【重参数化】《Diverse Branch Block: Building a Convolution as an Inception-like Unit》 2021
摘要:我们提出一种通用的卷积网络构造块用来在不增加任何推理时间的前提下提升卷积网络的性能。我们将这个块命名为分离分支块(Diverse Branch Block)。通过结合不同尺寸和复杂度的分离分支(包括串联卷积、多尺度卷积和平均池化层)来增加特征空间的方法,它提升了单个卷积的表达能力。完成训练后,一个DBB(Diverse Branch Block)可以被等价地转换为一个单独的卷积操作以方便部署。不同于那些新颖的卷积结构的改进方式,DBB让训练时微结构复杂化同时维持大规模结构,因此我们可以将它作为任意结构中通用卷积层的一种嵌入式替代形式。通过这种方式,我们能够将模型训练到一个更高的表现水平,然后在推理时转换成原始推理时间的结构。
主要贡献点:
(1) 我们建议合并大量的微结构到不同的卷积结构中来提升性能,但是维持原始的宏观结构。
(2)我们提出DBB,一个通用构造块结构,概括六种转换来将一个DBB结构转化成一个单独卷积,因为对于用户来说它是无损的。
(3)我们提出一个Inception-like DBB结构实例(Fig 1),并且展示它在ImageNet、COCO detection 和CityScapes任务中获得性能提升。

结构重参数化
本文和一个并发网络RepVGG[1]是第一个使用结构重参数化来命名该思路------使用从其他结构转化来的参数确定当前结构的参数。一个之前的工作ACNet[2]也可以被划分为结构重参数化,它提出使用非对称卷积块来增强卷积核的结构(i.e 十字形结构)。相比于DBB,它被设计来提升卷积网络(在没有额外推理时间损失的条件下)。这个流水线也包含将一个训练好的模型转化为另一个。但是,ACNet和DBB的区别是:ACNet的思想被激发是基于一个观察,这个观察是网络结构的参数在过去有更大的量级,因此寻找方法让参数量级更大,然而我们关注一个不同的点。我们发现 平均池化、1x1 conv 和 1x1-kxk串联卷积是更有效的,因为它们提供了不同复杂度的路线,以及允许使用更多训练时非线性化。除此以外,ACB结构可以看作是DBB结构的一种特殊形式,因为那个1xk和kx1卷积层能够被扩大成kxk(via Transform VI(Fig.2)),然后合并成一个平方核(via Transform II)。
3 分离分支结构
3.1 卷积的线性性
一个卷积操作可以表示为 ![]() ,其中
,其中![]() 为输入tensor,
为输入tensor, ![]() 为输出tensor。卷积核表示为一个四阶tensor
为输出tensor。卷积核表示为一个四阶tensor ![]() , 偏置为
, 偏置为![]() 。将加偏置的操作表示为
。将加偏置的操作表示为![]() 。
。
因为,在第j个输出通道(h,w)位置的值可以由以下公式给出: ,其中
,其中![]() 表示输入帧I的第c个通道上的一个滑动窗,对应输出帧O的坐标(h,w)。从上式可以看出,卷积操作具有齐次性和加法性。
表示输入帧I的第c个通道上的一个滑动窗,对应输出帧O的坐标(h,w)。从上式可以看出,卷积操作具有齐次性和加法性。
![]()
![]()
注意:加法性成立的条件是两个卷积具有相同的配置(即通道数、核尺寸、步长和padding等)。
3.2 分离分支的卷积
在这一小节,我们概括六种转换形式(Fig.2)来转换一个具有batch normalization(BN)、branch addition、depth concatenation、multi-scale operations、avarage pooling 和 sequences of convolutions的DBB分支。

Transform I:a conv for conv-BN 我们通常会给一个卷积配备配备一个BN层,它执行逐通道正则化和线性尺度放缩。设j为通道索引,![]() 分别为累积的逐通道均值和标准差,
分别为累积的逐通道均值和标准差,![]() 分别为学习的尺度因子和偏置项,对应输出通道j为
