NNDL 实验七 循环神经网络(2)梯度爆炸实验
目录
梯度爆炸试验
梯度打印函数
思考
复现梯度爆炸现象
使用梯度截断解决梯度爆炸问题
思考
总结
参考
梯度爆炸试验
造成简单循环网络较难建模长程依赖问题的原因有两个:梯度爆炸和梯度消失。
梯度爆炸问题:比较容易解决,一般通过权重衰减或梯度截断可以较好地来避免;
梯度消失问题:更加有效的方式是改变模型,比如通过长短期记忆网络LSTM来进行缓解。
本节将首先进行复现简单循环网络中的梯度爆炸问题,然后尝试使用梯度截断的方式进行解决。
采用长度为20的数据集进行实验,训练过程中将进行输出W,U,b的梯度向量的范数,以此来衡量梯度的变化情况。
梯度打印函数
在训练过程中打印梯度,使用custtom_print_log实现了在训练过程中打印梯度的功能,分别定义W_list, U_list和b_list,用于分别存储训练过程中参数W,U和b的梯度范数。
导入函数库:
import os
import torch
import random
import numpy as np
from torch.utils.data import DataLoader代码实现:
W_list = []
U_list = []
b_list = []
# 计算梯度范数
def custom_print_log(runner):
model = runner.model
W_grad_l2, U_grad_l2, b_grad_l2 = 0, 0, 0
for name, param in model.named_parameters():
if name == "rnn_model.W":
W_grad_l2 = torch.norm(param.grad, p=2).numpy()
if name == "rnn_model.U":
U_grad_l2 = torch.norm(param.grad, p=2).numpy()
if name == "rnn_model.b":
b_grad_l2 = torch.norm(param.grad, p=2).numpy()
print(f"[Training] W_grad_l2: {W_grad_l2:.5f}, U_grad_l2: {U_grad_l2:.5f}, b_grad_l2: {b_grad_l2:.5f} ")
W_list.append(W_grad_l2)
U_list.append(U_grad_l2)
b_list.append(b_grad_l2)思考
什么是范数,什么是L2范数,这里为什么要打印梯度范数?
范数,是具有“长度”概念的函数。在线性代数、泛函分析及相关的数学领域,范数是一个函数,是矢量空间内的所有矢量赋予非零的正长度或大小。半范数可以为非零的矢量赋予零长度。
定义范数的矢量空间是赋范矢量空间;同样,定义半范数的矢量空间就是赋半范矢量空间。
L1范数是指向量中各个元素绝对值之和;
L2范数定义为向量所有元素的平方和的开平方
为什么要打印梯度范数:
函数在某一点处的方向导数在其梯度方向上达到最大值,此最大值即梯度的范数。 而模型的学习过程是通过使用训练数据来最小化损失函数,从而确定参数的值。而最小化损失函数,即通过求导求损失函数的极值。“梯度下降通常不会到达任何形式的临界点”,意思是用梯度下降不可能完全优化到极小点,只能在极小点附近徘徊,而极小点附近恰恰是梯度较大的区域(例如一个凹下去的“坑”),所以在训练时梯度范数增加。通过打印梯度范数观察梯度变化趋势,来更好地进行模型训练。
复现梯度爆炸现象
为了更好地复现梯度爆炸问题,使用SGD优化器将批大小和学习率调大,学习率为0.2,同时在计算交叉熵损失时,将reduction设置为sum,表示将损失进行累加。
np.random.seed(0)
random.seed(0)
torch.manual_seed(0)
# 训练轮次
num_epochs = 50
# 学习率
lr = 0.2
# 输入数字的类别数
num_digits = 10
# 将数字映射为向量的维度
input_size = 32
# 隐状态向量的维度
hidden_size = 32
# 预测数字的类别数
num_classes = 19
# 批大小
batch_size = 64
# 模型保存目录
save_dir = "./checkpoints"
# 可以设置不同的length进行不同长度数据的预测实验
length = 20
print(f"\n====> Training SRN with data of length {length}.")
# 加载长度为length的数据
data_path = f"D:/datasets/{length}"
train_examples, dev_examples, test_examples = load_data(data_path)
train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples),DigitSumDataset(test_examples)
train_loader = DataLoader(train_set, batch_size=batch_size)
dev_loader = DataLoader(dev_set, batch_size=batch_size)
test_loader = DataLoader(test_set, batch_size=batch_size)
# 实例化模型
base_model = SRN(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 指定优化器
optimizer = torch.optim.SGD(model.parameters(),lr)
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss(reduction="sum")
# 基于以上组件,实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 进行模型训练
model_save_path = os.path.join(save_dir, f"srn_explosion_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=1,
save_path=model_save_path, custom_print_log=custom_print_log)
训练结果:

