深度学习CV八股文
深度学习CV八股文
- 一、深度学习中解决过拟合方法
-
- L1和L2正则化
- Dropout
-
- Dropout正则化
- Inverted Dropout(反向随机失活)
- Dropout起到正则化效果的原因:
- Dropout的缺点
- eargstopping ( 早停法 )
- 二、深度学习中解决欠拟合方法
- 三、梯度消失和梯度爆炸
-
- 解决梯度消失的方法
- 解决梯度爆炸的方法
- 四、神经网络权重初始化方法
-
- Xavier
- 指数加权移动平均数
- 五、梯度下降法
-
- 梯度下降
- SGD(随机梯度下降法)
- Momentum(动量梯度下降)
- Nesterov Momentum
- 自适应学习率算法
-
- Adagrad
- RMSprop
- Adam
- NAdam
- 六、学习率衰减
- 七、BatchNorm
-
- BN的作用
- BN的缺点
- 测试时的BN
- 八、内部协变量偏移
- 九、归一化方法
-
- LayerNormalization
- Instance Normalization
- Group Nomalization
- 对比
- 十、卷积
-
- 卷积的优点
- 1x1Conv(点卷积)
- Depthwise Separable Convolution
- Mlpconv
- 十一、池化
- 十二、激活函数
-
- Sigmoid
- tanh
- ReLU
-
- ReLU的变体
- Swish
- 十三、预训练
-
- 预训练的好处
- 什么是预训练
- 十四、Transformer
-
- Attention
- self-attention
-
- self-attention缩放(归一化)的原因
- self-attention采用点乘而不是加线性注意力的原因:
- 作用
- Mutil_Head Attention
-
- Mutil_Head Attention的作用
- MLP
- 残差连接的目的:
- Patch Embedding
- Learnable Embedding
- Position Embedding
- 十五、损失函数
-
- 交叉熵函数
-
- 从KL散度到交叉熵
- MSE
- 十六、度量指标分析
-
- F1-score
- precision
- recall
- PR曲线
- ROC-AUC
-
- ROC
- AUC
- 训练模型时的F1-score和AUC的选择
- 十七、经典的模块组合方法
-
- Res和Dense
-
- Res
- Dense
- 如何选择Res和Concat
- 多尺度卷积
- Inverted Residual 和Linear Bottleneck
-
- Inverted Residual
- Linear Bottleneck
- Group Average Pooling +1x1 Conv与FC
- Squeeze-and-Excitation(SE)
一、深度学习中解决过拟合方法
- 数据增强
- L1和L2正则化
- Dropout正则化
- early stopping
- BatchNorm
L1和L2正则化
L1正则化直接在原来的损失函数基础上加上权重参数的绝对值: l o s s = J ( w , b ) + λ 2 m ∑ ∣ w ∣ loss=J(w,b)+\frac{\lambda}{2m}\sum|w| loss=J(w,b)+2mλ∑∣w∣
L2正则化直接在原来的损失函数基础上加上权重参数的平方和: l o s s = J ( w , b ) + λ 2 m ∑ ∥ w ∥ F 2 loss=J(w,b)+\frac{\lambda}{2m}\sum\lVert w\lVert _F^2 loss=J(w,b)+2mλ∑∥w∥F2
L1和L2正则化能够缓解过拟合的原因:
神经网络就是一个函数,对其进行傅里叶变换求得频谱,频谱中低频分量就是变化平滑的部分,高频分量就是变化敏感的部分。模型对于微小扰动的反馈差异大实际就是一个过拟合的表现,也就是高频分量不能多。根据雅各比矩阵(一阶导数矩阵),神经网络这个函数的高频分量存在上界,上界和谱范数正相关。谱范数逆变换回时域,可求得和参数范数正相关。正则就是将参数的范数加入loss里求最优化,故而限制了神经网络学到高频分量,更倾向于一个低频的平滑的函数,从而缓解过拟合。
推导过程:https://blog.csdn.net/StreamRock/article/details/83539937
Dropout
Dropout正则化
步骤:
- 遍历神经网络每一层节点,设置节点保留概率keep_prob(每一层的keep_prob可以不同,参数多的层keep_prob可以小一些,少的可以多一些)。
- 删除神经网络节点和从该节点进出的连线。
- 输入样本使用简化后的神经网络进行训练。
每次输入样本都要重复以上三步
Inverted Dropout(反向随机失活)
步骤:
- 产生⼀个[0,1)的随机矩阵,维度与权重矩阵相同。
- 设置节点保留概率keep_prob 并与随机矩阵比较,小于为1,大于为0。
- 将权重矩阵与0-1矩阵对应相乘得到新权重矩阵。
- 对新权重矩阵除于keep_prob(保证输⼊均值和输出均值一致),保证权重矩阵均值不变,层输出不变。
测试阶段不需要使用dropout,因为如果在测试阶段使用dropout会导致预测值随机变化 , 而且在训练阶段已经将权重参数除以 keep_prob 保证输出均值不变所以在刚试阶段没必要使用dropout
Dropout起到正则化效果的原因:
- Dropout可以使部分节点失活,起到简化神经网络结构的作用,从而起到正则化的作用。
- Dropout使神经网络节点随机失活,所以神经网络节点不依赖于任何输⼊,每个输入的权重都不会很⼤。Dropout最终产⽣收缩权重的平方范数的效果,压缩权重效果类似L2正则化。
Dropout的缺点
没有明确的损失函数。
eargstopping ( 早停法 )
训练时间和泛化误差的权衡。提早停⽌训练神经网络得到⼀个中等大小的W的F范数,与L2正则化类似。

在训练中计算模型在验证集上的表现,当模型在验证集上的误差开始增大时,停止训练。这样就可以避免继续训练导致的过拟合问题。
二、深度学习中解决欠拟合方法
增加神经网络层数或神经元个数
三、梯度消失和梯度爆炸
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)
梯度饱和:越来越趋近一条直线(平行X轴的直线),梯度的变化很小