分别为学习的尺度因子和偏置项,对应输出通道j为
![]()
卷积的齐次性允许我们融合BN操作到前述的conv来做推理。在实践中,我们仅仅建立一个拥有卷积核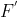 和偏置
和偏置![]() , 用从原始BN序列的参数转换来的值来赋值。我们为每个输出通道j构造
, 用从原始BN序列的参数转换来的值来赋值。我们为每个输出通道j构造![]()
![]() ,
, ![]() (6)
(6)
Transform II a conv for branch addition 卷积的加法性确保如果有两个或者多个具有相同配置的卷积层相加,我们能够将它们合并到一个单独的卷积里面。对于conv-BN,我们应该首先执行Transform I。很明显的,通过下面的公式我们能够合并两个卷积
![]() (7)
(7)
上述公式只有在两个卷积拥有相同配置时才成立。尽管合并上述分支能够在一定程度上增强模型,我们希望结合不同分支来进一步提升模型性能。在后面,我们介绍一些分支的形式,它们能够等价地被转化为一个单独的卷积。在通过多个转化来为每一个分支构造KxK的卷积之后,我们使用Transform II 将所有分支合并到一个conv里面。
Transform III: a conv for sequential convolutions 我们能够合并一个1x1 conv-BN-kxk conv序列到一个kxk conv里面。我们暂时假设卷积是稠密的(即 组数 groups=1)。组数groups>1的情形将会在Transform IV中实现。我们假定1x1和kxk卷积层的核形状分别是DxCx1x1和ExDxKxK,这里D指任意值。首先,我们将两个BN层融合到两个卷积层里面,由此获得![]() 。输出是
。输出是
![]() (8)
(8)
我们期望用一个单独卷积的核和偏置来表达,设![]() , 它们满足
, 它们满足![]() 。对方程(8)应用卷积的加法性,我们有
。对方程(8)应用卷积的加法性,我们有
![]() (10)
(10)
因为![]() 是一个1x1 conv,它只执行逐通道线性组合,没有空间聚合操作。通过线性重组KxK卷积核中的参数,我们能够将它合并到一个KxK的卷积核里面。容易证明的是,这样的转换可以由一个转置卷积实现:
是一个1x1 conv,它只执行逐通道线性组合,没有空间聚合操作。通过线性重组KxK卷积核中的参数,我们能够将它合并到一个KxK的卷积核里面。容易证明的是,这样的转换可以由一个转置卷积实现:
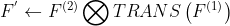 ,
,
其中![]() 是由
是由![]() 转置获得的tensor张量。方程(10)的第二项是作用于常量矩阵上的卷积操作,因此它的输出也是一个常量矩阵。用表达式来说明,设
转置获得的tensor张量。方程(10)的第二项是作用于常量矩阵上的卷积操作,因此它的输出也是一个常量矩阵。用表达式来说明,设![]() 是一个常数矩阵,其中的每个元素都等于p。*是一个2D 卷积操作,W为一个2D 卷积核。转换结果就是一个常量矩阵,这个常量矩阵是p 与 所有核元素之和 的乘积,即
是一个常数矩阵,其中的每个元素都等于p。*是一个2D 卷积操作,W为一个2D 卷积核。转换结果就是一个常量矩阵,这个常量矩阵是p 与 所有核元素之和 的乘积,即
![]()
基于以上观察,我们构造 。然后,容易证明
。然后,容易证明![]() 。
。
因此我们有![]()
显而易见地,对于一个zero-pads 的KxK卷积,方程(8)并不成立,因为![]() 并不对
并不对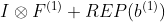 的结果做卷积操作(如果有一个零元素的额外的圈,方程(8)成立)。解决方案有A)用padding配置第一个卷积,第二个卷积不用,B)通过
的结果做卷积操作(如果有一个零元素的额外的圈,方程(8)成立)。解决方案有A)用padding配置第一个卷积,第二个卷积不用,B)通过![]() 做pad操作。后者的一个有效实现是定制第一个BN层,为了(1)如通常的batch-normalize输入。(2)计算
