CenterNet原理详解
CenterNet是在2019年论文Objects as points中提出,相比yolo,ssd,faster_rcnn依靠大量anchor的检测网络,CenterNet是一种anchor-free的目标检测网络,在速度和精度上都比较有优势,值得学习下。
对于CenterNet的理解主要在于四方面:网络结构,heatmap生成,数据增强,loss函数理解。
1. CenterNet网络结构
除了检测任务外,CenterNet还可以用于肢体识别或者3D目标检测等,因此CenterNet论文中提出了三种backbone的网络结构,分别是Resnet-18, DLA-34和Hourglass-104, 三种backbone准确度和速度如下:
-
Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS
-
DLA-34 : 37.4% COCOAP and 52 FPS
-
Hourglass-104 : 45.1% COCOAP and 1.4 FPS
实际工作中我主要用CenterNet进行目标检测,常用Resnet50作为backbone,这里主要介绍resnet50_center_net,其网络结构如下:

可以发现CenterNet网络比较简单,主要包括resnet50提取图片特征,然后是反卷积模块Deconv(三个反卷积)对特征图进行上采样,最后三个分支卷积网络用来预测heatmap, 目标的宽高和目标的中心点坐标。值得注意的是反卷积模块,其包括三个反卷积组,每个组都包括一个3*3的卷积和一个反卷积,每次反卷积都会将特征图尺寸放大一倍,有很多代码中会将反卷积前的3x3的卷积替换为DCNv2(Deformable ConvetNets V2)来提高模型拟合能力。
关于DCN(Deformable ConvetNets)参见:https://zhuanlan.zhihu.com/p/37578271, https://zhuanlan.zhihu.com/p/53127011
CenterNet的模型计算流程如下:
-
图片缩放到512x512尺寸(长边缩放到512,短边补0),随后将缩放后1x3x512x512的图片输入网络
-
图片经过resnet50提取特征得到feature1尺寸为1x2048x16x16
-
feature1经过反卷积模块Deconv,三次上采样得到feature2尺寸为1x64x128x128
-
将feature2分别送入三个分支进行预测,预测heatmap尺寸为1x80x128x128(表示80个类别),预测长宽尺寸为1x2x128x128(2表示长和宽),预测中心点偏移量尺寸为1x2x128x128(2表示x, y)
关于另外两种backbone没有尝试过,以后再写
DLA-34网络即Deep Layer Aggregation, 其理解参见:https://cloud.tencent.com/developer/article/1676834
Hourglass网络主要用于人体姿态估计,其理解参见:https://zhuanlan.zhihu.com/p/45002720
2. heatmap(热力图)理解和生成
2.1 heatmap生成
CenterNet将目标当成一个点来检测,即用目标box的中心点来表示这个目标,预测目标的中心点偏移量(offset),宽高(size)来得到物体实际box,而heatmap则是表示分类信息。每一个类别都有一张heatmap,每一张heatmap上,若某个坐标处有物体目标的中心点,即在该坐标处产生一个keypoint(用高斯圆表示),如下图所示:

产生heatmap的步骤解释如下:
如下图左边是缩放后送入网络的图片,尺寸为512x512,右边是生成的heatmap图,尺寸为128x128(网络最后预测的heatmap尺度为128x128。其步骤如下:
-
1.将目标的box缩放到128x128的尺度上,然后求box的中心点坐标并取整,设为point
-
2.根据目标box大小计算高斯圆的半径,设为R
-
3.在heatmap图上,以point为圆心,半径为R填充高斯函数计算值。(point点处为最大值,沿着半径向外按高斯函数递减)
(注意:由于两个目标都是猫,属于同一类别,所以在同一张heatmap上。若还有一只狗,则狗的keypoint在另外一张heatmap上)

2.2 heatmap高斯函数半径的确定
heatmap上的关键点之所以采用二维高斯核来表示,是由于对于在目标中心点附近的一些点,期预测出来的box和gt_box的IOU可能会大于0.7,不能直接对这些预测值进行惩罚,需要温和一点,所以采用高斯核。借用下大佬们的解释,如下图所示:

关于高斯圆的半径确定,主要还是依赖于目标box的宽高,其计算方法为下图所示。 实际情况中会取IOU=0.7,即下图中的overlap=0.7作为临界值,然后分别计算出三种情况的半径,取最小值作为高斯核的半径r

参考:https://zhuanlan.zhihu.com/p/96856635?utm_source=wechat_session
3. 数据增强
关于CenterNet还有一点值得注意的是其数据增强部分,采用了仿射变换warpAffine,其实就是对原图中进行裁剪,然后缩放到512x512的大小(长边缩放,短边补0)。实际过程中先确定一个中心点,和一个裁剪的长宽,然后进行仿射变换,如下图所示,绿色框住的图片会被裁剪出来,然后缩放到512x512(实际效果见图二中六个子图中第一个)
下面是上图选择不同中心点和长度进行仿射变换得到的样本。除了中心点,裁剪长度,仿射变换还可以设置角度,CenterNet中没有设置角度(代码中为0),是由于加上旋转角度后,gt_box会变的不是很准确,如最右边两个旋转样本
4. loss函数理解
center_net的loss包括三部分,heatmap的loss,目标长宽预测loss,目标中心点偏移值loss。其中heatmap的LK采用改进的focal loss,长宽预测的Lsize和目标中心点偏移Loff都采用L1Loss, 而且Lsize加上了0.1的权重。

heatmap loss
heatmap loss的计算公式如下,对focal loss进行了改写,α和β是超参数,用来均衡难易样本和正负样本。N是图像的关键点数量(正样本个数),用于将所有的positive focal loss标准化为1,求和符号的下标xyc表示所有heatmap上的所有坐标点(c表示目标类别,每个类别一张heatmap),![]() 为预测值,Yxyc为标注真实值。
为预测值,Yxyc为标注真实值。
关于focal loss的理解参考:https://www.cnblogs.com/silence-cho/p/12987476.html , https://zhuanlan.zhihu.com/p/66048276
相比focal loss,负样本的loss里面多了一个(1-Yxyc)β, 是为了抑制0 中心点偏移值损失 Loff损失函数公式如下, 其只对正样本的偏移值损失进行计算。其中 假设图片实际中心点p为(125, 63),由于图片的尺寸为512*512,缩放尺度R=4,因此缩放后的128x128尺寸下中心点坐标为p\R(31.25, 15.75), 相对于整数坐标 长宽预测损失值 损失函数公式如下,也是只对正样本的损失值计算,Spk为预测尺寸,Sk为真实尺寸 参考: https://zhuanlan.zhihu.com/p/96856635?utm_source=wechat_session https://zhuanlan.zhihu.com/p/165313457?utm_source=wechat_session https://zhuanlan.zhihu.com/p/66048276 https://zhuanlan.zhihu.com/p/73516696 
![]() 表示预测的偏移值,p为图片中目标中心点坐标,R为缩放尺度,
表示预测的偏移值,p为图片中目标中心点坐标,R为缩放尺度,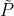 为缩放后中心点的近似整数坐标(31, 15)的偏移值即为(0.25, 0.75), 即(p/R - )
为缩放后中心点的近似整数坐标(31, 15)的偏移值即为(0.25, 0.75), 即(p/R - )
