《人工神经网络》期末复习文档汇总
人工神经网络定义:由许多简单的并行工作的处理单元组成的系统,功能取决于网络的结构、连接强度及个单元处理方式。
人工神经网络基本功能:联想记忆功能、非线性映射功能、分类与识别功能、优化计算功能、知识处理功能。
人工神经网络结构特点:并行处理、分布式存储、可联性、可塑性。
人工神经网络性能特点:非线性、容错性、非精准性。
人工神经网络低潮:求解非线性需要隐层。
人工神经网络复兴:![]() 网络。
网络。
决定人工神经元三要素:节点本身信息处理能力(数学模型)、节点与节点之间连接(拓扑结构)、相互连接强度(通过学习来调整)。
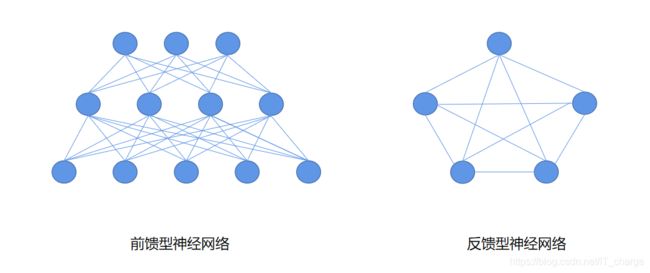
前馈型网络:处理方向:输入层  各隐层 输出层。
各隐层 输出层。
反馈型网络:所有节点都有处理功能,每个节点既可从外界接受输入又可向外界输出。
自组织特征映射网:SOM网、SOFM网、kohonen网
学习向量量化:LVQ
对偶传播神经网络:CPN
径向基函数:RBF
误差反向传播:BP
残差网络:ResNet
长短期记忆神经网络:LSTM
递归神经网络:RNN
卷积神经网络:CNN
![]()
![]() :前馈无监督学习
:前馈无监督学习
感知器:前馈有监督学习
LVQ:前向有监督学习(前两层无监督、最后一层有监督)
MLP、BP、RBF、CNN:前馈网络模型
SOM:无监督学习模型


神经网络学习过程:在外界输入样本刺激下不断改变网络的连接权值乃至拓扑排序,以使网络的输出不能接近期望输出。
神经网络学习本质:对可变权值的动态调整。
神经网络学习规则:![]() 【BP算法是一种学习规则】
【BP算法是一种学习规则】
自组织学习算法步骤:
1、基于k-均值聚类算法求基函数中心
网络初始化
将输入训练样本按K近邻分组
重新调整聚类中心
2、求解方差
3、计算隐含层及输出层权值
循环神经网络
优点:引入记忆、图灵完备
缺点:长程依赖问题、记忆完备问题、并行能力
梯度爆炸问题:权重衰减、梯度截断
梯度消失问题:改进模型
通过使用自带反馈的神经元处理任意长度的序列
Yolov5 用 CIOV Loss 作为 bounding box 损失
Yolov3/Yolov5 用二元交叉熵损失计算类别概率,目标置信度损失
Yolov3 用多个独立逻辑分类器替换 softmax 函数,以计算输入属于特定标签可能性
Yolov3 思想:通过特征提取网络,对输入图像提取特征 将输入图像分 grid cells 目标落在哪个 grid cell 中就用该 grid cell 来预测目标。
Kolonen 学习算法:初始化 接收输入 寻找获胜神经元 定义优胜领域 ![]() 调整权值 结果检验
调整权值 结果检验
LVQ1 算法:网络初始化 输入向量输入 计算隐含层权值向量与输入向量距离 选择与权值向量距离最小的神经元 更新连接权值 判断是否满足最大迭代次数
LVQ2 算法:(1)~(4)与 LVQ1 算法相同 更新连接权值 判断算法结束
CPN 算法:阶段一:内星权随机赋 0~1 初值 归一化 输入 确定竞争获胜神经元 不设优胜领域,只调整内星权向量 直至下降到 0
阶段二:输入 确定竞争获胜神经元 调整外星权向量 下降为 0
(阶段一用竞争学习算法对输入至隐层内星权向量训练,阶段二用外星学习算法对隐层到输出外星权向量判别)
单层感知器局限:只能解决线性可分问题。
解决办法:引入隐层,变为多层感知器(转移函数:非线性连续函数)
判决域:无隐层:半平面;单隐层:凸域;双隐层:任意复杂形状域
AlexNet:5个卷积层,3个汇聚层、3个全连接层
提高网络性能途径:包含隐层的多层前馈网络、非线性连续转移函数
权值调整三因素决定:学习率、本层输出的误差信号、本层输入信号
单层感知器
模型:单计算节点感知器实际上是一个 M-P 神经元模型
功能:解决线性可分问题
局限性:不能解决线性不可分问题
学习算法:有导师学习
多层感知器
模型:有隐层的多层前馈网络
功能:能够求解非线性问题
局限性:隐层神经元的学习规则尚无所知