设激活函数是线性或函数,忽略b。 g ( z ) = z g(z)=z g(z)=z
y ^ = W ( l ) W ( l − 1 ) ⋯ W ( 2 ) W ( 1 ) x \hat{y} = W^{(l)} W^{(l-1)} \cdots W^{(2)} W^{(1)} x y^=W(l)W(l−1)⋯W(2)W(1)x
当 W ( l ) > 1 W^{(l)}>1 W(l)>1时,如 W ( l ) = [ 1.5 0 0 1.5 ] W^{(l)}=\begin{bmatrix} 1.5 & 0 \\ 0 & 1.5 \\ \end{bmatrix} W(l)=[1.5001.5], y ^ = W ( l ) [ 1.5 0 0 1.5 ] ( l − 1 ) x = 1. 5 ( l ) x \hat{y}=W^{(l)}\begin{bmatrix} 1.5 & 0 \\ 0 & 1.5 \\ \end{bmatrix}^{(l-1)}x=1.5^{(l)}x y^=W(l)[1.5001.5](l−1)x=1.5(l)x。此时,激活函数值/梯度函数值呈指数级增长=>梯度爆炸
当 W ( l ) > 1 W^{(l)}>1 W(l)>1时,如 W ( l ) = [ 0.5 0 0 0.5 ] W^{(l)}=\begin{bmatrix} 0.5 & 0 \\ 0 & 0.5 \\ \end{bmatrix} W(l)=[0.5000.5], y ^ = W ( l ) [ 0.5 0 0 0.5 ] ( l − 1 ) x = 0. 5 ( l ) x \hat{y}=W^{(l)}\begin{bmatrix} 0.5 & 0 \\ 0 & 0.5 \\ \end{bmatrix}^{(l-1)}x=0.5^{(l)}x y^=W(l)[0.5000.5](l−1)x=0.5(l)x。此时,激活函数值/梯度函数值呈指数级递减=>梯度消失
∂ J ( θ ) ∂ θ i j = ∂ J ( θ ) ∂ z i l + 1 ⋅ ∂ z i l + 1 ∂ θ i j \frac{\partial{J(\theta)}}{\partial{\theta_ij} }=\frac{\partial{J(\theta)}}{\partial{z^{l+1}_i} } \cdot \frac{\partial{z^{l+1}_i}}{\partial{\theta_ij} } ∂θij∂J(θ)=∂zil+1∂J(θ)⋅∂θij∂zil+1
解决梯度消失的方法
- Relu及其变体
- LSTM/GRU
- 残差结构
- BatchNorm
- Xavier初始化(修正w的方差,避免w过小)
解决梯度爆炸的方法
- 梯度裁剪
- 正则化(将w加入Loss里,如果Loss小则w也要小,而梯度爆炸是w过大[绝对值]造成的)
- Xavier初始化(修正w的方差,避免w过大)
- BatchNorm
四、神经网络权重初始化方法
Xavier
X和Z的方差在各层相等,激活值在网络供传递过程中就不会放大或缩小。
解决梯度消失和梯度爆炸问题
z = ∑ i = 1 n w i x i z= \sum_{i=1}^n w_ix_i z=∑i=1nwixi
v a r ( w i x i ) = E [ w i ] 2 v a r ( x i ) + E [ x i ] 2 v a r ( w i ) + v a r ( w i ) v a r ( x i ) var(w_ix_i)=E[w_i]^2var(x_i)+E[x_i]^2var(w_i)+var(w_i)var(x_i) var(wixi)=E[wi]2var(xi)+E[xi]2var(wi)+var(wi)var(xi)
若 E [ w i ] = E [ x i ] = 0 E[w_i]=E[x_i]=0 E[wi]=E[xi]=0,则 v a r ( w i x i ) = v a r ( w i ) v a r ( x i ) var(w_ix_i)=var(w_i)var(x_i) var(wixi)=var(wi)var(xi), v a r ( z ) = ∑ i = 1 n v a r ( w i ) v a r ( x i ) var(z)=\sum_{i=1}^n var(w_i)var(x_i) var(z)=∑i=1nvar(wi)var(xi)
若 x i x_i xi和 w i w_i wi独立同分布, v a r ( z ) = n v a r ( w ) v a r ( x ) var(z) =n var(w) var(x) var(z)=nvar(w)var(x)。
若 v a r ( z ) = v a r ( x ) var(z) = var(x) var(z)=var(x),则 v a r ( w ) = 1 n var(w) =\frac{1}{n}\quad var(w)=n1
前向传播: v a r ( w ) = 1 n i n var(w) =\frac{1}{n_{in}} var(w)=nin1
反向传播: v a r ( w ) = 1 n o u t var(w) =\frac{1}{n_{out}} var(w)=nout1
v a r ( w ) = 2 n o u t + n i n var(w) =\frac{2}{n_{out}+n_{in}} var(w)=nout+nin2
指数加权移动平均数
计算局部的平均值,描述数值的变化趋势
V t = β V t − 1 + ( 1 − β ) θ t V_t= \beta{V_{t-1}}+(1-\beta)\theta{_t} Vt=βVt−1+(1−β)θt, V t V_t Vt近似代表 1 1 − β \frac{1}{1- \beta} 1−β1个 θ \theta θ的平均值
当 V 0 = 0 , V 1 = ( 1 − β ) θ 1 V_0=0, V_1=(1-\beta)\theta{_1} V0=0,V1=(1−β)θ1,当 β = 0.98 \beta=0.98 β=0.98时, v 1 = 0.02 θ 1 v_1=0.02\theta{_1} v1=0.02θ1,导致偏差较大,因此需要偏差修正。
偏差修正的目的:提高前期指数加权平均值的精度
使用 v t 1 − β t = β V t − 1 + ( 1 − β ) θ t 1 − β t \frac{v_t}{1- \beta{^t}}=\frac{ \beta{V_{t-1}}+(1-\beta)\theta{_t}}{1- \beta{^t}} 1−βtvt=1−βtβVt−1+(1−β)θt,当 t t t很大时, 1 − β t ≈ 1 1- \beta{^t}\approx1 1−βt≈1,偏差修正将失去作用。
五、梯度下降法
梯度下降
假设一个损失函数为 J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x ) − y ) 2 J(\theta)=\frac{1}{2}\sum_{i=1}^n(h_{\theta}(x)-y)^2 J(θ)=21∑i=1n(hθ(x)−y)2,其中 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n h_{\theta}(x)=\theta{_0}+\theta{_1}x_1+\theta{_2}x_2+\cdots+\theta{_n}x_n hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn,然后使它最小化
我们知道曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。这个 θ i \theta_i θi的更新过程可以描述为:
θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j:=\theta_j-\alpha\frac{\partial}{\partial{\theta_j}}J(\theta) θj:=θj−α∂θj∂J(θ)
∂ ∂ θ j J ( θ ) = ∂ ∂ θ j 1 2 ( h θ ( x ) − y ) 2 = 2 ⋅ 1 2 ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( h θ ( x ) − y ) \frac{\partial}{\partial{\theta_j}}J(\theta)=\frac{\partial}{\partial{\theta_j}}\frac{1}{2}(h_{\theta}(x)-y)^2=2\cdot\frac{1}{2}(h_{\theta}(x)-y)\cdot\frac{\partial}{\partial{\theta_j}}(h_{\theta}(x)-y) ∂θj∂J(θ)=∂θj∂21(hθ(x)−y)2=2⋅21(hθ(x)−y)⋅∂θj∂(hθ(x)−y)
= ( h θ ( x ) − y ) ⋅ ∂ ∂ θ j ( ∑ i = 0 n θ i x i − y ) = ( h θ ( x ) − y ) x j =(h_{\theta}(x)-y)\cdot\frac{\partial}{\partial{\theta_j}}(\sum_{i=0}^n\theta_ix_i-y)=(h_{\theta}(x)-y)x_j =(hθ(x)−y)⋅∂θj∂(∑i=0nθixi−y)=(hθ(x)−y)xj
[ α \alpha α为学习率]
缺点:每进行一次迭代都需要将所有的样本进行计算,当样本量十分大的时候,会非常消耗计算资源,收敛速度会很慢。
SGD(随机梯度下降法)
Mini-batch SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(划个重点:每次迭代使用一组样本(Mini-batch SGD);每次迭代使用一个样本(SGD))
为什么叫随机梯度下降算法呢?这里的随机是指每次迭代过程中,样本都要被随机打乱,这个也很容易理解,打乱是有效减小样本之间造成的参数更新抵消问题。
缺点:
- 学习率过大容易陷入局部最小值或鞍点处,在局部最小值附近徘徊,无法收敛。学习率足够小,理论上是可以达到局部最优值的(非凸函数不能保证达到全局最优),但学习率太小却使得学习过程过于缓慢,合适的学习率应该是能在保证收敛的前提下,能尽快收敛
- 对所有参数更新使用相同学习率。
Momentum(动量梯度下降)
在普通的随机梯度下降和批梯度下降当中,参数的更新是按照如下公式进行的:
W : = W − α d W W:=W-\alpha{dW} W:=W−αdW
b : = b − α d b b:=b-\alpha{db} b:=b−αdb
其中 α \alpha α是学习率, d W dW dW、 d b db db是cost function对 W W W和 b b b的偏导数。
Momentum的公式:
v d W = β v d W + ( 1 − β ) d W v_{dW}=\beta{v_{dW}}+(1-\beta)dW vdW=βvdW+(1−β)dW
v d b = β v d b + ( 1 − β ) d b v_{db}=\beta{v_{db}}+(1-\beta)db vdb=βvdb+(1−β)db
W : = W − α V d W W:=W-\alpha{V_{dW}} W:=W−αVdW
b : = b − α V d b b:=b-\alpha{V_{db}} b:=b−αVdb
优点:解决了SGD更新方向完全依赖于当前样本,更新不稳定的缺点,对梯度做了一个平滑,更新的时候在一定程度上保留了之前更新方向。
Nesterov Momentum
Momentum每下降一步都是由前面下降方向的一个累积和当前点的梯度方向组合而成。Nesterov认为既然Momentum一定会先走 β v d θ \beta{v_{d\theta}} βvdθ的量,那先走 β v d θ \beta{v_{d\theta}} βvdθ再计算梯度不更好吗?所以Nesterov Momentum会先前进一小步(超前点),然后计算这个超前点的梯度,这种方法被命名为Nesterov accelerated gradient 简称 NAG。
记 v t v_t vt为第 t t t次迭代梯度的累计
v 0 = 0 v_0=0 v0=0, v 1 = α ∇ θ J ( θ ) v_1=\alpha\nabla_\theta J(\theta) v1=α∇θJ(θ), v 2 = β v 1 − α ∇ θ J ( θ + β v 1 ) v_2=\beta v_1-\alpha\nabla_\theta J(\theta+\beta v_1) v2=βv1−α∇θJ(θ+βv1)
⋯ \cdots ⋯
v t = β v t − 1 − α ∇ θ J ( θ + β v t − 1 ) v_t=\beta v_{t-1}-\alpha\nabla_\theta J(\theta+\beta v_{t-1}) vt=βvt−1−α∇θJ(θ+βvt−1)
参数更新公式:
θ : = θ + v t \theta :=\theta+v_t θ:=θ+vt
公式里的 β v t − 1 \beta v_{t-1} βvt−1就是图中B到C的那一段向量, θ + β v t − 1 \theta+\beta v_{t-1} θ+βvt−1就是C点的坐标(参数), β \beta β代表衰减率, α \alpha α代表学习率。
Nestao Momentum的超前点梯度比当前点梯度大,那么有理由相信它会继续变大下去,那我就把预计要增大的部分提前加进来;如果相比当前点小,也是类似的情况利用目标函数二阶导数信息(一阶导是J对t,二阶导是J对t-1),可以加速收敛。
自适应学习率算法
优点:学习率自动调节,根据参数的重要性对不同参数进行不同程度的更新。
低频参数较大更新、高频参数较小更新
Adagrad、RMSprop、Adam
Adagrad
对梯度中各分量逐元素平方,然后累计梯度量,参数分析时对梯度归一化。在凸问题上效果好,非凸问题上效果差。
公式:
累计平方梯度: r = r + g ⨀ g r=r+g\bigodot g r=r+g⨀g, g g g为梯度, ⨀ \bigodot ⨀表示对应位置元素相乘
θ : = θ − α r + ϵ ⨀ g \theta:=\theta-\frac{\alpha}{\sqrt{r}+\epsilon}\bigodot g θ:=θ−r+ϵα⨀g, α \alpha α学习率,分母中的 ϵ \epsilon ϵ是为了防止除零
优点:减少学习率手动调节。
缺点:随着梯度累积量的增加,学习率最终会变得非常小。
RMSprop
先对梯度累积量做平滑,在更新参数时,对梯度做归一化。如果某个方向上的梯度累积量很大(梯度震荡),梯度归一化后就会变小,从而减小该方向上的梯度振幅。从而实现了纵轴上减慢学习,横轴上加速学习的目的。
解决了Adagrad学习率急剧下降和在非凸问题上效果差的现象。
累计平方梯度: r = ρ r + ( 1 − ρ ) g ⨀ g r=\rho r+(1-\rho)g\bigodot g r=ρr+(1−ρ)g⨀g, ρ \rho ρ为衰减速率
θ : = θ − α r + ϵ ⨀ g \theta:=\theta-\frac{\alpha}{\sqrt{r}+\epsilon}\bigodot g θ:=θ−r+ϵα⨀g
Momentum和RMSprop的共同点:
⽬的 :对梯度的摆动在纵轴上减慢学习,在横轴上加速学习,从而降低梯度下降法的摆动幅度。
Momentum和RMSprop是两种原理不同的优化算法
Adam
Adam=Momentum(一阶矩估计)+RMSprop(二阶矩估计)(Momentum和RMSprop不带偏差修正),本质将动量应用于缩放后的梯度。
梯度(目标函数对于参数的一阶导数是): g ( t ) = ∇ θ J ( θ t − 1 ) g(t)=\nabla_\theta J(\theta_{t-1}) g(t)=∇θJ(θt−1)
综合考虑之前时间步的梯度动量:
- 计算梯度的指数移动平均数(一阶矩估计): m t = β 1 m t − 1 + ( 1 − β 1 ) g ( t ) m_t=\beta_1m_{t-1}+(1-\beta_1)g(t) mt=β1mt−1+(1−β1)g(t), m 0 = 0 m_0=0 m0=0, β 1 \beta_1 β1指数衰减率
- 计算梯度平方的指数移动平均数(二阶矩估计): v t = β 2 v t − 1 + ( 1 − β 2 ) g ( t ) 2 v_t=\beta_2v_{t-1}+(1-\beta_2)g(t)^2 vt=β2vt−1+(1−β2)g(t)2, v 0 = 0 v_0=0 v0=0, β 2 \beta_2 β2指数衰减率
计算指数衰减值(偏差修正): m ^ t = m t 1 − β 1 t \hat{m}_t=\frac{m_t}{1- \beta{^t_1}} m^t=1−β1tmt, v ^ t = v t 1 − β 2 t \hat{v}_t=\frac{v_t}{1- \beta{^t_2}} v^t=1−β2tvt
更新公式: θ : = θ − α ⋅ m ^ t v ^ t + ϵ \theta :=\theta-\alpha\cdot\frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} θ:=θ−α⋅v^t+ϵm^t, t t t是参与指数运算的,指第 t t t轮,分子是动量,分母是梯度缩放。
NAdam
Adam=Nesterov Momentum+RMSprop
Adam更新公式的展开为:
θ : = θ − α ⋅ m ^ t v ^ t + ϵ \theta :=\theta-\alpha\cdot\frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} θ:=θ−α⋅v^t+ϵm^t
= θ − α v ^ t + ε ⋅ ( β 1 m t − 1 1 − β 1 t + ( 1 − β 1 ) g ( t ) 1 − β 1 t ) =\theta-\frac{\alpha}{\sqrt{\hat{v}_t}+\varepsilon}\cdot(\frac{\beta_1m_{t-1}}{1- \beta{^t_1}}+\frac{(1-\beta_1)g(t)}{1- \beta{^t_1}}) =θ−v^t+εα⋅(1−β1tβ1mt−1+1−β1t(1−β1)g(t))( t t t足够大时, 1 − β t = 1 − β t − 1 1-\beta^t=1-\beta^{t-1} 1−βt=1−βt−1)
= θ − α v ^ t + ε ⋅ ( β 1 m ^ t − 1 + ( 1 − β 1 ) g ( t ) 1 − β 1 t ) =\theta-\frac{\alpha}{\sqrt{\hat{v}_t}+\varepsilon}\cdot(\beta_1\hat{m}_{t-1}+\frac{(1-\beta_1)g(t)}{1- \beta{^t_1}}) =θ−v^t+εα⋅(β1m^t−1+1−β1t(1−β1)g(t))
Nadam用当前动量向量的偏置校正估计,替换上一时间的偏置校正估计 m ^ t − 1 \hat{m}_{t-1} m^t−1:
θ : = θ − α v ^ t + ε ⋅ ( β 1 m ^ t + ( 1 − β 1 ) g ( t ) 1 − β 1 t ) \theta :=\theta-\frac{\alpha}{\sqrt{\hat{v}_t}+\varepsilon}\cdot(\beta_1\hat{m}_t+\frac{(1-\beta_1)g(t)}{1- \beta{^t_1}}) θ:=θ−v^t+εα⋅(β1m^t+1−β1t(1−β1)g(t))
六、学习率衰减
mini-batch梯度下降:
α \alpha α固定,最小值附近大幅度徘徊
α \alpha α衰减,最小值附近小幅度徘徊
衰减方法:
α = α 0 1 + d e c a y r a t e ⋅ e p o c h n u m \alpha=\frac{\alpha_0}{1+decayrate\cdot epochnum} α=1+decayrate⋅epochnumα0
α = K ⋅ α 0 e p o c h n u m \alpha=\frac{K\cdot\alpha_0}{\sqrt{epochnum}} α=epochnumK⋅α0
七、BatchNorm
将每一个mini batch中的数据分布都归一化到N(0,1)
求当前batch的均值: u = 1 m ∑ i n Z i u=\frac{1}{m}\sum_i^nZ_i u=m1∑inZi
求当前batch的方差: σ 2 = 1 m ∑ i n ( Z i − u ) 2 \sigma^2=\frac{1}{m}\sum_i^n(Z_i-u)^2 σ2=m1∑in(Zi−u)2
Z N o r m ( i ) = Z i − u σ 2 + ϵ Z^{(i)}_{Norm}=\frac{Z_i-u}{\sqrt{\sigma^2+\epsilon}} ZNorm(i)=σ2+ϵZi−u
Z i ~ = γ Z N o r m ( i ) + β \tilde{Z_i}=\gamma Z^{(i)}_{Norm}+\beta Zi~=γZNorm(i)+β, γ \gamma γ为可训练参数,通过 γ \gamma γ和 β \beta β将每层输入的均值和方差缩为网络想要的值
当 γ = σ 2 + ϵ \gamma=\sqrt{\sigma^2+\epsilon} γ=σ2+ϵ, β = u \beta=u β=u时, Z i ~ = Z i \tilde{Z_i}=Z_i Zi~=Zi