做pad操作。后者的一个有效实现是定制第一个BN层,为了(1)如通常的batch-normalize输入。(2)计算![]() (通过方程(6))。(3)用
(通过方程(6))。(3)用![]() pad batch-normalized结果,例如 用一圈
pad batch-normalized结果,例如 用一圈![]() pad 每一个通道j 。
pad 每一个通道j 。
Transform IV: a conv for depth concatenation Inception 单元使用深度concatenation来组合不同分支。当每个分支都只包含一个相同配置的卷积时,深度concatenation等价于一个卷积,它的核在不同的输出通道上concatenation(比如我们公式中的第一个轴)假设![]() 。我们concatenate它们到
。我们concatenate它们到![]() 。显然地
。显然地
![]() (16)
(16)
Transform IV 可以非常方便地将Transform III 扩展到 groupwise(即 groups > 1) 的情景。直觉上,一个groupwise 卷积将输入分割成g个并行的组,单独卷积它们,然后concatenate形成输出。为了代替g-group卷积,我们建立一个DBB结构,这个结构的所有卷积层有相同的组g。为了转换一个1x1-KxK序列,我们等价地分割它们成为g组,单独执行Transform III, 然后concatenate获得输出(如图Fig3所示)。
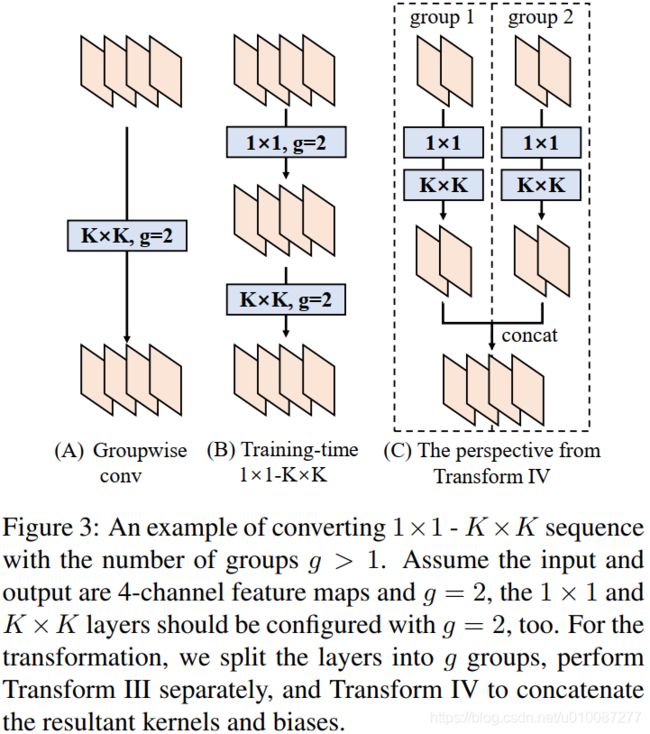
Transform V: a conv for average pooling 一个作用于C通道的核尺寸为K,步长为s的平均池化层等价于一个拥有相同核尺寸K,步长s的卷积层。这样的核![]() 可以被构造为
可以被构造为
![]() (17)
(17)
就像一个通常的平均池化操作,当s>1时执行降采样操作,当s=1时保持相同尺寸。
Transform VI: a conv for multi-scale convolutions 考虑一个![]() 等价于一个拥有相同zero padding的
等价于一个拥有相同zero padding的 ![]() 核。特别地,
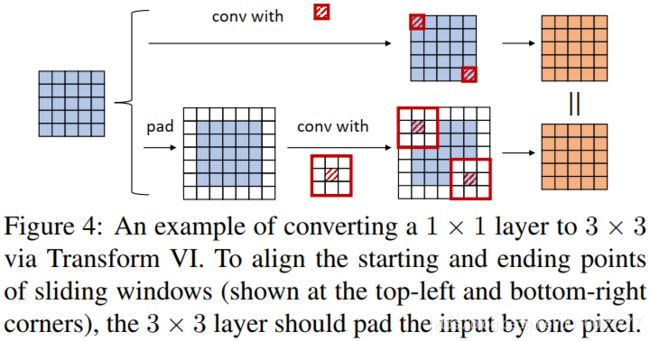
核。特别地,![]() 卷积是格外实用的,因为它们能够有效实现。应该对输入作pad操作来对齐滑动窗(Fig4)。
卷积是格外实用的,因为它们能够有效实现。应该对输入作pad操作来对齐滑动窗(Fig4)。
3.3 An Inception-like DBB Instance
我们提出了一种DBB结构的表达实例,它的通用性和灵活性允许大量的灵活实例。像 Inception结构,我们使用1x1, 1x1-KxK,1x1-AVG去提升原始KxK层。对于1x1-KxK分支,我们设置内部通道数等于输入,初始化1x1 核 作为等价矩阵。其他卷积核按正常初始化。每一个conv 或者AVG层后面都跟一个BN层,这提供了训练时非线性化。没有这样的非线性化,性能提升将是非常小的(如table 4)。特别地,对于一个depthwise DBB,每个卷积应该有相同数量的组,我们在1x1-AVG路径中移除1x1路径和1x1 conv,因为1x1 depthwise conv就是一个线性放缩。

4.实验
4.1 在ImageNet上的实验结果

4.2 Ablation Studies
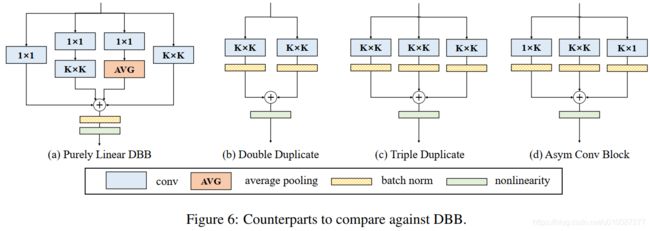
不同DBB结构如Figure6所示,实验结果如Table4所示。
reference
[1]. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks.
[2]. Repvgg: Making vgg-style convnets great again.