这里需要使用到RunnerV3类以及准确率函数
class Accuracy():
def __init__(self):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = True
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, axis=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.can_cast((outputs >= 0), dtype=torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.can_cast((outputs >= 0.5), dtype=torch.float32)
else:
# 多分类时,使用'paddle.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1).int()
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
X = X.cuda()
y = y.cuda()
# 获取模型预测
logits = self.model(X)
logits = logits.cuda()
y = y.to(dtype=torch.int64)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
X = X.cuda()
y = y.cuda()
# 计算模型输出
logits = self.model(X)
logits = logits.cuda()
# 计算损失函数
y = y.to(dtype=torch.int64)
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)接下来,可以获取训练过程中关于W,U和b参数梯度的L2范数,并将其绘制为图片以便展示,相应代码如下:
def plot_grad(W_list, U_list, b_list, save_path, keep_steps=40):
# 开始绘制图片
plt.figure()
# 默认保留前40步的结果
steps = list(range(keep_steps))
plt.plot(steps, W_list[:keep_steps], "r-", color="#8E004D", label="W_grad_l2")
plt.plot(steps, U_list[:keep_steps], "-.", color="#E20079", label="U_grad_l2")
plt.plot(steps, b_list[:keep_steps], "--", color="#3D3D3F", label="b_grad_l2")
plt.xlabel("step")
plt.ylabel("L2 Norm")
plt.legend(loc="upper right")
plt.savefig(save_path)
print("image has been saved to: ", save_path)
save_path = f"./images/6.8.pdf"
plot_grad(W_list, U_list, b_list, save_path)运行结果:

上图展示了在训练过程中关于W,U和b参数梯度的L2范数,可以看到经过学习率等方式的调整,梯度范数急剧变大,而后梯度范数几乎为0. 这是因为Tanh为Sigmoid型函数,其饱和区的导数接近于0,由于梯度的急剧变化,参数数值变的较大或较小,容易落入梯度饱和区,导致梯度为0,模型很难继续训练.
接下来,使用该模型在测试集上进行测试。
print(f"Evaluate SRN with data length {length}.")
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"srn_explosion_model_{length}.pdparams")
runner.load_model(model_path)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
print(f"[SRN] length:{length}, Score: {score: .5f}")
Evaluate SRN with data length 20.
[SRN] length: 20,Score: 0.08000.
使用梯度截断解决梯度爆炸问题
梯度截断是一种可以有效解决梯度爆炸问题的启发式方法,当梯度的模大于一定阈值时,就将它截断成为一个较小的数。一般有两种截断方式:按值截断和按模截断.本实验使用按模截断的方式解决梯度爆炸问题。
按模截断是按照梯度向量g的模进行截断,保证梯度向量的模值不大于阈值b,裁剪后的梯度为:
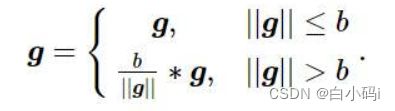
当梯度向量g的模不大于阈值b时,g数值不变,否则对g进行数值缩放。
在引入梯度截断之后,将重新观察模型的训练情况。这里我们重新实例化一下:模型和优化器,然后组装runner,进行训练。代码实现如下:
# 清空梯度列表
W_list.clear()
U_list.clear()
b_list.clear()
# 实例化模型
base_model = SRN(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 定义clip,并实例化优化器
clip = nn.ClipGradByNorm(clip_norm=5.0)
optimizer = paddle.optimizer.SGD(learning_rate=lr, parameters=model.parameters(), grad_clip=clip)
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss(reduction="sum")
# 实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 训练模型
model_save_path = os.path.join(save_dir, f"srn_fix_explosion_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=1, save_path=model_save_path, custom_print_log=custom_print_log)在引入梯度截断后,获取训练过程中关于W,U和b参数梯度的L2范数,并将其绘制为图片以便展示,相应代码如下:
save_path = f"./images/6.9.pdf"
plot_grad(W_list, U_list, b_list, save_path, keep_steps=100)

上图展示了引入按模截断的策略之后,模型训练时参数梯度的变化情况。可以看到,随着迭代步骤的进行,梯度始终保持在一个有值的状态,表明按模截断能够很好地解决梯度爆炸的问题.
接下来,使用梯度截断策略的模型在测试集上进行测试。
print(f"Evaluate SRN with data length {length}.")
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"srn_fix_explosion_model_{length}.pdparams")
runner.load_model(model_path)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
print(f"[SRN] length:{length}, Score: {score: .5f}")
Evaluate SRN with data length 20.
[SRN] length: 20,Score: 0.18000.
由于为复现梯度爆炸现象,改变了学习率,优化器等,因此准确率相对比较低。但由于采用梯度截断策略后,在后续训练过程中,模型参数能够被更新优化,因此准确率有一定的提升。
思考
梯度截断解决梯度爆炸问题的原理是什么?
梯度截断,也就是设定阈值,当预更新的梯度小于阈值时,那么将预更新的梯度设置为阈值。梯度截断通常发送在,损失函数反向传播计算完之后,优化器梯度更新之前。在 pytorch 中通过处理clip_grad_norm方法来实现。
总的来说就是通过设置阈值去解决梯度爆炸,比如说按值截断,就是比较简单粗暴,由于梯度太大会产生梯度爆炸的现象,太小会产生梯度消失的现象(参数不更新),所以为梯度提供一个范围[a,b]:
- 如果梯度大于b,就把它设置为b;
- 如果梯度小于a,就把它设置为a;
- 若在此区间,不做变化
还有按模截断等等。
总结
这次实验觉得新名词比较多,先是了解了一下梯度范数(这个可能也不算新名词,只是给了一个专业的名词来解释)。然后动手实践一个梯度爆炸问题通过梯度截断来解决它,最后思考题查资料的时候,还了解到了梯度剪裁,两者对参数的处理方法有所不同,但它们的作用都是用来处理梯度爆炸问题。
参考
NNDL 实验七 循环神经网络(2)梯度爆炸实验
NNDL 实验6(上) - HBU_DAVID - 博客园 (cnblogs.com)