神经网络训练过程中出现loss为nan,神经元坏死
最近在手撸Tensorflow2版本的Faster RCNN模型,稍后会进行整理。但在准备好了模型和训练数据之后的训练环节中出现了大岔子,即训练过程中loss变为nan。nan表示not a number类型,任意有关nan的运算结果都将得到nan。这可真是一颗老鼠屎坏了一锅粥,一但一个step中出现loss为nan,所有神经元的参数都将被更新为nan,之后的epochs和step中所有预测结果和模型参数都将为nan。
为了弄清楚nan的原因,我检查了每个组件函数以及所用的训练数据是否有误,结果显示都是没问题的。怀疑参数设置,怀疑模型流程写错了.....在大量debug之后,终于找到了症结所在。
1、为什么会出现nan?
nan在数学表示上表示一个无法表示的数,一般表示一个非浮点数(比如无理数)。inf不同于nan,inf是一个超过浮点表示范围的浮点数,其本质仍然是一个数,只是他为无穷大。
在numpy数组中,这些计算会产生nan的结果:
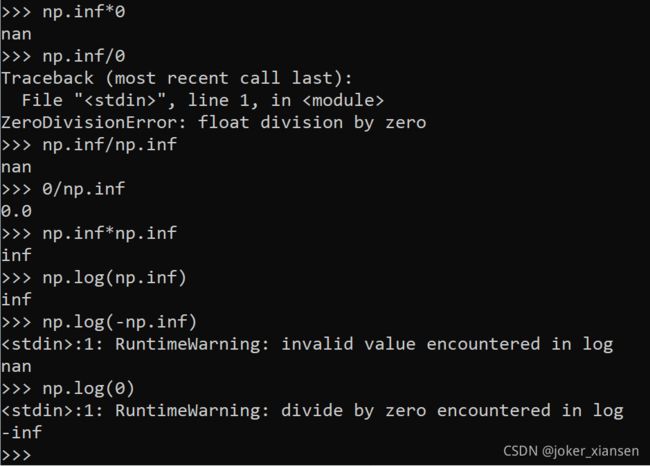
仔细debug整个训练过程, 用如下代码段捕获nan的出现(因为在python中nan不会报错)
import numpy as np
if np.any(np.isnan(contents)):
print('contents contain nan')如上一步所见,如果某个数做除0运算,python中将会报出除零错误,但在tensorflow中,除0是不会报错的,只会以结果nan继续运算,nan是一个不可表示的浮点数。这就是为什么会出现nan。
import tensorflow as tf
if __name__ == '__main__':
# main()
tensor = tf.constant([0.])
res = tensor/0.
result = tf.reduce_mean(res)
print(result)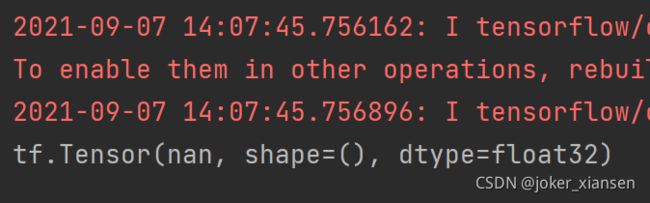
2、Faster RCNN为啥会出现nan loss?
经过捕获,在某张目标物体位于边缘的输入图像step中出现loss为nan的情况。而且这张图像在输入经过anchor encode处理后,所得到的target_boxes, target_scores元素全为0,target_masks中元素全部为-1和0。这意味着模型在encode这张图像时,因为目标物体处于边缘,且尺寸很小,与先验框的尺寸相差较大,导致与之交并比大于positive_threshold的先验框容易超出图像边缘而被滤除,与之交并比小于negetive_threshold的先验框被记为负,未检测到物体。因此target_boxes, target_scores也就全部为0了。


举个例子来说,我们想要检测图片中的主子的头,而样本中存在主子耳朵位于边缘的样本,相比于猫头,猫耳朵的尺寸较小。并且样本中更多的猫头,所以在聚类生成先验anchor时,anchor的尺寸会更接近猫头的尺寸,也就是anchor尺寸较大。在encode输入图像时,就会出现上面的标记检测不到物体的情况。
在计算loss时,分为两部分,预测框得分损失以及预测框坐标损失。score_loss计算过程中并不会出现nan,因为foreground_background_mask不可能全为0。而boxes_loss计算过程中,只考虑那些标记为正样本的anchor框的损失,因此foreground_mask就可能出现全为0的情况,在经过求平均过程的除操作就会产生nan,从而造成整个网络坏死。
import tensorflow as tf
score_loss = tf.nn.softmax_cross_entropy_with_logits(labels=target_scores, logits=pred_scores)
foreground_background_mask = (np.abs(target_masks) == 1).astype(np.int32)
score_loss = tf.reduce_sum(score_loss * foreground_background_mask, axis=[1,2,3]) / np.sum(foreground_background_mask)
score_loss = tf.reduce_mean(score_loss)
boxes_loss = tf.abs(target_bboxes - pred_bboxes)
boxes_loss = 0.5 * tf.pow(boxes_loss, 2) * tf.cast(boxes_loss<1, tf.float32) + (boxes_loss - 0.5) * tf.cast(boxes_loss >=1, tf.float32)
boxes_loss = tf.reduce_sum(boxes_loss, axis=-1)
foreground_mask = (target_masks > 0).astype(np.float32)
boxes_loss = tf.reduce_sum(boxes_loss * foreground_mask, axis=[1,2,3]) / np.sum(foreground_mask)
boxes_loss = tf.reduce_mean(boxes_loss)3、解决方法
思路:
(1)损失截断
捕获nan出现的loss,用0或者一个极小值去替换nan,进行后续的反向传播。相当于此张图像贡献的损失极小接近0,而对模型的参数的调整贡献也极小,并且不会造成网络的坏死。
(2)数据替换
将原训练数据集中的目标处于边缘的图像和空图像进行滤除
(3)聚类生成更接近标注框尺寸的先验框,并将encode输入图像过程中的判断anchor位于图像内的范围扩大。
(4)损失函数改造
总结:被这个bug折磨了好久,也拜它所赐,debug过程中更深入学习Faster RCNN的细节。解决方法只是发现bug后想到的,具体效果等后续训练测试啦。
学疏才浅,欢迎指正。