BN的作用
- 加速SGD收敛(将batch里的数据分布变为一样),效果与特征归一化一致。
- 使分布更稳定。
- 防止过拟合。有轻微正则化效果,BN的均值和方差是在mini batch上计算得到的,含有轻微噪音。将噪音添加到隐藏单元上,这迫使后部单元不依赖于任何⼀个隐藏单元(将Batch中所有样本都被关联在了一起,网络不会从某一个训练样本中生成确定的结果),类似dropout。
- 解决梯度消失和梯度爆炸问题(使用BN后,网络的输出就不会很大,梯度就不会很小)。
- 提高激活函数准确度,增强优化器性能。
BN的缺点
高度依赖于batchsize的大小,实际使用中会对batchsize大小进行约束,不适合batchsize=1的情况。不适用于RNN,RNN的序列长度是不一致的。
测试时的BN
训练时,一个mini batch获得一个 u u u、 σ 2 \sigma^2 σ2,测试时使用指数加权平均估算 u u u、 σ 2 \sigma^2 σ2,平均数涵盖所有mini batch。

八、内部协变量偏移
- 训练数据和测试数据遵从不同分布。
- 深度神经网络中后⼀层数据和前⼀层数据遵从不同分布。
带来的问题:最优学习率一真在变 ⟹ \implies ⟹只能采取很小的步长 ⟹ \implies ⟹学习速率很慢
当数据在激活函数饱和区时,反向传播计算的梯度很小,参数更新很慢,学习速率很慢。

解决方法:归一化
x ^ = x − u σ 2 + ϵ \hat{x}=\frac{x-u}{\sqrt{\sigma^2+\epsilon}} x^=σ2+ϵx−u
减均值除方差的作用:
- 避免数据分布发生偏移,解决内部协变量偏移问题。
- 使数据远离激活函数的饱和区,解决梯度消失问题。
缺点:由于数据位于激活函数的非饱和区,而非饱和区具有非线性变换的能力,因此会降低网络性能。
归一化缺点的解决办法:缩放和移位

缩放和移位:
(其实就是BatchNorm)
x ~ = γ x ^ + β \tilde{x}=\gamma\hat{x}+\beta x~=γx^+β,当 γ = σ 2 ϵ \gamma=\sqrt{\sigma^2\epsilon} γ=σ2ϵ, β = u \beta=u β=u时, x ~ = x \tilde{x}=x x~=x
九、归一化方法

LayerNormalization
对单个样本所有维度特征做归一化。LN通过hidden size这个维度归一化来让分布稳定下来,计算每个样本所有通道的均值方差。LN通常运用在RNN中。
Instance Normalization
IN是针对于不同的batch, 不同的chennel进行归一化(计算单个C和N里的WH的均值和方差)。还是把图像的尺寸表示为[N, C, H, W]的话,IN则是针对于[H,W]进行归一化。这种方式通常会用在风格迁移的训练中。
Group Nomalization
把所有的channel都放到同一个group中的时候就变成了layer normal(计算单个N里位于group里所有C的WH的均值和方差)。
对比
与BN不同,LN/IN和GN都没有对batch作平均,所以当batch变化时,网络的错误率不会有明显变化。但论文的实验显示:LN和IN 在时间序列模型(RNN/LSTM)和生成模型(GAN)上有很好的效果,而GN在GAN上表现更好。
十、卷积
深度学习中将互相关称之为卷积
作用:提取视觉特征
缺点:1.输出缩小;2.图像边缘大部分信息丢失(因为边缘区域像素点在输出中采用较少,只采用一次,解决办法用padding)
各种核的尺寸为奇数的原因:
- 若是偶数,则填充为不对称填充。
- 若是奇数,则过滤器有⼀个中心点,便于指出过滤器的位置 。
卷积的优点
- 权值共享:每个过滤器对应的输出都可以在输⼊图片的不同区域中使用相同参数卷积得到。
- 局部连接: 每⼀个输出仅依赖于⼀小部分输⼊。
1x1Conv(点卷积)
- 1x1的卷积能够灵活的调控特征的深度(升维和降维)。
- 减少参数量和计算量(先用少量普通卷积核再升维,或先降维再普通卷积等可以减少参数量以及计算量)。
- 实现了跨通道的信息组合,并增加了非线性特征(实现降维和升维的操作其实就是channel间信息的线性组合变化)。
Depthwise Separable Convolution
步骤:
- 对数据进行通道分离。
- 对每个数据分别进行卷积核数为1的卷积(DW,Conv参数不共享)。
- 将映射堆叠在一起。
- 使用点卷积升维(PW)。
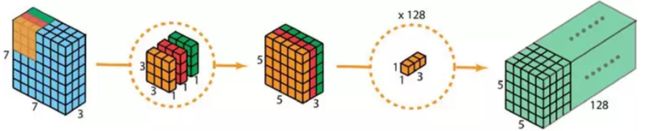
优点:减少了大量参数,大幅度降低了计算成本,提高了模型的推理速度。(Depthwise Seperable Conv的计算成本为: D K ⋅ D K ⋅ M ⋅ D F ⋅ D F + N ⋅ M ⋅ D F ⋅ D F = ( D K ⋅ D K + N ) ⋅ M ⋅ D F ⋅ D F D_K\cdot D_K\cdot M\cdot D_F\cdot D_F+N\cdot M\cdot D_F\cdot D_F=(D_K\cdot D_K+N)\cdot M\cdot D_F\cdot D_F DK⋅DK⋅M⋅DF⋅DF+N⋅M⋅DF⋅DF=(DK⋅DK+N)⋅M⋅DF⋅DF,标准Conv的计算成本为: D K ⋅ D K ⋅ M ⋅ N ⋅ D F ⋅ D F D_K\cdot D_K\cdot M\cdot N \cdot D_F\cdot D_F DK⋅DK⋅M⋅N⋅DF⋅DF;其中, M M M代表输入通道数, N N N代表输出通道数, D K D_K DK代表卷积核尺寸, D F D_F DF代表输出特征图的尺寸。DW的计算量为普通Conv的 N − 1 N \frac{N-1}{N} NN−1。
Mlpconv

