窗口函数简介与总结
目录
什么是窗口函数
窗口函数的实现原理
窗口函数使用场景
常用的窗口函数有:
1. 窗口排序函数:ROW_NUMBER()、RANK()、DENSE_RANK();
2. 窗口聚合函数:SUM()、MIN()、MAX()、AVG();
3. LAG()
4. LEAD()
5. FIRST_VALUE()
6. LAST_VALUE()
7. NTILE()
什么是窗口函数
窗口函数是 SQL 中一类特别的函数。和聚合函数相似,窗口函数的输入也是多行记录。不 同的是,聚合函数的作用于由 GROUP BY 子句聚合的组,而窗口函数则作用于一个窗口, 这里,窗口是由一个 OVER 子句 定义的多行记录。聚合函数对其所作用的每一组记录输 出一条结果,而窗口函数对其所作用的窗口中的每一行记录输出一条结果。一些聚合函 数,如 sum, max, min, avg,count 等也可以当作窗口函数使用。
窗口函数的实现原理
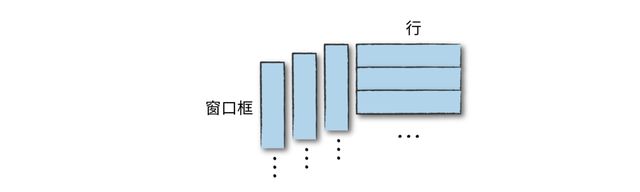
在用group-by处理数据分组时,每一行只能进入一个分组。窗口函数基于称为框(f r a m e)的一组行,计算表的每一输入行的返回值,每一行可以属于一个或多个框。常见用例就是查看某些值的滚动平均值,其中每一行代表一天,那么每行属于7个不同的框。
如下图所示,每一行是如何匹配多个窗口框的。
窗口函数使用场景
分组排序,如取某年级每个班学习成绩排名前10的学生。分组聚合基本语法
窗口函数的语法分为四个部分:
函数子句:指明具体操作,如sum-求和,first_value-取第一个值;partition by子句:指明分区字段,如果没有,则将所有数据作为一个分区;order by子句:指明了每个分区排序的字段和方式,也是可选的,没有就是按照表中的顺序;窗口子句:指明相对当前记录的计算范围,可以向上(preceding),可以向下(following),也可以使用between指明,上下边界的值,没有的话默认为当前分区。ROWS BETWEEN,也叫做window子句数字+PRECEDING 向前n条数字+FOLLOWING 向后n条CURRENT ROW 当前行UNBOUNDED 无边界,表示从最前面的起点开始,表示到最后面的终点UNBOUNDED PRECEDING 向前无边界UNBOUNDED FOLLOWING 向后无边界窗口函数有哪些
窗口函数的功能分为:聚合、取值、排名、序列四种,前三种的使用场景比较常见,容易理解,最后一种(序列)的使用场景比较少。
聚合count 统计条数sum 求和avg 求平均值max 求最大值min 求最小值取值first_value 取窗口中的第一值last_value 取窗口中的最后一个值lag(col, n, DEFAULT) 用于统计窗口内向上第n行的值col :列名n:向上n行,[可选,默认为1]DEFAULT :当向上n行为NULL时,取默认值;如果不指定,则为NULLlead(col, n, DEFAULT) 用于统计窗口内向下第n行的值,和lag相反col :列名n:向下n行,[可选,默认为1]DEFAULT :当向上n行为NULL时,取默认值;如果不指定,则为NULL排序rank 排序,有相同分数,排名相同并对后续跳过,如分数5,5,8,9,则得到的结果未1,1,3,4dense_rank 排序,有相同的分数排名相同,但后续接上,如分数5,5,8,9,则得到的排序结果未1,1,2,3、row_number 排序,相同分数按先来后到排序,无重复排序,如分数5,5,8,9,得到的结果为1,2,3,4ntitle其他cume_dist 小于等于当前值的行数/分组内总行数比如,统计小于等于当前薪水的人数,所占总人数的比例percent_rank 计算给定行的百分比排名。分组内当前行的RANK值-1/分组内总行数-1,可以用来计算超过了百分之多少的人。ntile(n) 将分区中的数据按照顺序划分为N片,返回当前片的值。注1:如果切片分布不均匀,默认增加第一个切片的分布注2:不支持rows between
在构建数据仓库或者进行数据分析时,难免会使用Hive中的窗口函数完成一些较复杂的ETL工作,现对Hive中常用的窗口函数进行总结与记录。
在Hive中,一般会使用窗口函数生成新的一列,使用样式为:
select 字段1, 字段2,..., window_function() over(partition by 字段1 order by 字段2 ) as 新字段1 from 表1 where ......常用的窗口函数有:
1. 窗口排序函数:ROW_NUMBER()、RANK()、DENSE_RANK();
基于上文中的使用样式,窗口排序函数是先根据字段1进行分组,组内根据字段2进行升序排序或降序排序,然后新生成的一列为排序的序号,三个排序函数之间有一些区别如下。
- ROW_NUMBER()函数,生成的排序序号从1开始,按照顺序,生成分组内记录的序号,不存在相同序号。
- RANK()函数,生成的排序序号从1开始,字段2数值相同的行,序号相同,且会在排序序号中留下空位。
- DENSE_RANK()函数,生成的排序序号从1开始,对于字段2数值相同的行,序号相同,但在排序序号中不会留下空位。
2. 窗口聚合函数:SUM()、MIN()、MAX()、AVG();
窗口聚合函数可以搭配窗口子句使用, 如:
select 字段1,字段2, ..., sum(字段3) over( partition by 字段1 order by 字段2 rows between unbounded preceding and current row) as 新字段1
// 新字段1含义为计算当前分组中,从第一行到当前行字段3的和。其中ROWS BETWEEN叫窗口子句, 其中CURRENT ROW表示当前行,UNBOUNDED PRECEDING表示前面的起点,UNBOUNDED FOLLOWING表示后面的终点,当没有写窗口子句时,语义为从第一行到当前行。
MIN()、MAX()、AVG()的用法与SUM()一样。
3. LAG()
LAG(col,n,DEFAULT) 用于取窗口内列col往前第N行的值,其中第一个参数为列名,第二个参数表示往前取n行(可选,默认为1),第三个参数为默认值(当列col往前第n行为NULL时,取该默认值,如不指定,则为NULL)。
4. LEAD()
LEAD(col, n, DEFAULT) 与函数LAG类似,不过取数方向相反,用于去窗口内列col往后第n行的值,其中第一个参数为列名,第二个参数表示往后取n行(可选,默认为1),第三个参数为默认值(即当列col往后取n行为NULL时,取该默认值,若不指定,则为NULL)。
5. FIRST_VALUE()
用法:FIRST_VALUE(col), 表示分组排序后,截止到当前行排名第一的那一行对应的列col的值。
6. LAST_VALUE()
用法:LAST_VALUE(col),表示分组排序后,截止到当前行排名最后一名的那一行对应的列col的值。
7. NTILE()
NTILE函数的作用是,对数据分组排序后,将有序的数据平均分配到指定数量的桶中,即给每一行一个桶的编号。用法:NTILE(n) OVER(PARTITION BY 字段1 ORDER BY 字段2)。基于此,可以在查询结果的外面再嵌套一层查询语句,这样就可以过滤出排序之后的前N分之几或者后N分之几的数据,达到数据抽样的效果。