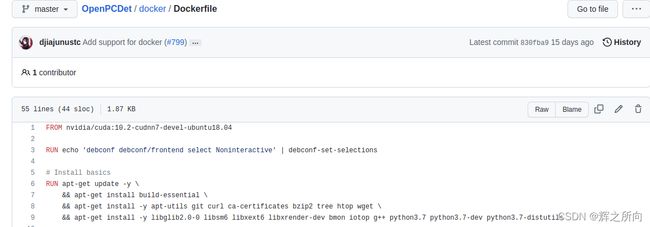
其内容有些多,包含了一些安装环境相关的内容,我们可以在本地创建一个文件夹,然后创建一个Dockerfile
touch Dockerfile
把上面的内容复制到里面,参考里面的一些写法,根据自己的环境修改。
比如我本地的环境是 RTX3090,一般安装的cuda环境都是11.1 配合cudnn8版本的。那么我们就需要更改基础镜像,接着是要安装相应的pytorch 1.8 ,然后我还想把docker镜像里面的源换成清华源,直接把下好的OpenPCDet目录放到这个目录下。
修改后的关键部分如下:
FROM nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04
MAINTAINER Wjh
RUN echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections
RUN echo "export LANG=C.UTF-8" >>/etc/profile \
&& mkdir -p /.script \
&& cp /etc/apt/sources.list /etc/apt/sources.list.bak \
&& echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse\n\
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse\n\
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse\n\
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse" >/etc/apt/sources.list
# Install basics
RUN apt-get update -y \
&& apt-get install build-essential \
&& apt-get install -y apt-utils git curl ca-certificates bzip2 tree htop wget \
&& apt-get install -y libglib2.0-0 libsm6 libxext6 libxrender-dev bmon iotop g++ python3.7 python3.7-dev python3.7-distutils
...
# Install torch and torchvision
# See https://pytorch.org/ for other options if you use a different version of CUDA
RUN pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
WORKDIR /root
COPY . /root
...
RUN pip install spconv-cu111 说明一下核心的内容:
FROM nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04 代表nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04 作为基础镜像(理解为父镜像)
MAINTAINER 设置镜像的作者,可以是任意字符串
RUN xxx 后面跟的就是在这个镜像里运行的命令
WORKDIR : 设置工作目录,上面的例子是设置为root ,我们自己也可以设置成其他的名字
COPY :用法为 COPY [src] [dest],上面的src为“.”,意思是将当前目录下的所有文件拷贝到dest(镜像目录中)
上面的基础镜像需要去网上的docker 寻找适合自己的。可以先搜索cuda,找到官方镜像,再找到自己需要的cuda版本
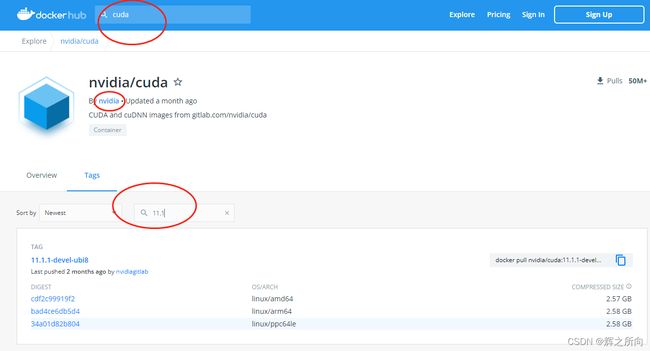
比如根据我需要的环境,选择了下面这个
(附上链接:Docker Hub)

网上推荐装devel版本,是完整运行的,把上图pull指示的复制下来,按照规则放在Dockerfile中的第一行 From xxx
在当前目录下执行build命令,构建docker镜像
docker build ./ -t xxx #xxx是自己取的名字 ps:dockerfile基本语法参考:如何制作容器镜像?_容器镜像服务 SWR_常见问题_共享版_通用类_华为云
Docker镜像与容器的启动,打包导出
查看当前有的镜像
docker images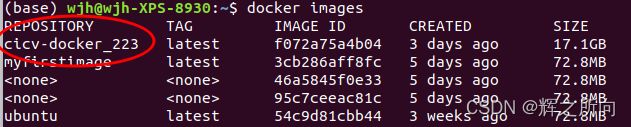
创建完成后,从镜像创建容器,进入构建好的镜像容器
docker run -it --name xxx --gpus all xxxx
#(前面的name自己取,不取的话系统会随机取,后面的xxx为容器id或者名字)ctrl + d 可以退出 当前容器
注意再次进入刚刚创建好的镜像容器,就不能用上面的那个命令了,一个name会固定一个容器,如果想要进入刚刚那个容器,先查看container id
查看生成的容器 ID(CONTAINER ID)
docker ps -a运行该容器,并进入bash界面
docker start container_ID #如果提示没有运行,就输入这个命令启动容器
docker exec -it container_ID /bin/bash #进入bash界面可以将训练好的模型文件以及相关代码从本地复制到容器里
docker cp local_path container_ID:container:path进去就相当于一个配置好环境的虚拟环境了,可以在这里面运行代码,进行测试。
将该容器生成新的镜像
docker commit container_ID your_image_name #比如 your_image_name = my/image:v1
#或者 只输入image_name获取到新的镜像id:
docker images打包新镜像,生成tar文件
docker save image_ID > XXX.tar
## docker save -o my_example.tar my_image_name:latest (latest是默认设置的镜像容器版本)
在其他主机上(或本地)导入上面的镜像
docker load -i my_example.tar再执行 docker images 就能看到导入的镜像了
接着按上面的步骤,运行其中的容器。
遇到的一些问题:
no module name 'pcdet'
在容器内编译后,运行代码出现上面的提示,因此需要在容器内说明一下,执行以下命令:
export PYTHONPATH=$HOME/Cicv_task1_223/:$PYTHONPATH即可正常运行
libGL.so.1
提示:libGL.so.1: cannot open shared object file: No such file or directory
在镜像环境内
apt update
apt install libgl1-mesa-glx