NIN(Network in Network)提出了Mlpconv和使用全局平均池化特换全连接层。传统的CNN最后的全连接参数很多,容易过拟合。
局部感受野窗口的运算,可以理解为一个单层的网络。MLPconv层是每个卷积的局部感受野中还包含了一个微型的多层网络,即先进行普通的卷积,然后进行1x1的卷积。
作用:
- 更好的在其它层之前对特征进行空间组合。1x1卷积核用非常少的参数,并在这些特征的所有像素上共享。
- 将特征组合成更复杂的组来增加单个卷积特征的有效性。
- Mlpconv采用多层网络结构(一般3层)提高非线性,对每个局部感受野进行更加复杂的运算。
十一、池化
作用:
对卷积层输出的特征图进行特征选择和信息的过滤。能够实现对特征图的下采样,从而减少下一层的参数和计算量。并且具有防止过拟合,以及保持特征的不变性(平移、旋转、尺度)的作用。缺点是不存在要学习的参数。
average pooling(不常用)、max pooling求的是每一个维度的窗口内的平均/最大值,global average pooling求的是每一个维度的平均值。
Max Padding的作用:如果在卷积核中提取到某个特征,则其中的最大值很⼤; 如果没有,则其 中的最⼤值很小。
使用Conv替换Pool的优点:Conv的参数是可学习的,可以达到保留更多数据信息和防止过滤掉有用信息的作用。
十二、激活函数
作用:加入非线性因素的,提高线性模型的表达能力(没有激活函数的模型无论多少层都是线性模型,而大部分数据都是线性不可分的)。
比较常用的激活函数为:Sigmoid、ReLU(及其变体)、tanh
高级的有:Swish(及其变体)、Maxout等
这里主要介绍:Sigmoid、ReLU、tanh和Swish
其它激活函数可到此链接了解
Sigmoid
公式: f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1

求导: f ′ ( x ) = − ( e − x ) ′ ( 1 + e − x ) 2 = e − x ( 1 + e − x ) 2 = e − x + 1 − 1 ( 1 + e − x ) 2 = f ( x ) − f 2 ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x)=\frac{-(e^{-x})'}{(1+e^{-x})^2}=\frac{e^{-x}}{(1+e^{-x})^2}=\frac{e^{-x}+1-1}{(1+e^{-x})^2}=f(x)-f^2(x)=f(x)(1-f(x)) f′(x)=(1+e−x)2−(e−x)′=(1+e−x)2e−x=(1+e−x)2e−x+1−1=f(x)−f2(x)=f(x)(1−f(x))
特点:
- 便于求导的平滑函数。
- 能压缩数据,保证数据幅度不会有问题。
缺点:
- 容易导致梯度消失(由于存在上下界,导致w<1时梯度会越缩越小,从而梯度消失,导数最大为0.25,小于1)。
- 输出不是0均值(即zero-centered)。输出的都大于0导致下一层w的局部梯度都为正,在反向传播时导致要么都往正,要么都往负更新;
- 幂运算相对耗时。
二分类模型中Sigmoid一般是在模型最后一层将特征映射到0-1之间,多分类模型性最后使用的是Softmax。
Softmax: f ( x i ) = e x i ∑ j N e x j f(x_i)=\frac{e^{x_i}}{\sum_j^Ne^{x_j}} f(xi)=∑jNexjexi
求导: f ′ ( x i ) = e x i ∑ − e x i e x i ∑ 2 = e x i ( ∑ − e x i ) ∑ 2 = e x i ∑ ⋅ ∑ − e x i ∑ = f ( x i ) ( 1 − f ( x i ) ) f'(x_i)=\frac{e^{x_i}\sum-e^{x_i}e^{x_i}}{\sum^2}=\frac{e^{x_i}(\sum-e^{x_i})}{\sum^2}=\frac{e^{x_i}}{\sum}\cdot\frac{\sum-e^{x_i}}{\sum}=f(x_i)(1-f(x_i)) f′(xi)=∑2exi∑−exiexi=∑2exi(∑−exi)=∑exi⋅∑∑−exi=f(xi)(1−f(xi))
tanh
公式: f ( x ) = e x − e − x e x + e − x f(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} f(x)=ex+e−xex−e−x

求导: f ′ ( x ) = ( e x − e − x ) ′ ⋅ ( e x + e − x ) − ( e x − e − x ) ⋅ ( e x + e − x ) ′ ( e x + e − x ) 2 = ( e x + e − x ) 2 − ( e x − e − x ) 2 ( e x + e − x ) 2 = 1 − ( e x − e − x ) 2 ( e x + e − x ) 2 = 1 − f 2 ( x ) f'(x)=\frac{(e^x-e^{-x})'\cdot(e^x+e^{-x})-(e^x-e^{-x})\cdot(e^x+e^{-x})'}{(e^x+e^{-x})^2}=\frac{(e^x+e^{-x})^2-(e^x-e^{-x})^2}{(e^x+e^{-x})^2}=1-\frac{(e^x-e^{-x})^2}{(e^x+e^{-x})^2}=1-f^2(x) f′(x)=(ex+e−x)2(ex−e−x)′⋅(ex+e−x)−(ex−e−x)⋅(ex+e−x)′=(ex+e−x)2(ex+e−x)2−(ex−e−x)2=1−(ex+e−x)2(ex−e−x)2=1−f2(x)
特点:解决了Sigmoid函数的不是zero-centered输出问题,但梯度消失的问题和幂运算的问题仍然存在。
ReLU
公式: f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)

导数: f ′ ( x ) = { 1 , x > 0 0 , x ≤ 0 f'(x)= \begin{cases} 1 ,x>0\\ 0,x\leq0\end{cases} f′(x)={1,x>00,x≤0
优点:
- SGD算法的收敛速度比 sigmoid 和 tanh快(梯度不会饱和,即 x > 0 , f ′ ( x ) = 1 x>0,f'(x)=1 x>0,f′(x)=1,克服了梯度消失问题,所以训练才会快)。
- 解决了梯度消失问题(梯度不会饱和)。
- 缓解过拟合问题(使用Relu会使部分神经元为0,这样就造成了网络的稀疏性,并且减少了参数之间的相互依赖关系,缓解了过拟合问题的发生)。
- 计算复杂度低,不需要进行指数运算。
- 适合反向传播时(sigmoid和tanh在饱和区两边导数容易为0,即容易出现梯度消失的情况,从而无法完成深层网络的训练)。
缺点:
- 输出不是zero-centered。
- Dead ReLU Problem( x ≤ 0 = 0 x\leq0=0 x≤0=0导致神经元坏死,解决方法:Xavier初始化,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法)。
- 不会对数据做幅度压缩,数据的幅度会随着模型层数的增加不断扩张。
ReLU的变体
ReLU的变体有:LeakReLU、RReLU、PReLU、ELU、GeLU、SeLU、CeLU、SILU、GLU
它们主要是为了克服ReLU的Dead ReLU Problem,有些还解决了zero-centered,但计算效率不如ReLU,而且部分实际效果不一定比ReLU好
Swish
公式: f ( x ) = x ⋅ s i g m o i d ( β x ) f(x)=x\cdot sigmoid(\beta x) f(x)=x⋅sigmoid(βx)

导数: f ′ ( β x ) = s i g m o i d ( β x ) + x ⋅ s i g m o i d ′ ( β x ) = s i g m o i d ( β x ) + β x ⋅ s i g m o i d ( β x ) ( 1 − s i g m o i d ( β x ) ) = s i g m o i d ( β x ) ( 1 + β x − β x s i g m o i d ( β x ) ) f'(\beta x)=sigmoid(\beta x)+x\cdot sigmoid'(\beta x)=sigmoid(\beta x)+\beta x\cdot sigmoid(\beta x)(1-sigmoid(\beta x))=sigmoid(\beta x)(1+\beta x-\beta xsigmoid(\beta x)) f′(βx)=sigmoid(βx)+x⋅sigmoid′(βx)=sigmoid(βx)+βx⋅sigmoid(βx)(1−sigmoid(βx))=sigmoid(βx)(1+βx−βxsigmoid(βx))

