[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL
Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robotic Wheelchairs
为了训练一个深度神经网络,通常需要一个带有人工标注的地面真值的大规模数据集。然而,生成这样的数据集既费时又费力。为了解决手动贴标耗时耗力的问题。
本文旨在 通过自监督方法自动生成可行驶区域和道路异常的分割标签。
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第1张图片](http://img.e-com-net.com/image/info8/472510277a7f473b9027f3ea4e461e04.jpg)
这个RGB-D相机同时输出RGB图像和深度图像。
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第2张图片](http://img.e-com-net.com/image/info8/603417fab2ea46f2b6c160666f5e2754.jpg)
本文提出一种自监督的方法来分割可行驶区域和道路异常
自动标记RGB的可行驶区域和道路异常
发布数据集
相关工作
自动标注
现阶段有一些方法可以做到自动标注可行驶区域和道路异常。而且很多方法在模拟器端实现,但是本文将两者结合,而且在真车上实现。
本文工作
数据集构建
第一个机器人轮椅常见道路异常的数据集。包含30个常见场景。
作者将常见的道路异常分为两类:距离可行驶区域表面高度大于15cm的大型道路异常;距可行驶区域表面5厘米至15厘米高度的小路面异常。
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第3张图片](http://img.e-com-net.com/image/info8/171b9a56979141b7a1b607fcbb1c4e57.jpg)
上图为数据集的各个标志物的像素点统计,但是本文的算法并不使用这些手工标记的ground-truth,手工标注的ground-truth仅用于评估本文提出的自我监督方法。
其中深度数据有两种 :原始深度数据、归一化的深度数据(0-255)。
RGB-D相机的距离测量范围高达10m。因此,我们移除距离大于10m的像素,并用零值标记它们。至于手工标注的地面真实,我们把未知区域标注为0,可行驶区域标注为1,道路异常标注为2。
本文提出的自监督标签生成器Self-Supervised Label Generator (SSLG)
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第4张图片](http://img.e-com-net.com/image/info8/aa7f070e0cb147e1a52800c05f9cf560.jpg)
真实世界点P(X,Y,Z)在双目图像坐标(U,V)上的投影可以通过下列公式计算
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第5张图片](http://img.e-com-net.com/image/info8/52e05899a48240e19a990e6130e9b64f.jpg)
其中 b b b为两个相机光圈中心的距离,f是焦距,(u0,v0)是图像平面的中心,ul,ur 分别为该点p在两个相机上的投影,θ 是相机的俯仰角,
而视差可以表示为:
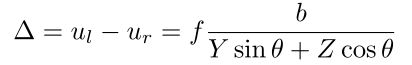
作者认为在大多数情况下,可行驶区域可以视为平面,道路异常也可以近似视为平面。然后,分割问题就可以转化为直线提取问题。
步骤Ⅲ :原始的视差图可以通过计算深度图像中每一行的深度直方图来获得
步骤Ⅳ:由于所计算的v-视差图通常包含许多噪声,所以将高斯二阶导数作为基函数的可控滤波器用于对原始v-视差图进行滤波。再用霍夫变换对过滤后的图像进行直线提取。
步骤Ⅴ:然后过滤一下高度小于5cm的道路异常直线。就可以根据直线检测结果提取出可行驶区域 M D M_D MD和道路异常 D o D_o Do。
原始深度异常图缺乏鲁棒性和准确性,因为代表小道路异常的直线太短,容易与噪声一起被滤除。例如,在示例中有三个道路异常(图3),但是在过滤的v-视差图中只有一条代表道路异常的直线,因此在原始深度异常图中检测到一个道路异常。其他两个小的道路异常(即砖块和路标)与噪音一起被过滤掉。
可以发现在可行驶区域内部有一些孔洞,其中包含了原始深度异常图中缺失的道路异常。因此,我们提取可驱动区域中的孔洞,然后将孔洞检测结果与原始深度异常图相结合,以生成最终的深度异常图Df。
下面介绍RGB图像的道路异常检测。原理是与周围区域颜色不同的区域往往被标记为道路异常。
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第6张图片](http://img.e-com-net.com/image/info8/f0045fa27c314048ab8c70308119d4ba.jpg)
L L L为输入的RGB图像
h , w h,w h,w分别表示图像的高和宽
σ s \sigma_s σs 为超参 这里设置为12.