多层前馈网能力
非线性映射:存储大量输入输出模式映射关系
泛化能力:未见过非样本输入 正确映射
容错能力:误差对输入输出规律影响很小
归一化:原因:物理意义转以同等重要地位
防止净输入过大使神经元输出饱和
不归一化则数值大绝对误差大,反之亦然
方法:尺度变换、分布变换
标准 BP(Sigmoid 激活函数)
输入输出问题 非线性映射问题 梯度下降迭代求权值
两过程:净输出前向计算、误差反向传播
局限性:误差曲面分布:存在平坦区:误差下降慢、大大增加训练次数,影响收敛速度(原因:各节点净输入过大)
存在多个极小点:易陷入局部最小点
根源:基于误差梯度下降的权值调整规则每一步求解都是基于局部最优
改进 BP(Sigmoid 激活函数)
调整:利用算法 权值调整过程‘走’合适路径(跳出平坦区/局部最小点)
操作:进入平坦区 局部最小点进行判断 通过改变参数使权值调整合理
局部最小点进行判断 通过改变参数使权值调整合理
改进:增加动量项:从前一次权值调整量取一部分迭加到本次权值调整量中,动量项反映以前积累的经验,起阻尼作用( 时刻误差梯度下降方向)
时刻误差梯度下降方向)
自适应调节学习率:自适应改变学习率,根据环境增大或减小( 学习率)
学习率)
引入陡度因子:设法压缩神经元的净输入,使输出函数转移函数不饱和区(误差曲面存在平坦区域)
自组织神经网络
通过自动寻找样本中内在规律和本质属性(通过竞争学习实现)
竞争学习:相互竞争以求被激活 每时刻只有一个输出神经元被激活
方法:向量归一化
寻找获胜神经元:竞争层所有神经元对应内星权向量均与输入向量相似性比较,最相似判为竞争获胜神经元
网络输出与权值调整:直至学习率衰减到 
SOM网:有两层:输入 视网膜;输出 大脑皮层
获胜神经元对其邻近神经元影响由近及远(均不同程度调整权向量)
优胜邻域内调整(开始很大,不断调整,最终半径为零)
功能:保序映射(属性相似位置相邻)数据压缩、特征提取
LVQ网:教师信号对输入样本类别进行规定,克服自组织无监督的分类信息弱点(在竞争网络基础上提出【竞争学习思想、有监督学习思想结合】)
三层:输入层、隐含层、输出层(输入与隐含全连接,输出与隐含不同组相连)【隐含与输出权值固定为 】
】
CPN网:运行过程:竞争产生获胜神经节点 获胜节点外星向量决定输出
RBF
单隐层的三层前向网络
两种模型:正规化网络和广义网络
思想:用RBF作隐单元的“基”构成隐含层空间 输入矢量直接映射隐空间 中心点确定后,映射点确定 隐函输出映射是线性的
基函数选 Green 格林函数(高斯函数为特殊的格林函数)
激活函数采用径向基函数
CGAN(条件 GAN)可使 GAN 无监督算法转变为有监督算法
DCGAN 的生成器和判别器舍弃了 CNN 池化层:判别器保留 CNN 整体架构
生成器将卷积层替换为反卷积层
卷积神经网络(卷积层、池化层)
受生物学感受野机制提出
三个特征:局部连接、权重共享、空间和时间上次采样
趋向:小卷积、大深度、全卷积
有多少张输入图片就有多少个卷积核,有多少输出图片就有多少个神经元
结构:输入层
输出层
隐藏层:卷积层:局部特征提取、训练中参数学习、每个卷积核提取特定模式特征
池化层:降低数据维度避免过拟合、增强局部感受野、提高平稳不变性
全连接层:特征提取到分类的桥梁
卷积过程:覆盖、相乘、求和
局部感知:通过底层的局部扫描获得图像局部特征,然后在高层综合这些特征获取图像全局信息
作用:降低参数数目
权值共享:CNN中每个卷积核里面的参数即权值,原始图片卷积后会得到一副新图片,而新图片中的每个像素都来自同一个卷积核
作用:进一步降低参数数目
池化层:旨在通过降低特征图分辨率来获得具有空间不变性特征(二次提取特征)
作用:减少参数数量:提高计算效率
提高局部平移不变性:大大提高图像分类准确性
降低数据维度:有效避免过拟合
增强网络对输入图像中的小变形、扭曲、平坦的鲁棒性
反向传播:结构:求出结果与期望误差,一层一层返回,计算每层误差,进行权值调整
Why?输入 输出(卷积层、池化层、全连接层),传递产生数据损失,误差产生