特点:
- 具备无上界有下界、平滑、非单调的特性。
- β = 0.1 \beta=0.1 β=0.1时导数是无上下界的; β = 1 / 10 \beta=1/10 β=1/10时导数存在上下界;并且上界 > 1 >1 >1,下界 < 0 <0 <0,还有相较于ReLU,Swish在0处可导。
- x x x过大或过小时导数值才会不变,并且只有过小时导数与激活函数值才为0。
(论文里用实验证明Swish 在深层模型上的效果优于 ReLU)
缺点:计算量大。
十三、预训练
Frozen:冷冻,冰冻。
Fine-Tuning:微调,更好的对参数进行调整使得更适应当前任务。
预训练的好处
- 训练数据较少时, 难以训练复杂网络。
- 加快训练任务的收敛速度。
- 初始化效果好,有利于优化 。
什么是预训练
在CV里,网络底层参数使用其它任务学习好的参数,高层参数仍然随机初始化。之后,用该任务的训练数据训练网络,底层参数微调。
十四、Transformer
ViT主要有Encoding和MLP组成,Encoding由Mutil_Head Attention、MLP(feed forward)和残差结构组成。
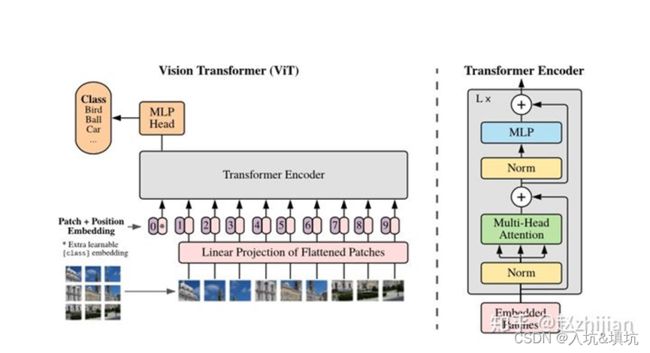
Attention
self-attention
计算self-attention的步骤:
- query 和 key 进行相似度计算,得到权值
- 将权值进行归一化,得到直接可用的权重
- 将权重和 value 进行加权求和
self-attention公式: a t t e n t i o n ( K , Q , V ) = s o f t m a x ( K T Q d k ) V attention(K,Q,V)=softmax(\frac{K^TQ}{\sqrt{d_k}})V attention(K,Q,V)=softmax(dkKTQ)V, d k d_k dk:patch的大小
Q Q Q、 K K K、 V V V的最早思想来源于Memory Networks。Memory Networks最重要的就是提出了query - key - value思想,当时的该模型聚焦的任务主要是question answering,先用输入的问题query检索key-value memories,找到和问题相似的memory的key,计算相关性分数,然后对value embedding进行加权求和,得到一个输出向量。这后面就衍生出了self-attention里的Q,K,V表示,在self-attention里的把X映射到QKV。
self-attention缩放(归一化)的原因
- 首先 d k d_k dk比较大时, 向量内积容易取很大的值: K T Q = ∑ i = 0 d k K i Q i K^TQ=\sum^{dk}_{i=0}K_iQ_i KTQ=∑i=0dkKiQi
- 向量内积大时,softmax函数梯度很小。softmax对 x i x_i xi的梯度为: f ( x i ) ( 1 − f ( x i ) ) f(x_i)(1-f(x_i)) f(xi)(1−f(xi))[看sigmoid],内积( x i x_i xi)很大时, f ( x i ) → 1 f(x_i)\to1 f(xi)→1,则 f ( x i ) ( 1 − f ( x i ) ) → 0 f(x_i)(1-f(x_i))\to0 f(xi)(1−f(xi))→0
self-attention采用点乘而不是加线性注意力的原因:
点乘注意力可以用高度优化的矩阵乘法来实现,因而速度更快、空间效率更高。
作用
根据每个预测像素在图像中与其他像素之间的相似性来增强或减弱每个预测像素的值(全局关联),在训练和预测时使用相似的像素,忽略不相似的像素。
为解决CNN中的 convolution单元每次只关注邻域 kernel size 的区域,忽略了全局其他片区(比如很远的像素)对当前区域的贡献。(就算后期感受野越来越大,终究还是局部区域的运算)
Mutil_Head Attention
Mutil_Head Attention公式:
M u t i l H e a d = c o n c a t ( h e a d 1 , h e a d 2 , ⋯ , h e a d n ) W 0 MutilHead=concat(head_1,head_2,\cdots,head_n)W^0 MutilHead=concat(head1,head2,⋯,headn)W0
h e a d i = a t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i=attention(QW_i^Q,KW_i^K,VW_i^V) headi=attention(QWiQ,KWiK,VWiV)
W i Q W_i^Q WiQ、 W i K W_i^K WiK、 W i V W_i^V WiV:不同的权重矩阵能够将不同的输入映射的不同的空间,避免 X X X参数太少,影响模型容量
Mutil_Head Attention的作用
类比CNN的多个卷积核,不同卷积核提取不同方面的特征,不同head关注不同表示子空间,综合利用各方面的信息获得更丰富的特征。
在机器翻译中,它考虑了不同语义场景下目标字与其它字之间的关系不同,使计算机能看懂歧义句。
MLP
在NLP里,Transformer具有feed forward,而CV里将这部分变成MLP。其本质上feed forward就是MLP。
作用:添加非线性,增强模型表达能⼒
残差连接的目的:
使网络更容易训练,因为修改输入比重构输出容易多了。
Patch Embedding
将原始的2-D图像转换成一系列1-D的patch embeddings,然后通过一个简单的线性变换将patchs映射到D大小的维度。
Learnable Embedding
可学习的vector,这个token沒有语义信息(即在句子中与任何的词无关,在图像中与任何的patch无关),它与图片label有关,经过encoder得到的结果使得整体表示偏向与这个指定embedding的信息
Position Embedding
告诉模型,哪个 patch 是在前面的,哪个 patch 是在后面。
transformer和CNN不同,需要position embedding来编码tokens的位置信息,这主要是因为self-attention是permutation-invariant(置换不变性,特征之间没有空间位置关系),即打乱sequence里的tokens的顺序并不会改变结果。如果不给模型提供patch的位置信息,那么模型就需要通过patchs的语义来学习拼图,这就额外增加了学习成本。
ViT论文中对比了几种不同的position embedding方案(如下),最后发现如果不提供positional embedding效果会差,但其它各种类型的positional embedding效果都接近,这主要是因为ViT的输入是相对较大的patchs而不是pixels,所以学习位置信息相对容易很多。
- 无positional embedding
- 1-D positional embedding:把2-D的patchs看成1-D序列
- 2-D positional embedding:考虑patchs的2-D位置(x, y)
- Relative positional embeddings:patchs的相对位置
十五、损失函数
交叉熵函数
交叉熵是凸优化问题。
二分类: L o s s = − 1 m ∑ i = 1 m [ y i l o g y ^ i + ( 1 − y i ) l o g ( 1 − y ^ i ) ] Loss=-\frac{1}{m}\sum_{i=1}^m[y_ilog\hat{y}_i+(1-y_i)log(1-\hat{y}_i)] Loss=−m1∑i=1m[yilogy^i+(1−yi)log(1−y^i)], m m m是样本量
多分类: L o s s = − 1 m ∑ i = 1 m ∑ j = 1 C y i j l o g ( p i j ) Loss=-\frac{1}{m}\sum_{i=1}^m\sum_{j=1}^Cy_{ij}log(p_{ij}) Loss=−m1∑i=1m∑j=1Cyijlog(pij), y i c y_{ic} yic符号函数(0/1),如果样本 i i i的真实类别等于 j j j取1,否则取0。