通过计算每个像素的颜色向量与其高斯模糊结果之间的差值,生成异常图Ro。
步骤 Ⅱ:由于可行驶区域外的干扰,原始的RGB道路异常图不具有鲁棒性和准确性。为了解决这个问题,利用已经生成的可驾驶区域来过滤掉外面的噪音
而最后一步就是根据两个道路异常图和可行驶区域来生成自监督标签。
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第7张图片](http://img.e-com-net.com/image/info8/97cfb2c0cad34727a9689e3938a59416.jpg)

κ \kappa κ为设置的阈值,最终异常图中大于κ的区域在自监督标签中被标记为道路异常。
本文中设置 α \alpha α为0.5 κ \kappa κ为0.3
网络模型的训练
本文使用了三种现成的基于RGB-D数据的语义分割神经网络,FuseNet(ACCV_2016)、 Depth-aware CNN(ECCV_2018) 、RTFNet(RAL_2019)这篇论文也是他们组的工作。
SegNet(PAMI_2017)基于RGB数据的语义分割神经网络
每个网络即在带有SSLG标签的训练集上训练 ,也在带有手动标签的训练集上训练。
实验结果
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第8张图片](http://img.e-com-net.com/image/info8/a6d4bae842de4ead8f73872b9a9489dd.jpg)
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第9张图片](http://img.e-com-net.com/image/info8/15e6689f160542609da98c46b5c717b6.jpg)
评价指标: Pre 表示精度 ,Rec 表示召回率
很明显,在未知区域和可驾驶区域中,与在SSLG标签上训练的SSLG标签相比,在SSLG标签上训练的三个RGB-D网络呈现出一定的改进。至于道路异常,在SSLG标签上训练的三个RGB-D网络与SSLG标签相比表现出显著的改善,这导致在融合网络、深度感知CNN和RTFNet的“全部”列中IoU的明显平均改善分别为16.95%、15.34%和19.93%。
提出的自监督方法之所以比SSLG标签显示出更稳健和更准确的结果,是因为我们提出的SSLG基于这样的直觉,即可驾驶区域和道路异常可以近似地视为平面,这与真实环境略有不同。然而,我们提出的自监督方法能够从大量矛盾的标签中隐含地学习可驾驶区域和道路异常的有用和有效的特征。
当在人工标签上训练时,三个RGB-D网络呈现出更好的性能。
消融性实验也证明了加入深度图的必要。
本文也与其他的自监督方法做了对比,
MaM 2018_AAAI 效果如图5 和表一
可行驶区域的分割的方法对比:2013_IV_ EVD 一种基于增强V-视差图的可行驶区域分割方法
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第10张图片](http://img.e-com-net.com/image/info8/396a32e63f324f199ced4dad839eac11.jpg)
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第11张图片](http://img.e-com-net.com/image/info8/edaa5800d8be4af792ad9994c8801183.jpg)
道路异常分割的方法对比:2014_ECCV NLPR
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第12张图片](http://img.e-com-net.com/image/info8/63e812b9261649a18a5dae5a51747e19.jpg)
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第13张图片](http://img.e-com-net.com/image/info8/d1d80502995047e9b2c73713950449f5.jpg)
但是有时候深度相机返回的深度图可能有大量噪声,作者认为使用更高的深度相机可以解决这个问题。我认为可以考虑使用激光雷达实现更加精准的深度信息检测。
![[论文笔记]Self-Supervised Drivable Area and Road Anomaly Segmentation using RGB-D Data for Robo_2019RAL_第14张图片](http://img.e-com-net.com/image/info8/796fc95d1daf419ab36b47aeb60787b7.jpg)