-
在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:一、学习率;二、偏导值。其中,学习率是我们需要设置的超参数,所以我们重点关注偏导值。从上面的式子中,我们发现,偏导值的大小取决于x 和 sigmod值与y的差 ,我们重点关注后者,后者的大小值反映了我们模型的错误程度,该值越大,说明模型效果越差,但是该值越大同时也会使得偏导值越大,从而模型学习速度更快。所以,使用逻辑函数得到概率,并结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
-
采用了类间竞争机制,比较擅长于学习类间的信息,但是只关心对于正确标签预测概率的准确性,而忽略了其他非正确标签的差异(如果样本 i i i的真实类别不等于 j j j,则 y i j l o g ( p i j ) = 0 y_{ij}log(p_{ij})=0 yijlog(pij)=0),从而导致学习到的特征比较散。
二进制交叉熵(多标签分类): L o s s = 1 N ∑ − ∑ i = 1 C [ y i l o g y ^ i + ( 1 − y i ) l o g ( 1 − y ^ i ) ] C Loss=\frac{1}{N}\sum\frac{-\sum_{i=1}^C[y_ilog\hat{y}_i+(1-y_i)log(1-\hat{y}_i)]}{C} Loss=N1∑C−∑i=1C[yilogy^i+(1−yi)log(1−y^i)], C C C是类数
区别:二进制交叉熵计算每个数据的所有类别的误差,然后区平均;而多分类的交叉熵只计算groudtruth对应索引处的概率的误差。
从KL散度到交叉熵
信息量,熵的公式: I ( x 0 ) = − p ( x 0 ) l o g ( p ( x 0 ) ) I(x_0)=-p(x_0)log(p(x_0)) I(x0)=−p(x0)log(p(x0))( x 0 x_0 x0发生的概率为 p ( x 0 ) p(x_0) p(x0))
对所有可能发生的事件产生的信息量的期望: H ( x ) = − ∑ i = 1 n p ( x i ) l o g ( p ( x i ) ) H(x)=-\sum_{i=1}^np(x_i)log(p(x_i)) H(x)=−∑i=1np(xi)log(p(xi))
相对熵(KL散度),用于度量预测和真实的差异: D K L ( p ∣ ∣ q ) ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) q ( x i ) ) D_{KL}(p||q))=\sum_{i=1}^np(x_i)log(\frac{p(x_i)}{q(x_i)}) DKL(p∣∣q))=∑i=1np(xi)log(q(xi)p(xi)), p ( x i ) p(x_i) p(xi)为真实概率, q ( x i ) q(x_i) q(xi)为预测概率
D K L ( p ∣ ∣ q ) ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) q ( x i ) ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) ) − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) = − H ( x ) − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) D_{KL}(p||q))=\sum_{i=1}^np(x_i)log(\frac{p(x_i)}{q(x_i)})=\sum_{i=1}^np(x_i)log(p(x_i))-\sum_{i=1}^np(x_i)log(q(x_i))=-H(x)-\sum_{i=1}^np(x_i)log(q(x_i)) DKL(p∣∣q))=∑i=1np(xi)log(q(xi)p(xi))=∑i=1np(xi)log(p(xi))−∑i=1np(xi)log(q(xi))=−H(x)−∑i=1np(xi)log(q(xi))
由于 H ( x ) H(x) H(x)为一个常数,所以只要计算 − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) -\sum_{i=1}^np(x_i)log(q(x_i)) −∑i=1np(xi)log(q(xi))
MSE
非凸优化问题
L o s s = 1 N ∑ i = 1 N ( p i − y i ) 2 Loss=\frac{1}{N}\sum_{i=1}^N(p_i-y_i)^2 Loss=N1∑i=1N(pi−yi)2
R M S E = M S E RMSE=\sqrt{MSE} RMSE=MSE
∂ L i ∂ w i = ∂ L i ∂ p i ⋅ ∂ p i ∂ s i ⋅ ∂ s i ∂ w i = 2 ( p i − y i ) ⋅ σ ( s i ) [ 1 − σ ( s i ) ] ⋅ x i = 2 ( σ ( s i ) − y i ) σ ( s i ) [ 1 − σ ( s i ) ] x i \frac{\partial{L_i}}{\partial{w_i}}=\frac{\partial{L_i}}{\partial{p_i}}\cdot\frac{\partial{p_i}}{\partial{s_i}}\cdot\frac{\partial{s_i}}{\partial{w_i}}=2(p_i-y_i)\cdot\sigma(s_i)[1-\sigma(s_i)]\cdot x_i=2(\sigma(s_i)-y_i)\sigma(s_i)[1-\sigma(s_i)]x_i ∂wi∂Li=∂pi∂Li⋅∂si∂pi⋅∂wi∂si=2(pi−yi)⋅σ(si)[1−σ(si)]⋅xi=2(σ(si)−yi)σ(si)[1−σ(si)]xi
使用MSE的一个缺点就是其偏导值在输出概率值接近0或者接近1的时候非常小,这可能会造成模型刚开始训练的时,偏导值近乎消失,导致一开始学习速率非常慢,交叉熵则不会。(RMSE同理)
十六、度量指标分析
FP:False Positive 阴性被预测为阳性
TP: True Positive 阳性被预测为阳性
FN: False Negative 阳性被预测为阴性
TN: True Negative 阴性被预测为阴性
F1-score
衡量模型对每个类别的预测精度和召回率是否平衡,能够直观地显示模型对测试集中每个类别的泛化效果。F1值越大,学习器的性能较好。
precision
衡量模型对测试集中每个类别的预测准确性,能够直观地显示模型对测试集中每个类别的归纳效果。
recall
衡量模型对测试集中每个类别的相关数据的识别准确程度,能够直观地显示模型对测试集中每个类别的相关数据的识别效果。
p r e c i s i o n = T P T P + F P precision=\frac{TP}{TP+FP} precision=TP+FPTP
r e c a l l = T P T P + F N recall=\frac{TP}{TP+FN} recall=TP+FNTP
F 1 − s c o r e = 2 ∗ r e c a l l ∗ p r e c i s i o n p r e c i s i o n + r e c a l l F1-score=\frac{2*recall*precision}{precision+recall} F1−score=precision+recall2∗recall∗precision
PR曲线
(recall,precison)
一个阈值对应PR曲线上的一个点。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例,从而计算相应的精准率和召回率。(选取不同的阈值,就得到很多点,连起来就是PR曲线)

ROC-AUC
ROC底下的面积,作为数值可以直观的评价分类器的好坏,值越大越好。
ROC
模型在所有样本的(阳性/阴性)真实值和预测值计算出一个 (X=TPR, Y=1-FPR) 座标点
T P R = R e c a l l TPR=Recall TPR=Recall(灵敏度)
F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP(特异度)
ROC曲线为不同阈值下ROC坐标点组成的曲线

AUC
A U C = ∑ p r e d p o s > p r e d n e g P ∗ N AUC=\frac{\sum pred_{pos}>pred_{neg}}{P*N} AUC=P∗N∑predpos>predneg, P P P为positive的数量, N N N为Negtive的数量,AUC为所有positive和Negtive两两组合下, 模型对positive的预测结果大于对Negtive的预测结果的总和占比。(分别随机从样本集中抽取一个正负样本,正样本的预测值大于负样本的概率)
AUC局限性:AUC作为排序的评价指标本身具有一定的局限性,它衡量的是整体样本间的排序能力,对于计算广告领域来说,它衡量的是不同用户对不同广告之间的排序能力,而线上环境往往需要关注同一个用户的不同广告之间的排序能力。
训练模型时的F1-score和AUC的选择
F1-score的优化目标是recall和precision;
AUC为ROC曲线的的面,ROC的x,y为1-FPR,TPR,则AUC的优化目标是1-FPR,TPR;
由于TPR=recall,F1-score和AUC优化目标的差异是precision和1-FPR。
p r e c i s i o n = T P T P + F P precision=\frac{TP}{TP+FP} precision=TP+FPTP
1 − F P R = T N F P + T N 1-FPR=\frac{TN}{FP+TN} 1−FPR=FP+TNTN
AUC令1-FPR高,则要么TN高,要么FP小。当TN高的时候可能引起FN变大,此时TP可能会变小。
F1-score令precision高,则要么TP高,要么FP小。当TP高的时候可能引起FP变大,此时TN可能会变小。
当TP需要耗费的成本高时,度量指标选AUC;
当TN需要耗费的成本高时,度量指标选F1-score;
十七、经典的模块组合方法
Res和Dense
Res
Res: H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x, F ( x ) F(x) F(x)为残差函数, x x x为identity(恒等函数)
优点:简化了学习过程,增强了梯度传播,缓解网络退化的问题(深层网络比浅层网络更差)。当 F ( x ) = 0 F(x)=0 F(x)=0时, H ( x ) = x H(x)=x H(x)=x。于是,ResNet 相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值 H ( X ) H(X) H(X)和 x x x的差值,也就是所谓的残差 F ( x ) : = H ( x ) − x F(x) := H(x)-x F(x):=H(x)−x,因此,后面的训练目标就是要将残差结果逼近于 0,使到随着网络加深,准确率不下降。
res如何缓解梯度消失:
X i + 1 = X i + F ( X i , W i ) X_{i+1}=X_i+F(X_i,W_i) Xi+1=Xi+F(Xi,Wi)
X i + 2 = X i + 1 + F ( X i + 1 , W i + 1 ) = X i + F ( X i , W i ) + F ( X i + 1 , W i + 1 ) X_{i+2}=X_{i+1}+F(X_{i+1},W_{i+1})=X_i+F(X_i,W_i)+F(X_{i+1},W_{i+1}) Xi+2=Xi+1+F(Xi+1,Wi+1)=Xi+F(Xi,Wi)+F(Xi+1,Wi+1)
⋯ \cdots ⋯
X I = X i + ∑ n = i I − 1 F ( X n , W n ) X_{I}=X_i+\sum^{I-1}_{n=i}F(X_n,W_n) XI=Xi+∑n=iI−1F(Xn,Wn)
更新梯度时:
∂ L o s s ∂ x i = ∂ L o s s ∂ x I ⋅ ∂ x I ∂ x i = ∂ L o s s ∂ x I ⋅ ∂ ( x i + ∑ n = i I − 1 F ( X n , W n ) ) ∂ x i = ∂ L o s s ∂ x I ⋅ ( 1 + ∂ ∑ n = i I − 1 F ( X n , W n ) ∂ x i ) \frac{\partial{Loss}}{\partial{x_i}}=\frac{\partial{Loss}}{\partial{x_I}}\cdot \frac{\partial{x_I}}{\partial{x_i}}=\frac{\partial{Loss}}{\partial{x_I}}\cdot \frac{\partial{(x_i+\sum^{I-1}_{n=i}F(X_n,W_n))}}{\partial{x_i}}=\frac{\partial{Loss}}{\partial{x_I}}\cdot(1+\frac{\partial\sum^{I-1}_{n=i}F(X_n,W_n)}{\partial{x_i}}) ∂xi∂Loss=∂xI∂Loss⋅∂xi∂xI=∂xI∂Loss⋅∂xi∂(xi+∑n=iI−1F(Xn,Wn))=∂xI∂Loss⋅(1+∂xi∂∑n=iI−1F(Xn,Wn))
从结果可以看出,因为有“1”的存在,高层的梯度可以直接传递到低层,有效防止了梯度消失的情况。并且对比2中推出的公式可以发现,残差网络在更新梯度时把一些乘法转变为了加法,同时也提高了计算效率。
缺点:
- 通过“skip connection (identity)”结构一定程度上在促进了数据在层间的流通,但接近输出的网络层还是没有充分获得网络前面的特征图。当 F ( x ) ! = 0 F(x)!=0 F(x)!=0时, H ( x ) ! = x H(x)!=x H(x)!=x,并且每一层经过BN后又会归一化(数据会缩小),导致数据越传越小,越接近输出层获得的越前面的层的特征越小(即,可能获得白噪声)。
- 可能存在冗余。当相邻的 F ( x , w ) = 0 F(x,w)=0 F(x,w)=0时,则 X i = X i − 1 = ⋯ = X k X_i=X_{i-1}=\cdots=X_k Xi=Xi−1=⋯=Xk,此时多个特征相同并且能够从其它层推理出来,造成了冗余特征的问题。
Dense
Dense:拼接(Concat)前面所有层的特征作为当前层的输入,公式: X l = H ( [ X 0 , X 1 , ⋯ X l − 1 ] ) X_l=H([X_0,X_1,\cdots X_{l-1}]) Xl=H([X0,X1,⋯Xl−1])
作用:
- 加强了特征的传播、鼓励特征重用。
- 缓解了深层网络的梯度消失问题。每一层都能直接访问loss,从而实现隐式监督,缓解了梯度消失的问题。
- 解决了恒等函数和残差函数的输出通过求和进行组合可能会阻碍网络中的信息流的问题(Res的缺点1)。
缺点:消耗大量内存,降低了模型的推理速度。每次进行Concat的时候都需要重新开辟一个空间存储。解决方法是专门开辟一个空间,然后每次在那块空间里进行Concat。
如何选择Res和Concat
Add(yolov3 FPN采用Add)是将信息叠加,使每一个特征下的信息量增多了,计算量少。
Concat是将信息融合了,每一个特征下的信息没有增加。
当特征比较相似时使用add能够获得更明显的特征信息,特征差异比较大的时候使用Concat和获得更多具有不同信息的特征。
多尺度卷积
使用多尺度的卷积核进行卷积,然后对卷积后的特征图进行拼接,让每一个通道具有不同的感受野。
作用:在计算量不变的情况下,提高网络的宽度(每层的通道数)和深度。
Inverted Residual 和Linear Bottleneck
Inverted Residual
Inverted Residual采用先升维后降维的方法(传统Res为了降低参数量和计算量,采用先降维后升维的方法)。
作用:DW+PW的卷积减少了参数量,但会损失特征,而通道越多保留的特征越多,所以要做先升维。
Linear Bottleneck
ReLU的两个特点:
- 当ReLU的输入为非零的特征时,输入和输出之间其实对应的是一个线性映射关系。
- ReLU能够保持输入信息的完整性,但仅限于输入特征位于输入空间的低维子空间中(层卷积的输入特征维度 ≤ \leq ≤模块的输入特征维度)。
Linear ≈ \approx ≈特点1,又降维时的输入特征维度(升维后的维度)大于模块输入的特征维度,所以降维采用Linear作为激活函数。[Inverted Residual中的输入为X,其中升维的点卷积的输入为X,即升维的输入特征的维度和X的维度一样,所以选择ReLU;而DW的时候通道分离再卷积,每个卷积的输入特征的维度为1,都是小于X的维度,所以也选择ReLU]
Group Average Pooling +1x1 Conv与FC
FC的作用:将最后的输出映射到线性可分的空间。FC之前的卷积层作用本质是提取特征,而FC的作用是分类。FC在实际的运用中往往是两层,是因为只有一层FC,有些情况下解决不了非线性问题,如果两层,效果就好多了。如泰勒展开拟合光滑曲线一样。
但,进行FC的时候需要先将feature map进行reshape,会破坏feature map的空间结构。
Group Average Pooling(GAP)+1x1 Conv替换FC的优点:
- GAP使特征通道响应特征的全局分布、获得全局的感受野,以及使输出的维度与输入的特征通道数相匹配,从而在特征图与最终的分类间转换更加简单自然。
- GAP+1x1 Conv不像FC层需要大量训练调优的参数,降低了空间参数会使模型更加健壮,抗过拟合效果更佳。
- 测试的时候可以输入不同尺寸的数据。
Squeeze-and-Excitation(SE)
Squeeze:使用GAP压缩特征。
Excitation:显式建模特征通道间的相关性(为了利用通道间的相关性来训练出真正的scale)。用2个FC/1x1 Conv来实现 ,第一个FC/Conv把C个通道压缩成了C/r个通道来降低计算量,第二个全连接再恢复回C个通道。
Scale:将激励的输出的权重看做是特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。(完成重标定后才算真正的激励)

优点:允许网络进行特征校准(feature recalibration)。通过它,来更多地关注信息丰富的特征,抑制信息少的特征。
原因(个人分析):Squeeze使每个信息都能获得该通道下的全局感受野和响应特征的全局分布,经过Excitation后,每个信息与原来每个通道下feature map的全局相关性更高,Scale的时候原来feature map的每个信息都会被一个全局相关性更高的信息标定,从而实现特征校准。